文末获取资源,收藏关注不迷路
前言
随着社会经济的快速发展,人们的生活水平得到了显著提高,但随之而来的社会问题也越来越多。其中最为显著的就是就业问题。为此,招聘信息的展示也变得越来越为重要。但是在大量的招聘信息中,人们在提取自己最想要的信息时变得不那么容易,对于应聘者也是如此。本系统通过对网络爬虫的分析,研究智联招聘网站数据,尝试使用Python技术进行开发,将智联招聘网招聘信息尽可能的爬取出来,并对结果进行检测判断,最后可视化分析出来,为用户提供精确的查询结果。基于Python的招聘网站信息爬取与数据分析系统旨在提高数据挖掘的效率,便于科学的管理和分析招聘数据。
本文先分析基于Python的招聘网站信息爬取与数据分析系统的背景和意义;对常见的爬虫原理,获取策略,信息提取等技术进行分析;本系统使用python进行开发,MySQL数据库进行搭建,实现了招聘的数据爬取;对数据库的查询结果进行检测并可视化分析,对系统的前台界面进行管理,分析爬取的结果,并对招聘数据结果进行大屏显示;最后通过测试实现了数据爬取,存储过滤和数据可视化分析,以及系统管理等功能
一、研究背景
互联网信息技术已经发展了很长时间,时至今日,越来越多的终端设备出现在人们的生活中,各种网络技术、移动终端日益成熟,而且价格越来越平民化。互联网技术已经到了前所未有的高度,借助于网络基础设施的建设,各种电子芯片和云计算快速的发展。传统信息的传播方式逐渐萎靡,比如报纸杂志等,几乎破产。目前人们只需要通过掌上电脑或者手机就可以查询到自己所需的信息,之所以网络设备如此受欢迎,是因为借助互联网技术所提供的强大信息呈现在网络中,只需要通过手指一点,就可以获取到自己想要知道的内容。用户只需要通过一个关键字,就可以从海量的信息中检索出相关的信息词条,然后将这些信息可视化呈现在用户面前,这种方式受到了用户的喜爱。
本课题所研究的基于Python的招聘网站信息爬取与数据分析系统也广泛存在于互联网中,通过智联招聘网搜索引擎,我们可以获取到对应的招聘数据,然而这些方法大多比较零碎,没有进行专门的分类,甚至存在一些假冒的和带广告性质的宣传,严重影响了招聘数据的获取体验。
智联招聘网目前是国内比较大的专业招聘平台,拥有大量的招聘信息和求职者。使用爬虫技术,对智联招聘网招聘数据进行抓取,得到海量的信息,然后对数据进行处理和分析,最终将分析的招聘数据数据可视化展现出来,可以服务大众。因此,本选题将招聘数据信息的收集置于具体的智联招聘网平台,从而进行研究招聘情况和岗位偏向。
二、研究意义
在目前信息化时代,数据的收集和整理是非常重要的工作。高效的收集可以提高相关工作人员的工作效率。计算机技术也逐渐向精细化方面发展,技术的更新影响了人们的生产生活方式,不同的技术平台也不断的更新着相关的信息。传统的信息采收集都是采取人工的方式,并对信息进行整理、修改、存储等,严重影响了信息制作的时间成本。另外,随着信息量的增加,工作人员整理起来更加的繁琐,而且容易出错,更无从谈起精确的归纳和统计,所以效率逐渐低下。在这些重复的工作中,只有通过信息化技术手段来进行管理,才能有效的提高信息的获取效率。
本基于Python的招聘网站信息爬取与数据分析系统中,通过相关的技术手段对招聘数据进行爬取,收集智联招聘网中的招聘数据信息,并将这些数据存储到数据库中,在收集招聘数据时进行清洗、归纳和整理,形成了有条理的数据集合,可以有效的提高招聘数据数据的效率。借助数据库平台的优势可以对数据进行查询和统计,本系统旨在实现用户对招聘数据的获取,并可以通过可视化平台对数据进行展现,提供系统内的信息检索手段,可以更有效的查询用户需要的招聘数据,最终实现了招聘数据的有效挖掘,提高了数据爬取的准确率,实现了数据的统计查询功能,并对爬取的数据进行管理,提高了工作效率。
对于即将毕业找工作的应届生和社会择业人员来说,上网快速找到合适的工作,无疑是急需的。招聘网站数据可视化项目从繁杂的招聘信息中提取出潜在的、有价值的数据,并以图形的形式进行直观化展示,将用户从一堆杂乱无章的数据里面解放出来。通过该系统用户能够更加高效的理解和分析招聘数据信息,快速获取自身所需要的信息使得招聘信息能够更加明确、有效地进行传递。有利于用户明确学习方向,以及所需要掌握的工作技能和知识。
