找论文搭配 Sci-Hub 食用更佳 💪
Sci-Hub 实时更新 : https://tool.yovisun.com/scihub/
公益科研通文献求助:https://www.ablesci.com/
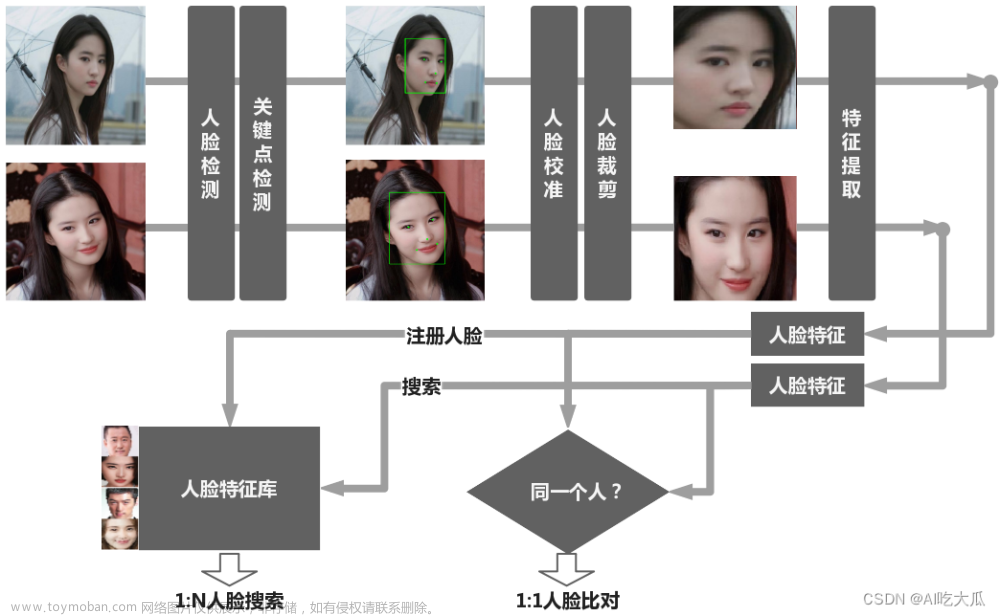
总述
人脸识别流程:检测、对齐、(活体)、预处理、提取特征(表示)、人脸识别(验证)

传统特征方法
传统方法试图通过一两层表示来识别人脸,例如过滤响应、特征直方图分布。学术圈进行了深入的研究,分别改进了预处理、局部描述符和特征转换,但这些方法在提高FR准确性方面进展缓慢。更糟糕的是,大多数方法只针对不受约束的面部变化的一个方面,如光照、姿势、表情,并没有任何综合技术来整体解决这些不受约束的挑战。因此,经过十多年的持续努力,“浅层”方法仅将LFW基准数据集的准确性提高到约95%[15],这表明“浅层的”方法不足以提取对真实世界变化的稳定身份特征信息。
深度学习方法
GhostFaceNets: Lightweight Face Recognition Model From Cheap Operations ,IEEE Access,2023,LFW dataset Rank 1.
混合精度,(sub-center) arcface cosface loss, ghostnet (lightweight, cvpr)
Deep Polynomial Neural Networks,2021,作者来自英国伦敦帝国理工学院计算系、瑞士洛桑联邦理工学院 (EPFL) 电气工程系、希腊雅典大学信息学和电信系,该方法已申请专利。
多项式神经网络,即输出是输入的高阶多项式。未知参数自然地由高阶张量表示,通过因子共享的集体张量分解来估计。作者介绍了三种显着减少参数数量的张量分解,并展示了如何通过分层神经网络有效地实现它们。并凭经验证明,π-Nets 具有很强的表现力,它们甚至可以在大量任务和信号(即图像、图形和音频)中不使用非线性激活函数的情况下产生良好的结果。当与激活函数结合使用时,Π-Nets 在图像生成、人脸验证和 3D 网格表示学习三个具有挑战性的任务中产生了最先进的结果。

ArcFace: Additive Angular Margin Loss for Deep Face Recognition
DCNN 将人脸图像(通常在姿势归一化步骤 [7]、[8] 之后)映射到应该具有较小的类内距离和较大的类间距离的特征。训练 DCNN 进行人脸识别有两个主要研究方向。一些训练一个多类分类器,可以在训练集中分离不同的身份,例如使用 softmax 分类器 [2]、[4]、[9]、[10]、[11],其他直接学习嵌入,例如三元组损失 [3]。
基于大规模训练数据和精细的 DCNN 架构,softmax-loss 的方法 [9] 和triplet-loss 的方法 [3] 都可以获得出色的人脸识别性能。然而,softmax loss 和 triplet loss 都有一些缺点。
对于 softmax 损失:(1)学习到的特征对于闭集分类问题是可分离的,但对于开放集人脸识别问题的区分度不够; (2) 线性变换矩阵 W ∈ R d × N W \in \mathbb{R}^{ d×N} W∈Rd×N 的大小随身份数 N N N 线性增加。
对于三元组损失: (1) 人脸三元组的数量组合爆炸式增长,尤其是对于大规模数据集,导致迭代步数显着增加; (2) 半难样本挖掘对于训练有效的模型来说相当困难。


