怎么把文件放到hdfs上?
首先就是需要将hdfs相关程序启动起来----namenode和datanode
namendoe->相当于目录,不进行文件信息的存储
datanode->真正数据存放的位置
但namenode的默认存放位置在tmp文件下,tmp又是临时文件,随时可能被系统清除,我们存放在hdfs上的数据并不安全,所以我们需要修改一下namenode和datanode的存放位置

1.namenode的存储机制
-
fsimage:第一次namenode格式化->在硬盘上生成镜像文件fsimage(持久化存储)->进行元数据的存储
-
edits:以后进行hdfs文件的存取等文件操作->就会再生成一个文件edits(这是一个编辑文件 用于进行文件操作的记录)
-
只要进行namenode格式化,就会生成fsimage和edits这两个文件,两者结合使用,进行数据存储,防止数据丢失

-
edits_inprogress_0000000000000000003在形成新的edits文件前,数据就在这个文件中进行预存储(防止数据丢失)

- 但是会生成很多的fsimage和edits文件,我们要怎么读取呢?
- secondarynamenode->将fsimage和edits文件进行合并->合并之后就是一个fsimage镜像文件->在下一次启动时,直接加载fsimage中的内容
2.datanode的存储机制
namenode和datanode之间,会有一个心跳一致检查,来确保数据存储到对应的datanode中
3.修改namenode,datanode的存放位置
- namenode自己的存储机制 目的是防止数据丢失->可是namenode的默认存放位置在tmp文件夹下,tmp文件是系统文件,并且每隔一段时间都会自我清除,那么namenode的存储机制就没有用了->所以我们需要把namenode的存放位置进行更改
(1)根据官网 获得配置代码


(2)nodepad++中找到自己路径下的hadoop/etc/hadoop/hdfs-site.xml

(3)core-site.xml和hdfs-site.xml配置代码
虚拟机中创建自己想要存放namenode和datanode位置的文件夹
- 注:nodepad++ 打完代码后记得ctrl+s保存一下

(官网)
(3)关闭namenode和datanode

(4)删除原来格式化文件
只有把原来格式化文件删掉,才能重新格式化,不然namenode肯定起不来
rm -rf hadoop-root/

(5)重新格式化namenode
hadoop namenode -format

格式化成功----(在最后几行可以找到如下图的代码)
(6)重新启动namenode和datanode
//在自己路径下的hadoop的sbin下
//我的是 cd /opt/soft/hadoop/sbin
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start datanode

