博主介绍:黄菊华老师《Vue.js入门与商城开发实战》《微信小程序商城开发》图书作者,CSDN博客专家,在线教育专家,CSDN钻石讲师;专注大学生毕业设计教育和辅导。
所有项目都配有从入门到精通的基础知识视频课程,免费
项目配有对应开发文档、开题报告、任务书、PPT、论文模版等项目都录了发布和功能操作演示视频;项目的界面和功能都可以定制,包安装运行!!!
如果需要联系我,可以在CSDN网站查询黄菊华老师
在文章末尾可以获取联系方式
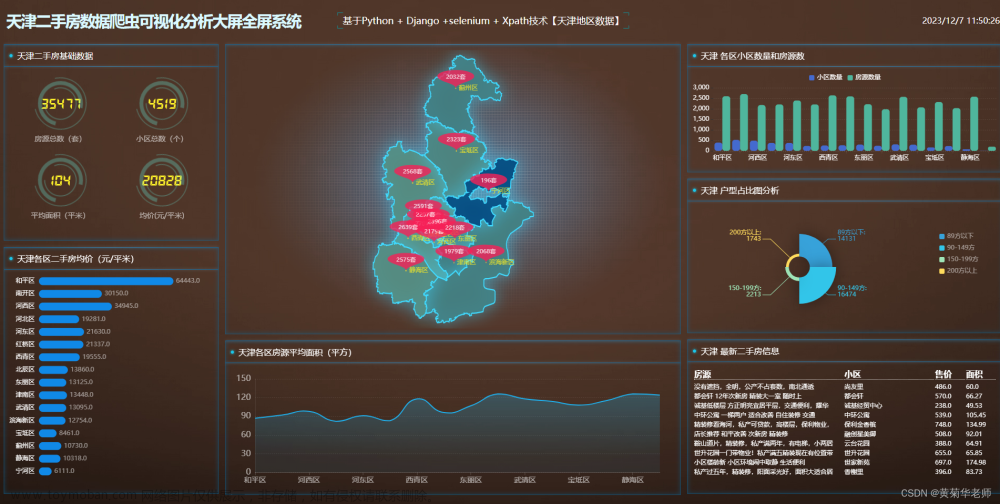
毕业设计开题报告:基于Python的网络爬虫电商数据采集系统设计与实现
一、研究背景与意义
随着互联网的快速发展,电商行业在全球范围内得到了广泛的应用。各大电商平台提供了丰富的商品信息,但这些信息分布广泛且数据量大,给商家和消费者带来了诸多困扰。例如,商家需要花费大量时间和精力去收集和分析市场数据,以制定更有效的商业策略;消费者也需要方便快捷地获取电商平台的商品信息,以便做出更明智的购买决策。因此,如何高效地采集、处理和分析电商数据成为一个亟待解决的问题。
针对这一问题,本研究旨在设计和实现一个基于Python的网络爬虫电商数据采集系统,通过对各大电商平台的商品信息进行自动化采集和处理,为商家和消费者提供及时、准确、全面的数据支持。该系统的成功实现将具有以下意义:
- 为商家提供市场分析依据:系统可以自动采集和分析各大电商平台的销售数据、用户评价等关键信息,帮助商家更好地了解市场趋势和消费者需求,为制定商业策略提供科学依据。
- 提高消费者购买效率:消费者可以通过系统快速获取各大电商平台的商品信息,包括价格、销量、评价等指标,从而更加全面地了解产品情况,提高购买决策的效率和满意度。
- 探索大数据技术在电商领域的应用:通过设计和实现该系统,可以进一步探索大数据技术在电商领域的应用前景,为未来电商行业的发展提供新的思路和方法。
二、国内外研究现状
近年来,国内外对于电商数据采集和分析的研究日益增多。一些大型电商平台已经自行开发了内部数据采集和分析系统,以便更好地利用大数据技术进行商业决策。同时,一些第三方研究机构和企业也开始涉足这一领域,推出了一些针对电商数据的采集和分析工具。
在学术界,电商数据采集和分析的研究主要集中在数据挖掘、自然语言处理、机器学习等领域。例如,一些研究利用爬虫技术自动化采集电商平台的商品信息,并利用数据挖掘和机器学习算法对采集到的数据进行分类、聚类和预测等分析。此外,还有一些研究关注用户评论的情感分析、产品推荐等应用。
然而,目前的研究还存在一些问题:一方面,大部分研究仅关注某一特定电商平台的数据采集和分析,无法满足多平台数据采集和处理的需求;另一方面,现有的数据采集工具大多针对某一特定网站结构或数据格式,缺乏通用性和可扩展性。因此,本研究旨在设计和实现一个基于Python的网络爬虫电商数据采集系统,以解决现有研究的不足。
三、研究思路与方法
本研究将采用以下研究思路和方法:
- 调研电商平台的网页结构和数据格式:首先对各大电商平台的网页结构和数据格式进行调研,了解不同平台的数据特点和提取方式。
- 设计数据采集算法:根据不同电商平台的网页结构和数据格式,设计相应的数据采集算法,包括页面解析、数据提取和存储等环节。
- 实现数据采集和处理模块:根据设计的数据采集算法,利用Python编程语言实现数据采集和处理模块,包括网页请求、页面解析、数据提取和存储等功能。