DiscFace: Minimum Discrepancy Learning for Deep Face Recognition,2020,ACCV
作者发现了基于Softmax的方法的一个重要问题:在训练阶段,对应类权重附近的样本特征同样受到惩罚,尽管它们的方向不同。为了缓解这一问题,提出了一种新的训练方案,称为最小差异学习,它通过使用单一的可学习基来强制类内样本特征的方向向最优方向对齐。
早些时候,深度度量学习方法通过样本对(或三元组)之间距离的局部关系学习人脸嵌入,从而在类不平衡数据集下取得了可喜的成果 [1–3, 11]。深度度量学习能够通过利用某些度量损失直接捕获更多的判别力。然而,它们的性能在很大程度上取决于采样和挖掘策略,因此,度量学习模型通常需要耗时的来回过程来训练。
与分类任务相比,学习大边缘判别特征对于人脸识别任务至关重要,特别是在开放集协议下,这是一种更现实但更具挑战性的人脸识别协议 [6]。许多工作都试图修改 softmax 损失以获得有效的 large-margin 判别特征 [5, 6, 13, 7, 8]。这样的变体能够直接优化特征之间的角度和超球面流形中相应的类权重。
然而,作者观察到,在开放集协议下,它们的评估性能可能会受到训练和评估过程之间差异的影响:训练期间使用样本特征和 softmax 类权重之间的匹配分数,而在评估阶段(没有类别权重)匹配分数是在不同样本特征之间计算的。这种差异导致样本特征之间存在方向差异,如图 1 所示。作者将此问题称为“process discrepancy”。

总之,该方案专门用于减轻训练和评估阶段之间的过程差异,以便在评估阶段提供更好的性能。这是第一个基于 softmax 学习方法的用于解决过程差异问题的人脸识别任务,而以前的方法只关注判别学习。


MagFace: A universal representation for face recognition and quality ssessment
MagFace 探索了根据可识别性应用不同边距的想法。它在高范数特征易于识别的前提下,对高范数特征应用大角度边距。大边缘将高范数的特征推向类中心。然而,它未能强调难训练样本,这对于学习判别特征来说很重要。

AdaFace: Quality Adaptive Margin for Face Recognition
影响图像质量的因素包括亮度、对比度、清晰度、噪声、颜色恒定性、分辨率、色调再现等。论文关注的人脸图像可以在各种照明、姿势和面部表情设置下拍摄,有时也可以在受试者的年龄或化妆等极端视觉变化下拍摄。这些参数设置使得学习的人脸识别(FR)模型的识别任务变得困难。尽管如此,这项任务是可以实现的,因为人类或模型通常可以在这些困难的环境下识别人脸[37]。
先前的研究已经证明了自适应损失的影响,以赋予错误分类(hard)样本更多的重要性。文章中,作者引入了损失函数中自适应性的另一个方面,即图像质量。作者认为,强调错误分类样本的策略应该根据它们的图像质量进行调整。具体而言,简单样本或难样本的相对重要性应基于样本的图像质量。因此提出了一种新的损失函数,该函数根据不同难度的样本的图像质量来强调它们。具体实现方法是通过用特征范数逼近图像质量,以自适应边缘函数的形式实现了这一点。
由于存在无法识别的面部图像(下图红色区域),作者想设计一个损失函数,根据图像质量为不同难度的样本分配不同的重要性。目标是强调高质量图像的硬样本和低质量图像的简单样本,如果图像质量低,损失函数会强调简单的样本(从而避免无法识别的图像)。否则,损失会强调hard样本。

