一、 万物分割
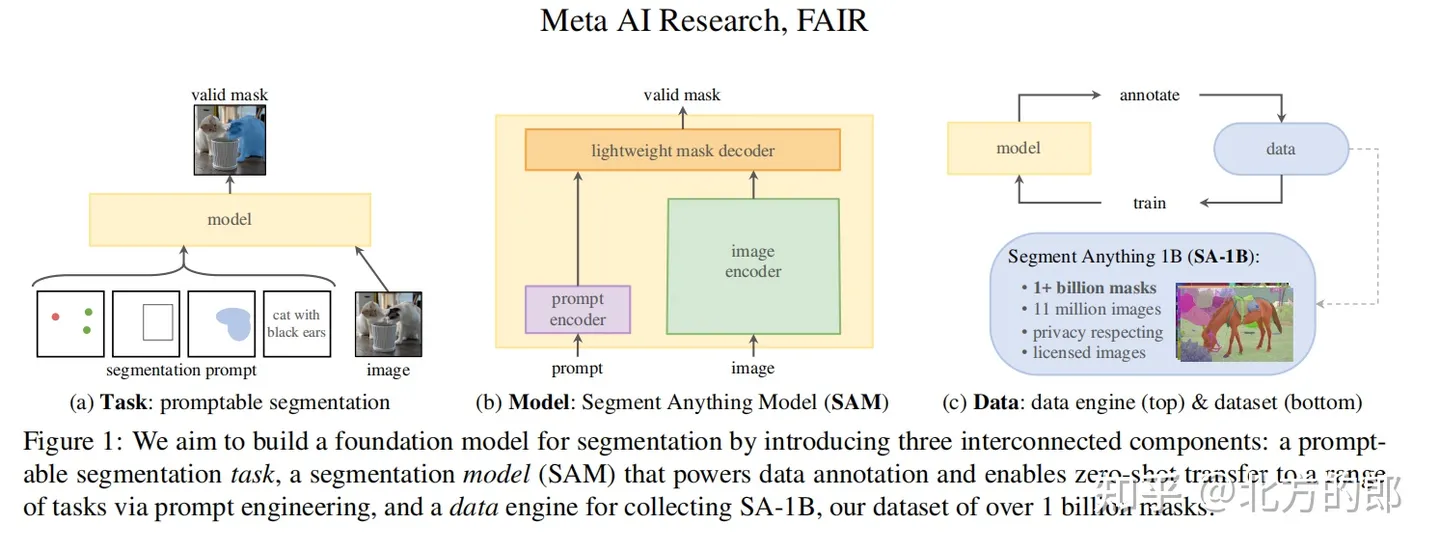
随着Meta发布的Segment Anything Model (万物分割)的论文并开源了相关的算法,我们可以从中看到,SAM与GPT-4类似,这篇论文的目标是(零样本)分割一切,将自然语言处理(NLP)的提示范式引入了计算机视觉(CV)领域,为CV基础模型提供了更广泛的支持和深度研究的机会。
Segment Anything与传统的图像分割有两个很大的区别:
1、数据收集和主动学习的方式。
对于一个庞大的数据集,例如包含十亿组数据的情况,标注全部数据几乎是不可行的。因此,一个解决方案是采用主动学习的方法。这种方法可以分为以下步骤:
初步标注: 首先,对数据集的一部分进行手动标注。这可以是一个小样本,但应涵盖多种情况和类别,以确保模型获得足够的多样性。
半监督学习: 接下来,使用已标注的数据来训练一个初始模型。这个模型可以用来预测未标注数据的标签。
人工校验与修正: 模型生成的预测标签需要经过人工校验和修正,以确保其准确性。这可以通过专业人员或者众包的方式来完成。
迭代循环: 重复上述步骤,逐渐扩展已标注数据的数量。每次迭代都会提高模型的性能,因为它可以在更多数据上进行训练。
通过这种方式,可以逐步提高数据集的标注质量,而不需要手动标注所有数据。当数据集足够大并且模型被训练到一定程度时,其性能将会显著提升。
2. prompt
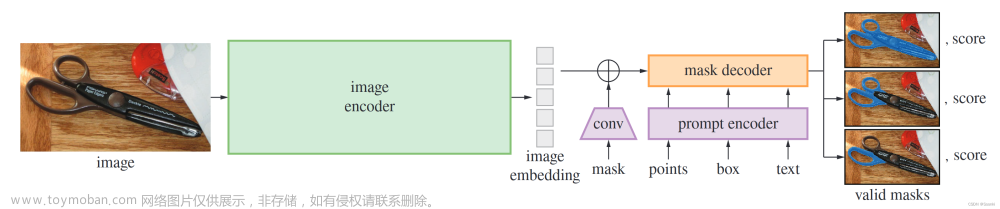
Segment Anything 引入了prompt的概念。Prompt是一种用户输入的提示,用于引导模型生成特定类型的回复。这在像GPT-3和SAM这样的模型中非常有用。用户可以提供一个问题或者描述,以帮助模型理解其意图并生成相关的回答或操作。
例如,在SAM中,你可以输入一个提示词,如“Cat”或“Dog”,以告诉模型你希望它分割出照片中的猫或狗。模型将自动检测并绘制框,以实现分割。这个提示词可以用来限定模型的任务,使其更专注于特定的信息提取或操作。
这两个概念都是在处理大规模数据和提高模型性能方面非常重要的工程性工作。通过合理的数据收集和主动学习策略,以及通过引导模型的prompt,可以更好地满足用户需求,提高模型的效果,并逐步改进模型的性能。
二、Segment-and-Track Anything
1、算法简介
SAM的出现统一了分割这个任务很多应用,也表明了在CV领域可能存在大规模模型的潜力。这一突破肯定会对CV领域的研究带来重大变革,许多任务将得到统一处理。这一新的数据集和范式结合了超强的零样本泛化能力,将对CV领域产生深远影响。但缺乏对视频数据的支持。随后,浙江大学ReLER实验室的科研人员在最新开源的SAM-Track项目其中,解锁了SAM的视频分割能力,即:分割并跟踪一切(Segment-and-track anything,SAM-track)。SAM-Track在单卡上即可支持各种时空场景中的目标分割和跟踪,包括街景、AR、细胞、动画、航拍等,可同时追踪超过200个物体,为用户提供了强大的视频编辑能力。“Segment and Track Anything” 利用自动和交互式方法。主要使用的算法包括 SAM(Segment Anything Models)用于自动/交互式关键帧分割,以及 DeAOT(Decoupling features in Associating Objects with Transformers)(NeurIPS2022)用于高效的多目标跟踪和传播。SAM-Track 管道实现了 SAM 的动态自动检测和分割新物体,而 DeAOT 负责跟踪所有识别到的物体。
2、项目特点
自动/交互式分割:项目中的 SAM(Segment Anything Models)算法提供了自动和交互式关键帧分割的功能。通过 SAM,用户可以选择使用自动分割算法或与算法进行交互,以实现对视频中任意对象的精确分割。这种灵活性使得该项目适用于不同需求的应用场景。
高效多目标跟踪:Segment-and-Track-Anything 还引入了 DeAOT 算法,用于实现高效的多目标跟踪和传播。DeAOT 利用先进的跟踪技术,能够准确地跟踪视频中的多个对象,并支持对象之间的传播和关联。这使得项目在处理复杂场景和多目标跟踪任务时表现出色。