- 开发用户界面:为了方便用户使用系统,将开发一个用户界面,包括数据展示、参数设置和操作日志等功能。
- 测试和优化系统:对系统进行测试和优化,包括数据采集的准确性和效率、系统的稳定性和可扩展性等方面。
- 分析采集到的电商数据:利用数据挖掘和机器学习算法对采集到的电商数据进行分类、聚类和预测等分析,为商家和消费者提供数据支持。
四、研究内容和创新点
本研究将围绕以下内容展开:
- 电商数据采集算法的设计与实现:针对不同电商平台的网页结构和数据格式,设计相应的数据采集算法,包括页面解析、数据提取和存储等环节。该算法应具有通用性和可扩展性,能够适应不同电商平台的数据采集需求。
- 数据采集和处理模块的实现:利用Python编程语言实现数据采集和处理模块,包括网页请求、页面解析、数据提取和存储等功能。该模块应具有良好的稳定性和可扩展性,能够高效地处理大量数据。
- 用户界面的设计与实现:开发一个用户界面,包括数据展示、参数设置和操作日志等功能,方便用户使用系统。该界面应具有良好的交互性和易用性,能够满足不同用户的需求。
- 电商数据的分析与应用:利用数据挖掘和机器学习算法对采集到的电商数据进行分类、聚类和预测等分析,为商家和消费者提供数据支持。该分析应具有科学性和实用性,能够为商家制定商业策略和消费者做出购买决策提供有力支持。
本研究的创新点在于:
- 提出了一个通用的电商数据采集算法,能够适应不同电商平台的数据采集需求;
- 实现了稳定且可扩展的数据采集和处理模块,能够高效地处理大量数据;
- 开发了一个具有良好交互性和易用性的用户界面;
- 利用数据挖掘和机器学习算法对采集到的电商数据进行科学且实用的分析。
五、前后台功能详细介绍
本系统主要包括前台功能和后台功能两个部分。前台功能主要面向用户,提供了一个方便快捷的交互界面;后台功能主要面向管理员和系统开发者,提供了丰富的后台管理工具。
- 前台功能介绍:
(1)登录注册:用户可以通过登录注册功能使用系统。在注册时,用户需要输入用户名、密码等必要信息;在登录时,用户需要输入已注册的用户名和密码进行验证。该功能采用了常见的加密技术对用户密码进行加密处理以保证用户信息的安全性。同时采用了验证码技术防止暴力破解密码的情况发生。(2)商品列表:用户可以在商品列表页面查看所有商品的信息包括商品名称、价格、销量、评价等指标。(3)商品详情:用户可以点击商品列表中的某一个商品进入商品详情页面查看商品的详细信息。(4)订单管理:用户可以在订单管理页面查看自己购买的所有商品的信息包括订单号、购买时间、收货地址等指标以及进行订单状态的查询与修改操作。(5)个人中心:个人中心页面集中了用户的个人信息以及订单管理页面的全部功能方便用户快速查看自己的个人信息以及修改自己的收货地址等信息。(6)其他功能:系统还提供了收藏夹、购物车等功能方便用户进行商品的收藏以及购买商品的快速跳转与查询修改操作。 - 后台功能介绍:
(1)用户管理:管理员可以在后台管理页面查看所有用户的个人信息以及进行用户的添加与删除操作。(2)商品管理:管理员可以在后台管理页面查看所有商品的信息并对商品进行添加与删除操作。(3)订单管理:管理员可以在后台管理页面查看所有订单的信息并对订单进行查询与修改操作。(4)系统设置:管理员可以在系统设置页面进行系统的相关设置包括系统名称设置网站配置等信息。(5)日志管理:管理员可以在日志管理页面查看系统的操作记录以及进行日志的删除操作保证系统的安全性。(6)其他功能:后台管理还提供了参数设置等功能方便管理员进行系统的相关设置以及查看系统的运行状态等信息保证系统的正常运行。