本题目来源于求职招聘研发项目的子项目,该项目主要完成一个招聘数据系统的设计和开发,该系统用于收集当前地方招聘数据,然后通过爬取、清理、存储、统计招聘数据,并进行招聘数据,是现代化招聘系统不可缺少的部分,为具体岗位的需求发展趋势提供便捷的推荐模式。
三、主要使用技术
环境需要
1.运行环境:python3.7/python3.8。
2.IDE环境:pycharm+mysql5.7;
3.数据库工具:Navicat11
4.硬件环境:windows 7/8/10 1G内存以上;或者 Mac OS;
5.数据库:MySql 5.7版本;
技术栈
后端:python+django
前端:vue+CSS+JavaScript+jQuery+elementui
使用说明
使用Navicat或者其它工具,在mysql中创建对应名称的数据库,并导入项目的sql文件;
使用PyCharm 导入项目,修改配置,运行项目;
将项目中config.ini配置文件中的数据库配置改为自己的配置,然后运行;
运行成功后,在浏览器中输入:http://localhost:8080/项目名
四、研究内容


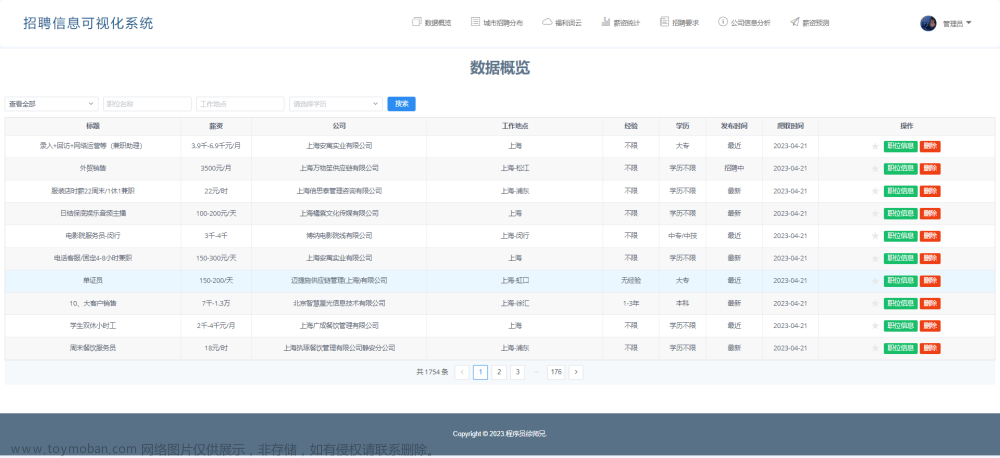
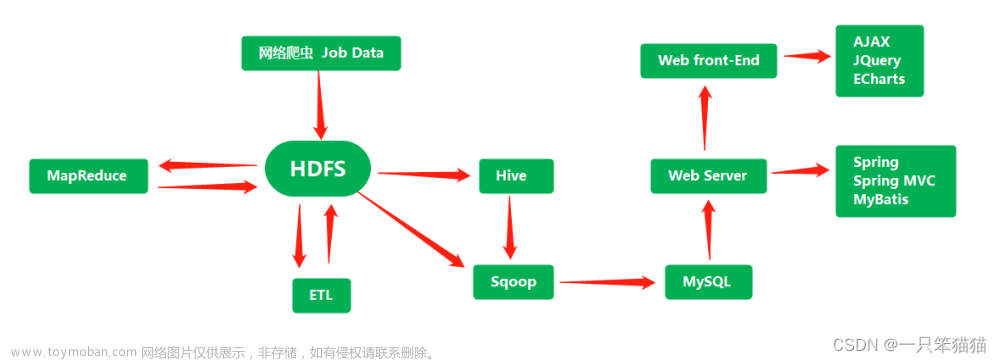
爬取完招聘数据后,需要对数据进行分析,根据评分和K-means聚类算法分析出招聘数据趋势,并可视化查询处理。本系统使用Python进行编程,通过HTML、JS等方法显示数据。具体包括:招聘数据数据展示、招聘数据分类、用户注册登录、用户管理和爬虫数据管理。
在目前计算机信息化快速发展过程中,招聘和求职逐渐转移到网络中来,本题目来源于求职招聘系统研发项目的子项目,该项目主要完成一个招聘数据系统的设计和开发,该系统用于收集当前地方招聘数据,然后通过爬取、清理、存储、统计招聘数据,并进行招聘数据,是现代化招聘管理不可缺少的部分,为热门岗位的推荐提供便捷的模式。本文旨在对智联招聘网上的招聘信息、岗位信息进行爬取,收集各种类型的招聘数据信息。然后对招聘数据的内容进行分析,整理招聘数据信息。本系统首先分析智联招聘网站的网站结构,查看网站网页的排版,然后读取其包含的招聘信息。具体分为以下几个步骤,指定智联招聘网url,爬取网页信息,获取特定的智联招聘网url存入队列中,提取招聘数据的信息,将信息存入数据库,然后对岗位和薪资等进行分析,得出招聘数据的可视化视图。
本系统使用智联招聘网作为目标网站,先分析该网站的结构,然后对网页的数据进行爬取,在爬取过程中会遇到一些重复的招聘数据,需要对数据进行清洗,通过数据处理获取到相对完整的招聘数据,并把处理后的数据存储在对象中,通过循环对象来构造数据存储的插入语句,再进行数据存储,将数据保存在MySQL数据库中。





 文章来源:https://www.toymoban.com/news/detail-763553.html
文章来源:https://www.toymoban.com/news/detail-763553.html
五、核心代码
# coding:utf-8
__author__ = "ila"
from django.http import JsonResponse
from .users_model import users
from util.codes import *
from util.auth import Auth
import util.message as mes
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
def users_info(request, id_):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
data = users.getbyid(users, users, int(id_))
if len(data) > 0:
msg['data'] = data[0]
# 浏览点击次数
try:
__browseClick__ = users.__browseClick__
except:
