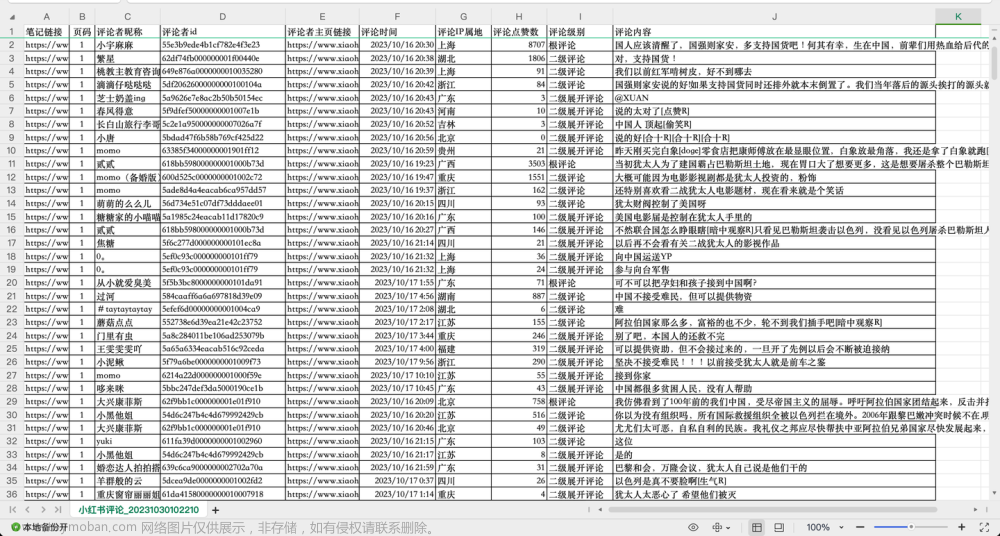
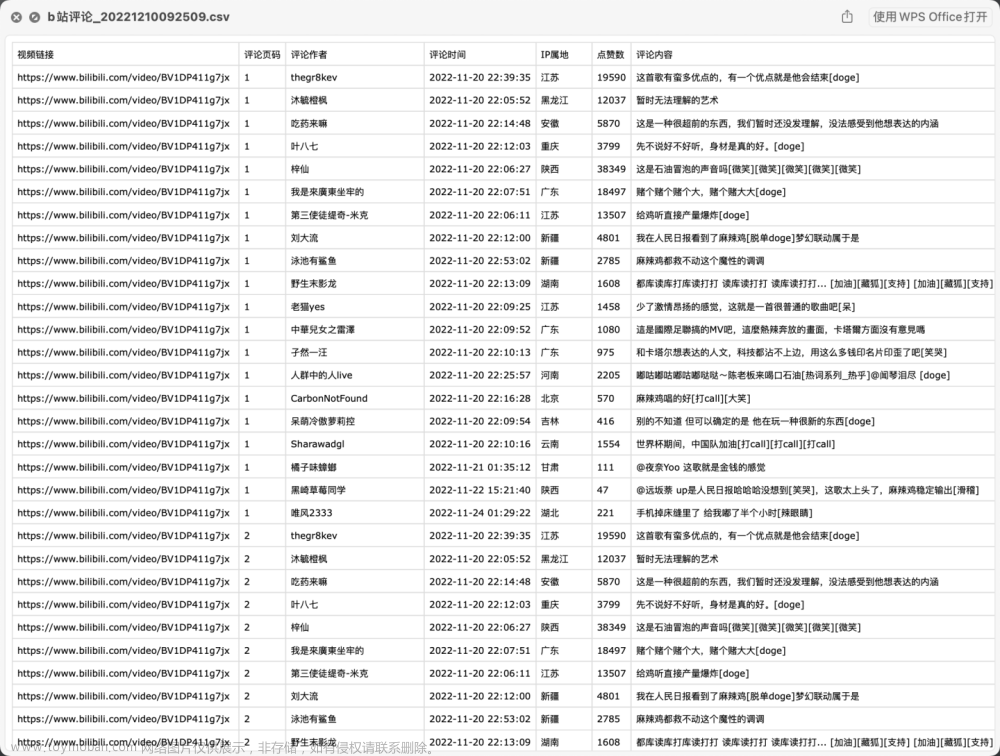
今天花了一上午探究如何用selenium获取b站视频下面的评论,一开始只是想用一个视频来练练手,后面逐渐改成了所有视频都适用的完整代码。
话不多说,直接上源码:
因为我是用的jupyter,所以整个代码包括两个部分。下面这段代码用于完成获取自动登录b站所需的cookie。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import json
browser = webdriver.Chrome()
browser.get("https://www.bilibili.com")
browser.delete_all_cookies()
time.sleep(20)
dictions = browser.get_cookies()
jsons = json.dumps(dictions)
with open("b站cookie.txt", 'w') as f:
f.write(jsons)
browser.quit()下面是第二段代码,具体讲解我会放在b站上。地址在评论区中。下面的代码大家可以直接运行,还可以更换视频地址。文章来源:https://www.toymoban.com/news/detail-763701.html
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import StaleElementReferenceException
import time
import json
browser = webdriver.Chrome()
# 登录并加载视频页面
def login_in(browser):
# 进入要爬取的页面
browser.get("https://www.bilibili.com/video/BV1Xu4y117t9/?spm_id_from=333.999.0.0&vd_source=01e74f1ac8f918c9ada8b2cb79b8c6c8")
f = open("b站cookie.txt", 'r')
cookie = json.loads(f.read())
# 利用cookie自动登录账号
for i in cookie:
browser.add_cookie(i)
browser.refresh()
time.sleep(10) # 让网页加载完毕,防止后面找元素没找到(这里卡了我1个多小时)
# 滑动页面的操作
def slip_page(browser):
# browser: 驱动器对象
document = browser.execute_script('return document.body.scrollHeight;') # 滑动之前的页面高度
time.sleep(2)
browser.execute_script(f'window.scrollTo(0,{document})') # 滑动页面
time.sleep(2)
document2 = browser.execute_script('return document.body.scrollHeight;')# 滑动之后的页面高度
# 获取子评论内容函数
def get_content(reply, attr):
# reply: 找到的评论元素
# attr: 页面中对应的类属性
for i in reply:
sub_reply = i.find_element(By.CLASS_NAME, 'reply-content')
if sub_reply.text is None:
pass
else:
print("子评论:" + sub_reply.text)
# 获取已加载的所有评论函数
def get_comments(browser):
# 1.登录b站,找到对应视频页面
login_in(browser)
# 2. 加载当前页面出现了的所有评论
comment_area = browser.find_element(By.CSS_SELECTOR, '#comment > div > div > div > div.reply-warp > div.reply-list')
reply_items = comment_area.find_elements(By.CLASS_NAME, 'reply-item') # 获得了当前加载的评论,不是所有评论(动态加载)
while True:
for item in reply_items:
"""
这里有个逻辑:
如果一条评论没有查看更多按钮:
那么直接去获取内容