作者发现 1) 特征范数可以很好地代表图像质量, 2) 各种边缘函数相当于为样本的不同难度分配不同的重要性。这两个发现结合在一个统一的损失函数 AdaFace 中,它根据图像质量自适应地改变边缘函数,为不同难度的样本分配不同的重要性(见上图)
许多研究在硬样本挖掘 [22、40]、训练期间的调度难度 [16、35] 或寻找最佳超参数 [45] 的训练目标中引入了适应性元素。例如,CurricularFace [16] 将课程学习的思想带入了损失函数。在训练的初始阶段,将
c
o
s
θ
j
cos θ_j
cosθj(负余弦相似度)的边距设置得较小,以便学习容易的样本,在后期阶段,增加边距,以便学习难的样本
t 是随着训练的进行而增加的参数。
因此,在 CurricularFace 中,margin 中的自适应性是基于训练进程(curriculum)的。
IJB-B [41]、IJB-C [26] 和 IJB-S [17]中大多数图像质量较低,有些不包含足够的身份信息,即使对于人类也是如此考官。良好性能的关键包括 1) 学习低质量图像的判别特征和 2) 学习丢弃包含很少身份线索的图像,后者有时被称为质量感知融合

QMagFace: Simple and Accurate Quality-Aware Face Recognition
作者将质量感知比较分数与基于幅度感知角度边缘损失的识别模型相结合。所提出的方法在比较过程中包括特定于模型的人脸图像质量,以增强在不受约束的情况下的识别性能。利用质量与其由使用损失引起的比较分数之间的线性关系,该质量感知比较函数简单且高度通用。