独立和开放性:该项目是一个独立的开源项目,可以直接访问和使用。它提供了丰富的文档和示例代码,帮助用户快速上手并进行定制开发。同时,项目欢迎社区的贡献和扩展,这使得用户能够与其他研究者和开发者共享经验和成果。
应用广泛性:Segment-and-Track-Anything 的分割和跟踪功能可以应用于各种视频分析任务,包括视频监控、智能交通、行为分析等。它为研究者和开发者提供了一个强大的工具,用于处理和分析具有复杂动态场景的视频数据。
三、项目部署
项目地址:https://github.com/z-x-yang/Segment-and-Track-Anything
1.部署环境
我这里测试部署的系统win 10, cuda 11.8,cudnn 8.5,GPU是RTX 3060, 8G显存,使用conda创建虚拟环境。
创建并激活一个虚拟环境:
conda create -n sta python==3.10
activate sta
下载项目:
git clone https://github.com/z-x-yang/Segment-and-Track-Anything.git
cd Segment-and-Track-Anything
pip install gradio
pip install scikit-image
因为要使用GPU,这里单独安装pytorch:
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
因为项目的依赖要使用sh脚本进行安装,win下不支持bash,所以要单独安装m2-base:
conda install m2-base
安装项目依赖:
bash script/install.sh
当出现下面提示代表安装成功。
GroundingDINO可能会安装不成功,可以直接从源码安装:
git clone https://github.com/IDEA-Research/GroundingDINO.git
cd GroundingDINO/
pip install -e .
cd ..
下载所需模型:
bash script/download_ckpt.sh
如果模型下载不成功,也可以手动复制这个地址把模型下载了放到指定目录目录.
2.运行项目
python app.py
然后打开http://127.0.0.1:7860/
导入一个视频,然后只追踪其中一个人,效果如下:
视频目标追踪:文章来源:https://www.toymoban.com/news/detail-763035.html
目标分割与目标追踪文章来源地址https://www.toymoban.com/news/detail-763035.html
3.分割与追踪处理代码
import sys
sys.path.append("..")
sys.path.append("./sam")
from sam.segment_anything import sam_model_registry, SamAutomaticMaskGenerator
from aot_tracker import get_aot
import numpy as np
from tool.segmentor import Segmentor
from tool.detector import Detector
from tool.transfer_tools import draw_outline, draw_points
import cv2
from seg_track_anything import draw_mask
class SegTracker():
def __init__(self,segtracker_args, sam_args, aot_args) -> None:
"""
Initialize SAM and AOT.
"""
self.sam = Segmentor(sam_args)
self.tracker = get_aot(aot_args)
self.detector = Detector(self.sam.device)
self到了这里,关于Segment-and-Track Anything——通用智能视频分割、目标追踪、编辑算法解读与源码部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!