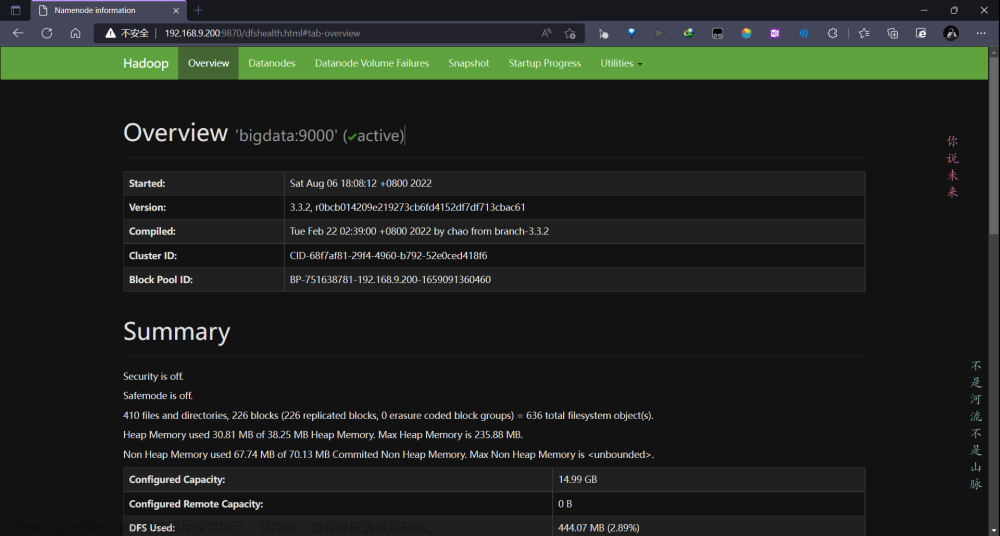
(7)网页中namenode的存储地址已经修改

4.Notepad++ 连接配置
(1)NppFTP插件安装

(2)nodepad++ 与虚拟机连接





连接成功

5.hdfs文件的操作
文件夹操作
(1)指定文件夹路径----mkdir
//在根目录中创建 名为a的文件夹
hdfs dfs -mkdir /a


(2)多层级文件夹的创建----mkdir -p
//在根目录下创建a文件夹,在a下创建b,b下创建c,c下创建d
hdfs dfs -mkdir -p /a/b/c/d

(3)移动文件夹----mv
//把d文件夹 移动到 /(根目录)下
hdfs dfs -mv /a/b/c/d /

(4)文件夹改名----mv
//把d文件夹的名称 改为 dd
hdfs dfs -mv /d /dd

(5)删除文件夹----rm -r
-R标识—>当前的路径表示是文件夹
//删除 /a/b/c文件夹
hdfs dfs -rm -R /a/b/c


文件操作
(1) 将本地文件上传到hdfs中----put
- put命令:用来将本地的文件上传到hdfs上
- put格式: put 本地文件名 hdfs上的目标文件名
//将datas.txt文件上传到 hdfs上的根目录下
hdfs dfs -put datas.txt /


replication:默认是3,但是如果进行单节点的服务器搭建,一般会改成1(因为只有一台服务器,不管存多少份,这一台服务器坏了,所有的数据都会消失)
官网修改方法: apache
(2)下载文件----get
- get 命令:用来从hdfs上下载文件,并存储在本地
- get 命令格式:get hdfs上的源文件名 下载后保存到本地的文件名
//把hdfs中根目录下a.txt文件下载到虚拟机/opt/a中
hdfs dfs -get /a.txt /opt/a

(3)文件复制----cp
//把根目录下的data.txt复制到 /a 下
hdfs dfs -cp /datas.txt /a

(4)文件改名----mv
//把根目录下的data.txt 改名为 a.txt
hdfs dfs -mv /datas.txt /a.txt
(5)文件的移动----mv
把根目录下的a.txt文件移动到/a/b下
hdfs dfs -mv /a.txt /a/b
(6)文件列表的查看----ls
hdfs dfs -ls /a

(7)文件内容的查看----cat
//查看a下datas.txt文件的内容
hdfs dfs -cat /a/datas.txt
(8)空文件创建----touch
//在根目录下创建一个名为a.txt的空文件
hdfs dfs -touch /a.txt
(9)文件内容拼接----appendToFile
把文件a中的内容拼接到指定文件b中,注意文件b必须为空文件,不然会报错
//把文件datas.txt的内容拼接到 /a.txt中
hdfs dfs -appendToFile datas.txt /a.txt


(10)文件删除
//删除hdfs中根目录下的a.txt文件
hdfs dfs -rm /a.txt
 文章来源:https://www.toymoban.com/news/detail-763293.html
文章来源:https://www.toymoban.com/news/detail-763293.html
块池
datanode有自己的数据存储机制----通过数据块进行的数据存储,数据块存在于块池中
数据块就是文件在hdfs中文件存储党的一个格式

[root@test1 subdir0]# pwd
/opt/datas/dfs/datas/current/BP-80508231-192.168.246.103-1696959173959/current/finalized/subdir0/subdir0文章来源地址https://www.toymoban.com/news/detail-763293.html
到了这里,关于hadoop(学习笔记) 4----怎么把文件放到hdfs上?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!