__browseClick__ = None
if __browseClick__ and "clicknum" in users.getallcolumn(users, users):
click_dict = {"id": int(id_), "clicknum": str(int(data[0].get("clicknum", 0)) + 1)}
ret = users.updatebyparams(users, users, click_dict)
if ret != None:
msg['code'] = crud_error_code
msg['msg'] = ret
return JsonResponse(msg)
def users_save(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
req_dict = request.session.get("req_dict")
req_dict['role'] = '管理员'
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_update(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
req_dict = request.session.get("req_dict")
if req_dict.get("mima") and req_dict.get("password"):
if "mima" not in users.getallcolumn(users,users):
del req_dict["mima"]
if "password" not in users.getallcolumn(users,users):
del req_dict["password"]
try:
del req_dict["clicknum"]
except:
pass
error = users.updatebyparams(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_delete(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
req_dict = request.session.get("req_dict")
error = users.deletes(users,
users,
req_dict.get("ids")
)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
六、文章目录
1系统概述 1
1.1 研究背景 1
1.2研究目的 1
1.3系统设计思想 1
2相关技术 3
2.1 MYSQL数据库 3
2.2 B/S结构 3
2.3 Djangot框架简介 4
2.4 VUE框架 4
3系统分析 5
3.1可行性分析 5
3.1.1技术可行性 5
3.1.2经济可行性 5
3.1.3操作可行性 5
3.2系统性能分析 6
3.2.1 系统安全性 6
3.2.2 数据完整性 6
3.3系统界面分析 6
3.4系统流程和逻辑 8
4系统概要设计 9
4.1概述 9
4.2系统结构 10
4.3.数据库设计 11
4.3.1数据库实体 11
4.3.2数据库设计表 13
5系统详细实现 17
5.1 管理员模块的实现 17
5.2用户模块的实现 19
6系统测试 21
6.1概念和意义 21
6.2特性 22
6.3重要性 22
6.4测试方法 23
6.5 功能测试 23
6.6可用性测试 24
6.7性能测试 24
6.8测试分析 24
6.9测试结果分析 25
结论 25
致谢语 26
参考文献 26文章来源地址https://www.toymoban.com/news/detail-763553.html
到了这里,关于基于Python的招聘网站信息爬取与数据分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!