FaceNet: A Unified Embedding for Face Recognition and Clustering,2015
FaceNet 直接学习从面部图像到紧凑欧几里得空间的映射,其中距离直接对应于面部相似性的度量。一旦产生了这个空间,就可以使用标准技术将 FaceNet 嵌入作为特征向量轻松实现人脸识别、验证和聚类等任务。
该方法使用经过训练的深度卷积网络来直接优化嵌入本身,而不是像以前的深度学习方法那样使用中间瓶颈层。为了进行训练,作者使用了一种新颖的在线三元组挖掘方法生成的大致对齐的匹配/非匹配面部补丁的三元组。方法的好处是表示效率更高:仅使用每张脸 128 字节就实现了最先进的人脸识别性能
损失函数演进
基于 Softmax 的学习:在各种应用中许多方法已经研究基于 softmax 的判别特征学习 [18-25]。在人脸识别任务中,Center loss [4]提出了一种最小化类内方差的方法。该方法计算每个类的样本质心,并最小化特征向量与其对应质心之间的类内距离。 Crystal loss [26]引入一个约束来强制特征向量的范数为某个值。Ring loss[27]使范数成为可训练的参数,并鼓励对特征向量的范数进行最佳训练。 NormFace [5] 是一种学习超球体流形特征的方案,这样类之间的区分就可以通过角度来完成。Sphereface [6] 引入了乘法角度边缘损失,使特征更具辨别力。类似的方式,CosFace [7] 和 ArcFace [8] 证明了角边距的有效性,它们以不同的方式使用角距。
基于度量学习: 基于度量的学习方法 [1-3] 直接从样本之间的关系中学习判别特征。对比损失 [1] 使用正负样本对来学习两个样本之间的关系。三元组损失 [3] 学习到锚点和正样本之间的距离小于锚点和负样本之间的距离。尽管基于度量的学习是解决验证问题的一种直观方法,但基于度量的学习的主要缺点在于数据采样的困难。很难训练所有可能的对或三元组,性能在很大程度上取决于挖掘策略。
基于欧几里德和距离的损失
Triplet loss要确保特定人的图像
x
i
a
x_i^a
xia(anchor)与同一个人的所有其他图像
x
i
p
x_i^p
xip(positive)比与任何其他人的任何图像
x
i
n
x_i^n
xin(negative)更接近。在图 3 中可视化
L
t
r
i
=
∑
i
N
[
∣
∣
f
(
x
i
a
)
∣
∣
2
2
]
L_{tri}=\sum_{i}^{N} \left [||f(x_i^a)||_2^2 \right ]
Ltri=i∑N[∣∣f(xia)∣∣22]
def triplet_loss(alpha = 0.2):
def _triplet_loss(y_pred, Batch_size):
anchor, positive, negative = y_pred[:int(Batch_size)], y_pred[int(Batch_size):int(2*Batch_size)], y_pred[int(2*Batch_size):]
pos_dist = torch.sqrt(torch.sum(torch.pow(anchor - positive,2), axis=-1))
neg_dist = torch.sqrt(torch.sum(torch.pow(anchor - negative,2), axis=-1))
keep_all = (neg_dist - pos_dist < alpha).cpu().numpy().flatten()
hard_triplets = np.where(keep_all == 1)
pos_dist = pos_dist[hard_triplets]
neg_dist = neg_dist[hard_triplets]
basic_loss = pos_dist - neg_dist + alpha
loss = torch.sum(basic_loss) / torch.max(torch.tensor(1), torch.tensor(len(hard_triplets[0])))
return loss
return _triplet_loss
基于角度/余弦边距的损失
SoftMax 损失及其变体
S
o
f
t
M
a
x
:
L
1
=
−
l
o
g
e
W
y
i
T
+
b
y
i
∑
j
=
1
N
e
W
j
T
x
i
+
b
j
SoftMax : \quad \quad \quad L_1=-log\frac{e^{W_{y_i}^{T} + b_{y_i}}} {\sum_{ j=1}^{N}e^{W_{j}^{T}x_i+b_j} }
SoftMax:L1=−log∑j=1NeWjTxi+bjeWyiT+byi
S
o
f
t
M
a
x
L
o
s
s
SoftMax \,\, Loss
SoftMaxLoss 做简化,
b
i
a
s
b
j
=
0
a
n
d
W
j
T
x
i
=
∣
∣
W
j
∣
∣
⋅
∣
∣
x
i
∣
∣
⋅
c
o
s
θ
j
并通过
l
2
n
o
r
m
使
∣
∣
W
j
∣
∣
=
1
,
∣
∣
x
i
∣
∣
r
e
−
s
c
a
l
e
t
o
s
,则
bias \,\,b_j=0 \,\,and \,\,W_j^Tx_i=||W_j||·||x_i||·cos\theta_j \\ 并通过l_2\, \,norm \, \,使||W_j||=1,||x_i||\, \, \,re_-scale \,\,to \,\, \bold s,则
biasbj=0andWjTxi=∣∣Wj∣∣⋅∣∣xi∣∣⋅cosθj并通过l2norm使∣∣Wj∣∣=1,∣∣xi∣∣re−scaletos,则
s
i
m
p
l
i
f
y
,
L
2
=
−
l
o
g
e
s
c
o
s
θ
y
i
e
s
c
o
s
θ
y
i
+
∑
j
=
1
,
j
≠
y
i
n
e
s
c
o
s
θ
j
\bold {simplify} , \quad \quad L_2=-log\frac{e^{s\,cos\theta_{yi}}} {e^{s\,cos\theta_{yi}}+\sum_{ j=1,j≠y_i}^{n}e^{s\,cos\theta_j} }
simplify,L2=−logescosθyi+∑j=1,j=yinescosθjescosθyi
特征和权重的归一化步骤使预测仅取决于特征和权重之间的角度。因此,学习到的嵌入特征分布在半径为 s 的超球面上。
由于嵌入特征分布在超球体上的每个特征中心周围,在 x i x_i xi和 W y i W_{yi} Wyi 之间采用加性角边缘惩罚 a d d i t i v e a n g u l a r m a r g i n p e n a l t y m additive \,\, angular \,\, margin\,\, penalty\,\,m additiveangularmarginpenaltym 来同时增强类内紧凑性和类间差异,则
A r c F a c e L o s s , L 3 = − l o g e s c o s ( θ y i + m ) e s c o s ( θ y i + m ) + ∑ j = 1 , j ≠ y i n e s c o s θ j ArcFace\,Loss,\quad \quad L_3=-log\frac{e^{s\,cos(\theta_{yi}+m)}} {e^{s\,cos(\theta_{yi}+m)}+\sum_{ j=1,j≠y_i}^{n}e^{s\,cos\theta_j} } ArcFaceLoss,L3=−logescos(θyi+m)+∑j=1,j=yinescosθjescos(θyi+m)文章来源:https://www.toymoban.com/news/detail-763760.html
评价指标:
A
c
c
=
T
A
+
T
R
T
A
+
T
R
+
F
R
+
F
A
T
A
R
(
T
r
u
e
A
c
c
e
p
t
R
a
t
e
)
=
T
A
T
A
+
F
R
F
A
R
(
F
a
l
s
e
A
c
c
e
p
t
R
a
t
e
)
=
F
A
F
A
+
T
R
F
R
R
(
F
a
l
s
e
R
e
j
e
c
t
R
a
t
e
)
F
R
T
R
+
F
R
\bold {Acc}= \frac{TA+TR}{TA+TR+FR+FA} \\ \bold{TAR}(True Accept Rate)= \frac{TA}{TA+FR} \\ FAR(False Accept Rate)= \frac{FA}{FA+TR} \\ \\FRR(False Reject Rate) \frac{FR}{TR+FR}
Acc=TA+TR+FR+FATA+TRTAR(TrueAcceptRate)=TA+FRTAFAR(FalseAcceptRate)=FA+TRFAFRR(FalseRejectRate)TR+FRFR文章来源地址https://www.toymoban.com/news/detail-763760.html
一级标题
二级标题
二级标题
二级标题
到了这里,关于人脸识别 Face Recognition 入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!