前几天看了一篇由清华大学发表的融合卷积与自注意力机制的文章,其中将融合模块称为 ACMix。本文主要就其中的融合细节进行讲述。
paper:http://arxiv.org/abs/2111.14556
code:https://github.com/LeapLabTHU/ACmix
\quad
介绍(文章贡献)
有两个方面:(1) 揭示了自注意力和卷积之间的强大潜在关系,为理解两个模块之间的联系提供了新的视角,并为设计新的学习范式提供了灵感。 (2) 提出了自注意力和卷积模块的优雅集成,它享有两个世界的好处。经验证据表明,混合模型始终优于其纯卷积或自注意力模型。
\quad
相关工作
这部分主要针对 Self-Attention only、Attention enhanced Convolution、Convolution enhanced Attention 的不同现有网络进行了介绍,感兴趣的可以看看原文。
\quad
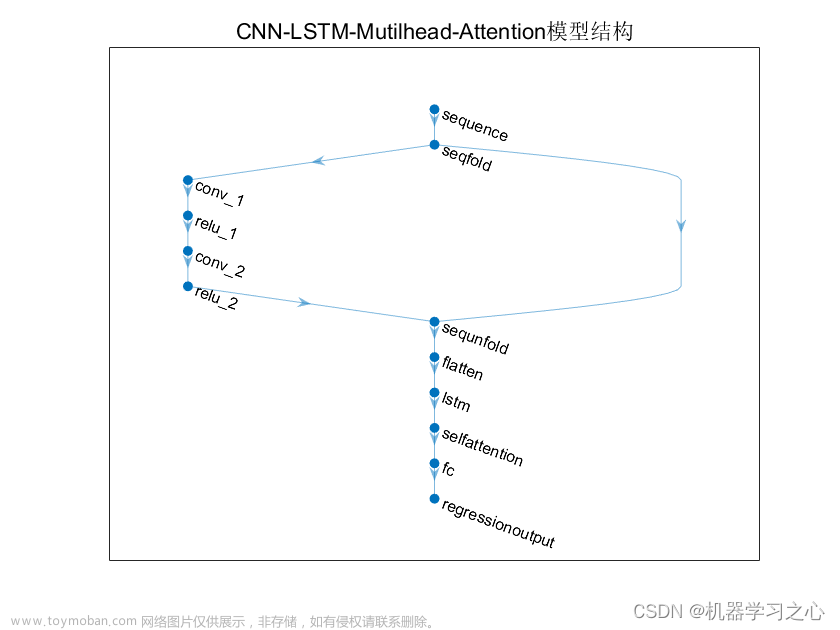
方法
回顾 Convolution

上图所示是一个3x3的卷积核对一个6x6大小的特征图
f
i
n
f_{in}
fin进行卷积,实现方式就是用该卷积核在特征图上滑动,将特征图核原图重叠的像素块进行乘积,然后进行加和得到输出特征图
f
o
u
t
f_{out}
fout对应像素的值。
\quad
因此标准卷积层的理论计算可以定义如下,即输出卷积图中 ( i , j ) (i,j) (i,j)像素点的值是卷积核与前一层特征图的乘积加和,如下

为了方便可以重写为


为了进一步简化,定义
S
h
i
f
t
Shift
Shift 算子

\quad
依照ACMix论文,我们完全可以换一下上面的逻辑,卷积就可以抽象成两个阶段:
-
阶段一:先用卷积核的中的一个 pixel 生成整个特征图,比如就考虑 3x3 卷积核的左上角像素,和前一张特征图做卷积,得到只属于该卷积核像素的特征图

-
阶段二:在我们获取输出特征图的时候,我们如果要求在 ( i , j ) (i,j) (i,j)像素的输出特征图的值,就直接提取每张卷积核特征图对应偏移量的像素值,然后进行加和

\quad
回顾 Self-Attention
总计算式子如下,即想要求
(
i
,
j
)
(i,j)
(i,j)像素的输出特征图的值,则需要当前
(
i
,
j
)
(i,j)
(i,j)像素的特征 ,与其周围区域
,与其周围区域
内其他特征进行权重计算
,然后再用权重求和


拆分成两阶段
ACMix
ACMix 合并 convolution 和 self-attention 的共有模块,首先在第一阶段先用1x1的卷积核扩充通道,生成 ( q , k , v ) (q,k,v) (q,k,v),而这将被第二阶段共用。
- 卷积分支:这里并不考虑将 ( q , k , v ) (q,k,v) (q,k,v)分开看待,而是concat之后一起输入到全连接层。根据上面卷积重写的思想,先生成每个卷积核像素对应的特征图,如大小为 k k k的卷积核就有 k 2 k^2 k2个特征图,然后再通过 S h i f t Shift Shift 算子去融合特征图的输出
- 自注意力分支:直接就是正常的自注意力机制计算
最后将 convolution 和 self-attention 获得的特征通过超参数
α
、
β
\alpha、\beta
α、β进行加权融合,得到最终的特征图
\quad
S h i f t Shift Shift 算子的实现
作者是采用了卷积核不同位置设为1的常量进行初始化,然后通过 depth-wise convolution 实现。 文章来源:https://www.toymoban.com/news/detail-763235.html
文章来源:https://www.toymoban.com/news/detail-763235.html
更多细节请看源码和原文。
paper:http://arxiv.org/abs/2111.14556
code:https://github.com/LeapLabTHU/ACmix文章来源地址https://www.toymoban.com/news/detail-763235.html
到了这里,关于ACMix:清华提出融合卷积与自注意力机制的模块的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!