六、研究思路与研究方法、可行性
本研究将采用以下研究思路和方法:
- 研究思路:首先对人脸识别技术和考勤签到系统进行深入调研,明确研究目标和研究方向;然后进行需求分析和实地考察,了解用户需求和市场现状;接着设计系统的架构和功能模块,并进行技术实现;最后对系统进行测试和优化,完成整个系统的设计和实现。
- 研究方法:本研究将采用文献调研、需求分析、实地考察、系统设计和实现等方法,其中系统设计和实现是本研究的核心部分。
- 可行性:本研究基于百度智能AI接口,利用现有的人脸识别技术和软件开发技术,设计和实现一个基于人脸识别技术的考勤签到系统。考虑到百度智能AI接口的强大功能和现有的技术条件,本研究的可行性较高。
七、研究进度安排文章来源地址https://www.toymoban.com/news/detail-764040.html
本研究将分为以下几个阶段进行:
- 第一阶段:文献调研和需求分析(1-2个月)。主要任务是对人脸识别技术和考勤签到系统进行深入调研,明确研究目标和研究方向,同时进行需求分析和实地考察,了解用户需求和市场现状。
- 第二阶段:系统设计和实现(3-4个月)。主要任务是根据需求分析和实地考察的结果,设计和实现一个包括人脸识别、图像处理、数据存储、手机APP端和后台管理等功能模块的考勤签到系统。
- 第三阶段:系统测试和优化(1-2个月)。主要任务是对系统进行测试和优化,保证系统的准确性和稳定性。同时进行数据统计和分析,了解用户的签到情况和统计数据。
- 第四阶段:论文写作和整理(2-3个月)。主要任务是整理研究成果,撰写毕业论文。同时进行与导师和相关专家的交流和讨论,完善论文质量。
八、主要参考文献
[此处列出主要参考文献]
一、研究背景与意义 随着电子商务的快速发展,越来越多的企业将业务转移到了互联网,而互联网上的电商平台成为了人们进行购物的重要途径。为了更好地服务于消费者,电商企业需要了解消费者的需求,跟踪市场变化,同时也需要与同行竞争,提高产品的质量和售卖效率。因此,如何获取更多准确的电商数据,分析数据以提高营销和运营效率,成为了电商企业迫切需要解决的问题。
针对这个问题,网络爬虫技术能够有效地帮助企业从互联网上采集大量的数据,进行数据分析与挖掘。而Python作为一门易学易用的高级编程语言,具有强大的网络爬虫库,能够方便地实现网络爬虫程序的设计和开发。因此,本毕业设计拟设计并实现一款基于Python的网络爬虫电商数据采集系统,以满足企业对于电商数据的需求,提高营销和运营效率。
二、国内外研究现状 网络爬虫作为一种获取互联网信息的技术手段,已经得到了广泛的应用。国内外已经涌现出了许多基于网络爬虫的数据采集系统,如美国的Google搜索引擎、中国的百度搜索引擎等。在电商领域,也有一些基于网络爬虫的数据采集系统,如美国的Zappos、Walmart、Amazon等电商企业都有自己的网络爬虫数据采集系统。国内的淘宝、京东、苏宁等电商企业也通过网络爬虫技术采集数据,以提高自身的业务水平和竞争力。
在网络爬虫技术方面,国内外研究者已经做出了很多有意义的探索和研究。国内的研究主要集中在网络爬虫技术的理论研究和实现方法研究方面,如基于网络爬虫的数据挖掘方法、基于XPath的网络爬虫技术、基于Python的网络爬虫框架Scrapy等。在国外,研究者主要围绕网络爬虫的应用展开研究,如搜索引擎的设计与实现、电商数据采集系统的设计和实现等。
