一、AnimateDiff简介
AnimateDiff采用控制模块来影响Stable Diffusion模型,通过大量短视频剪辑的训练,它能够调整图像生成过程,生成一系列与训练视频剪辑相似的图像。简言之,AnimateDiff通过训练大量短视频来优化图像之间的过渡,确保视频帧的流畅性。
与传统的SD模型训练方式不同,AnimateDiff通过大量短视频的训练来提高图像之间的连续性,使得生成的每一张图像都能经过AnimateDiff微调,最终拼接成高质量短视频。
![animatediff视频格式,[Stable Diffusion]AI绘画从入门到精通,stable diffusion,音视频](https://imgs.yssmx.com/Uploads/2023/12/763585-1.png)
二、安装AnimateDiff
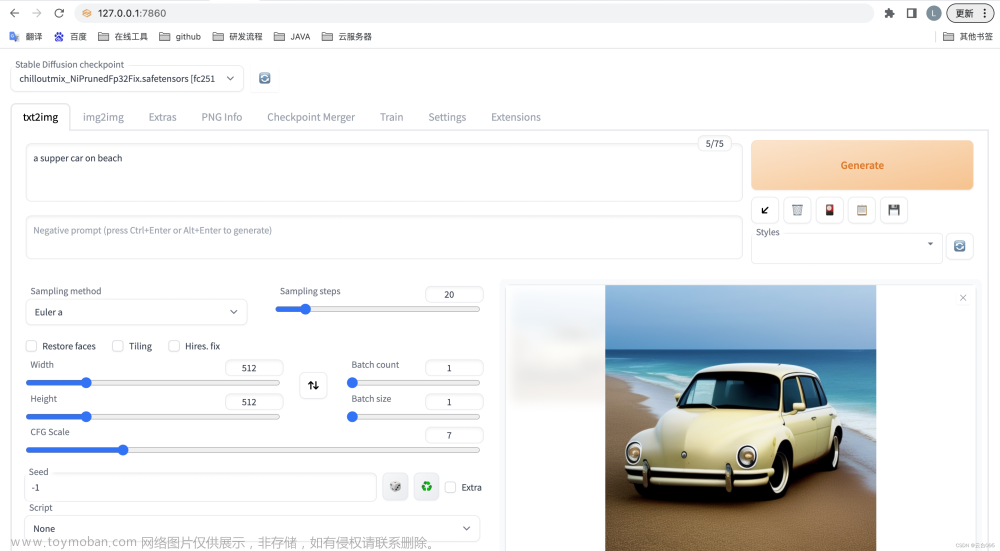
要使用AnimateDiff,需要安装SD插件和AnimateDiff模型。
插件安装:如果你可以科学上网,你可以直接在扩展->从网址安装中填入https://github.com/continue-revolution/sd-webui-animatediff.git
![animatediff视频格式,[Stable Diffusion]AI绘画从入门到精通,stable diffusion,音视频](https://imgs.yssmx.com/Uploads/2023/12/763585-2.png) 文章来源:https://www.toymoban.com/news/detail-763585.html
文章来源:https://www.toymoban.com/news/detail-763585.html
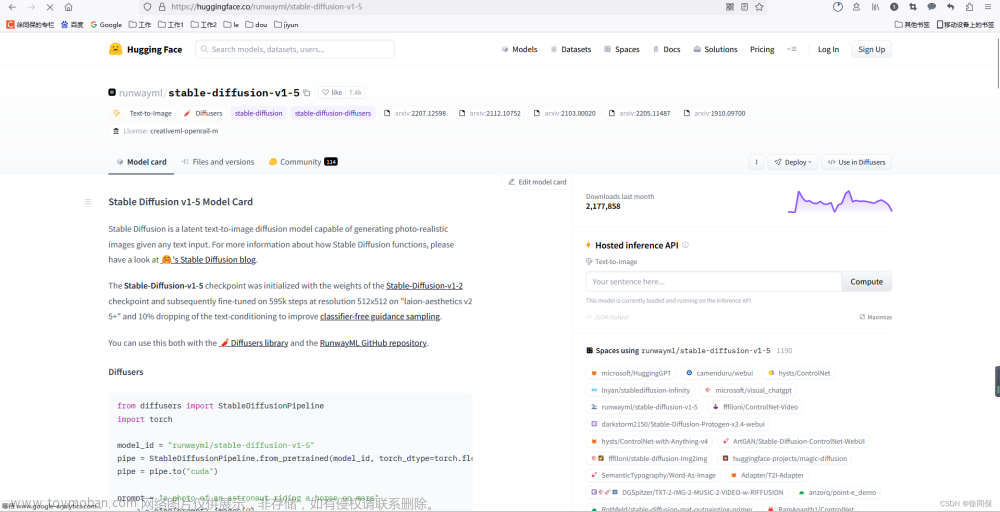
模型下载:安装插件后,下载AnimateDiff模型并将其放置在stable-diffusion-webui/extensions/sd-webui-animatediff/model/目录下。<文章来源地址https://www.toymoban.com/news/detail-763585.html
到了这里,关于[Stable Diffusion进阶篇]AnimateDiff :最稳定的文本生成视频插件的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!