如果有查看更多按钮则进行点击:
如果点击完查看更多按钮,没有别的内容:
则跳到下一条评论
如果点击完还有“下一页”按钮,则点击下一页按钮:
如果点击完下一页按钮 ,还有下一页按钮,则继续点击
如果点击完下一页按钮,没有下一页按钮,则跳到下一条评论
"""
# 子评论中没有查看更多,直接获取内容
view_more = item.find_elements(By.CLASS_NAME, 'view-more-btn')
if len(view_more) == 0:
sub_replys = item.find_elements(By.CLASS_NAME, 'sub-reply-item')
get_content(sub_replys, "reply-content")
# 子评论区有查看更多,则先找到这个按钮并点击
elif len(view_more) != 0:
browser.execute_script("arguments[0].click();", view_more[0])
time.sleep(3) # 等待3秒页面更新
sub_replys = item.find_elements(By.CLASS_NAME, 'sub-reply-item') # 找到这一页完整的子评论
get_content(sub_replys, "reply-content")
# 循环判断有无下一页按钮
while True:
pagination_btn = item.find_elements(By.CLASS_NAME, 'pagination-btn')
# 如果这条评论没有下一页子评论,则结束循环,获取完主评论后跳到下一条评论
if len(pagination_btn) == 0:
break
# 如果有下一页,则点击下一页
elif len(pagination_btn) != 0:
# 这里会有3种情况,分别是“只有下一页”、“上一页+下一页”、“只有上一页”
# 针对只有上一页,则退出循环
if len(pagination_btn) == 1 and pagination_btn[0].text == "上一页":
break
time.sleep(3) # 等待网页加载
print(pagination_btn)
# 针对只有下一页,则点击第一个按钮,即下一页
if len(pagination_btn) == 1 and pagination_btn[0].text == "下一页":
browser.execute_script("arguments[0].click();", pagination_btn[0])
time.sleep(3) # 等待网页加载
sub_replys = item.find_elements(By.CLASS_NAME, 'sub-reply-item') # 找到这一页完整的子评论
get_content(sub_replys, "reply-content")
# 针对有上一页和下一页,我们要点击第二个按钮,也就是下一页
if len(pagination_btn) == 2:
browser.execute_script("arguments[0].click();", pagination_btn[1])
time.sleep(3) # 等待网页加载
sub_replys = item.find_elements(By.CLASS_NAME, 'sub-reply-item') # 找到这一页完整的子评论
get_content(sub_replys, "reply-content")
# 不要忘记主评论的内容
root_reply = item.find_element(By.CSS_SELECTOR, 'span[class="reply-content"]').text
if root_reply is None:
pass
else:
print("主评论:" + root_reply)
# 当前加载的评论全部获取完毕,需要滑动页面,并获得新加载的评论
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
reply_items = comment_area.find_elements(By.CLASS_NAME, 'reply-item')
get_comments(browser)觉得对你有帮助的话就点赞收藏加关注吧!文章来源地址https://www.toymoban.com/news/detail-763701.html
到了这里,关于爬取b站任意视频下的所有评论【附完整代码】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!