但是目前仍然存在着一些问题,如网络爬虫过程中容易被反爬虫技术识别、数据的准确性难以保证等。因此,本毕业设计也将会针对这些问题进行探讨与解决。
三、研究思路与方法 本毕业设计拟设计并实现一款基于Python的网络爬虫电商数据采集系统。该系统主要包括前台用户界面和后台管理界面两部分。
前台用户界面主要用于提供搜索商品、浏览商品、下订单等功能。在实现搜索功能时,采用关键词匹配的方式,获取相应的商品列表,并提供价格、评价等相关信息。当用户选择商品并下单时,将需要填写的用户信息发送给后台进行处理。
后台管理界面主要用于爬虫任务的管理和权限的设置。在爬虫任务管理部分,管理员可以添加、删除、修改和查询任务的信息。在权限设置部分,管理员可以设置不同用户的权限,以限制其对于系统的访问和操作范围。
在具体实现中,本毕业设计将采用Scrapy框架进行开发。Scrapy是一个基于Python的网络爬虫框架,支持异步编程和分布式爬虫,适合实现大规模数据采集。
为了提高爬取效率和避免反爬虫机制的干扰,本毕业设计还将采用一些优化策略,如设置随机访问时间间隔、使用多个IP代理等。
四、研究内客和创新点 本毕业设计的研究内客主要是基于Python的网络爬虫电商数据采集系统的设计与实现。创新点主要体现在以下几个方面:
- 综合应用Scrapy框架、IP代理等技术手段,实现高效、稳定、可扩展的网络爬虫程序;
- 设计前后台界面,提供搜索商品、浏览商品、下订单等功能,提高用户体验;
- 通过权限设置和数据安全处理等措施,保障系统数据的安全性和稳定性。
五、前后台功能详细介绍 (1)前台用户界面
前台用户界面主要包括搜索、浏览商品、下订单等功能。用户可以通过输入关键词进行搜索,获取相应的商品列表。当用户选择一个商品进行查看时,可以看到价格、评价等相关信息。当用户决定购买时,需要填写相应的用户信息,包括姓名、电话、收货地址等,然后点击下单即可。
(2)后台管理界面
后台管理界面主要包括爬虫任务管理和权限设置两部分。在爬虫任务管理中,管理员可以添加、删除、修改和查询任务的信息,包括任务名称、爬取的网站、爬取的数据等。在权限设置中,管理员可以设置不同用户的权限,以限制其对于系统的访问和操作范围。
六、研究思路与研究方法、可行性 本毕业设计的研究思路是基于Python的网络爬虫技术,以Scrapy框架为基础,实现电商数据的采集和分析。研究方法主要包括系统设计、数据采集与分析、优化策略等方面。
本毕业设计的可行性较高,主要基于以下几点:文章来源:https://www.toymoban.com/news/detail-764040.html
- Python作为一门易学易用的高级编程语言,具有强大的网络爬虫库,适合实现网络爬虫程序的设计和开发;
- Scrapy是一个基于Python的网络爬虫框架,支持异步编程和分布式爬虫,适合实现大规模数据采集;
- 网络爬虫是一种成熟的技术手段,已经得到广泛的应用,因此其技术可行性较高。
七、研究进度安排
- 确定项目研究方向和设计思路,完成开题报告和开题答辩;
- 研究Scrapy框架的使用和相关知识;
- 实现前台用户界面,包括搜索商品、浏览商品、下订单等功能;
- 实现后台管理界面,包括爬虫任务管理和权限设置等功能;
- 研究网络爬虫数据采集优化策略,如随机访问时间间隔、IP代理等;
- 收集、存储和分析采集到的数据
到了这里,关于基于Python的网络爬虫电商数据采集系统设计与实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!