Python提供了 with 语句的写法,既简单又安全。
文件操作的时候使用with语句可以自动调用关闭文件操作,即使出现异常也会自动关闭文件操作。
# 1、以写的方式打开文件
with open('1.txt', 'w') as f:
# 2、读取文件内容
f.write('hello world')生成器的创建方式
生成器推导式
与列表推导式类似,只不过生成器推导式使用小括号 。
# 创建生成器
my_generator = (i * 2 for i in range(5))
print(my_generator)
# next获取生成器下一个值
# value = next(my_generator)
# print(value)
# 遍历生成器
for value in my_generator:
print(value)next 函数获取生成器中的下一个值
for 循环遍历生成器中的每一个值
yield生成器
yield 关键字生成器的特征:在def函数中具有yield关键字
def generator(n):
for i in range(n):
print('开始生成...')
yield i
print('完成一次...')
g = generator(5)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g)) -----> 正常
print(next(g)) -----> 报错
Traceback (most recent call last):
File "/Users/cndws/PycharmProjects/pythonProject/demo.py", line 14, in <module>
print(next(g))
StopIterationdef generator(n):
for i in range(n):
print('开始生成...')
yield i
print('完成一次...')
g = generator(5)
for i in g:
print(i)开始生成...
0
完成一次...
开始生成...
1
完成一次...
开始生成...
2
完成一次...
开始生成...
3
完成一次...
开始生成...
4
完成一次...
注意点:
① 代码执行到 yield 会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
② 生成器如果把数据生成完成,再次获取生成器中的下一个数据会抛出一个StopIteration 异常,表示停止迭代异常
③ while 循环内部没有处理异常操作,需要手动添加处理异常操作
④ for 循环内部自动处理了停止迭代异常
yield关键字和return关键字
如果不太好理解yield,可以先把yield当作return,他们都在函数中使用,并履行着返回某种结果的职责。
这两者的区别是:
有return的函数直接返回所有结果,程序终止不再运行,并销毁局部变量;
而有yield的函数则返回一个可迭代的 generator(生成器)对象,可以使用for循环或者调用next()方法遍历生成器对象来提取结果。
def example():
x = 1
y = 10
while x < y:
yield x
x += 1
example = example()
print(example)yield与斐波那契数列
数学中有个著名的斐波拉契数列)
要求:数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:
例子:1, 1, 2, 3, 5, 8, 13, 21, 34, ...
现在我们使用生成器来实现这个斐波那契数列,每次取值都通过算法来生成下一个数据,生成器每次调用只生成一个数据,可以节省大量的内存。
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b # 使用 yield
# print b
a, b = b, a + b
n = n + 1
for n in fib(5):
print n什么是正则表达式
正则表达式描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
模式:一种特定的字符串模式,这个模式是通过一些特殊的符号组成的。 某种:也可以理解为是一种模糊匹配。
精准匹配:select * from blog where title='python';
模糊匹配:select * from blog where title like ‘%python%’;
正则表达式并不是Python所特有的,在Java、PHP、Go以及JavaScript等语言中都是支持正则表达式的。
正则表达式的功能
① 数据验证(表单验证、如手机、邮箱、IP地址)
② 数据检索(数据检索、数据抓取)
③ 数据隐藏(1356235 王先生)
④ 数据过滤(论坛敏感关键词过滤)
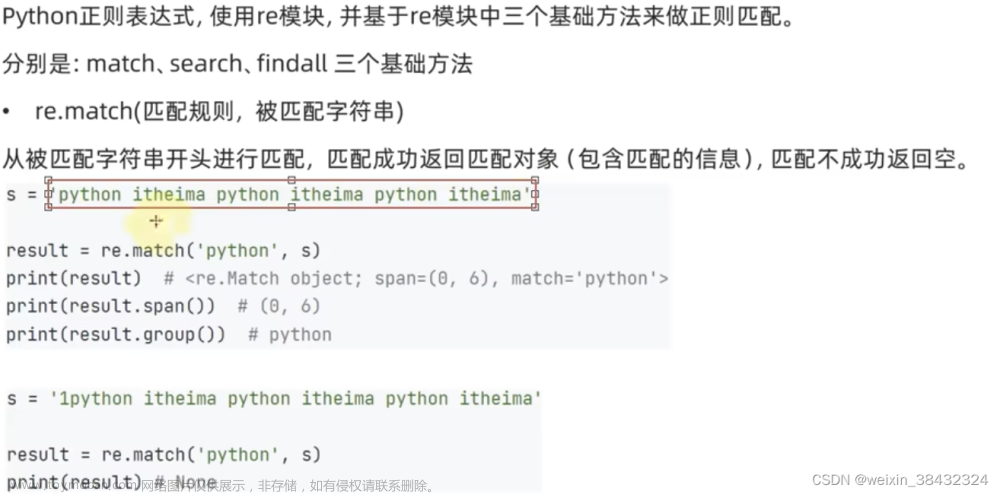
什么是re模块
在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个re模块
# 第一步:导入re模块
import re
# 第二步:使用match方法进行匹配操作
result = re.match(pattern正则表达式, string要匹配的字符串, flags=0)
# 第三步:如果数据匹配成功,使用group方法来提取数据
result.group()match函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配数据。
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配,这个功能是为了支持多语言版本的字符集使用环境的,比如在转义符\w,在英文环境下,它代表[a-zA-Z0-9_],即所以英文字符和数字。如果在一个法语环境下使用,缺省设置下,不能匹配"é" 或 "ç"。加上这L选项和就可以匹配了。不过这个对于中文环境似乎没有什么用,它仍然不能匹配中文字符。 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | VERBOSE,冗余模式, 此模式忽略正则表达式中的空白和#号的注释,例如写一个匹配邮箱的正则表达式。该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
re模块的相关方法
re.match(pattern, string, flags=0)
-
从字符串的起始位置匹配,如果匹配成功则返回匹配内容, 否则返回None
☆ re.findall(pattern, string, flags=0)
-
扫描整个串,返回所有与pattern匹配的列表
-
注意: 如果pattern中有分组则返回与分组匹配的列表
-
举例:
re.findall("\d","chuan1zhi2") >> ["1","2"]
☆ re.finditer(pattern, string, flags)
-
功能与上面findall一样,不过返回的时迭代器
参数说明:
-
pattern : 模式字符串。
-
repl : 替换的字符串,也可为一个函数。
-
string : 要被查找替换的原始字符串。
-
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
-
flags: 匹配方式:
-
re.I 使匹配对大小写不敏感,I代表Ignore忽略大小写
-
re.S 使 . 匹配包括换行在内的所有字符
-
re.M 多行模式,会影响^,$
-
案例1:查找一个字符串中是否具有数字“8”
import re
result = re.findall('8', '13566128753')
# print(result)
if result:
print(result)
else:
print('未匹配到任何数据')案例2:查找一个字符串中是否具有数字
import re
result = re.findall('\d', 'a1b2c3d4f5')
# print(result)
if result:
print(result)
else:
print('未匹配到任何数据')案例3:查找一个字符串中是否具有非数字
import re
result = re.findall('\D', 'a1b2c3d4f5')
# print(result)
if result:
print(result)
else:
print('未匹配到任何数据')正则表达式编写:查什么、查多少、从哪查
1、查什么
| 代码 | 功能 |
|---|---|
| .(英文点号) | 匹配任意1个字符(除了\n) |
| [ ] | 匹配[ ]中列举的某个字符,专业名词 => 字符簇 |
| [^指定字符] | 匹配除了指定字符以外的其他某个字符,^专业名词 => 托字节 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即 空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配非特殊字符,即a-z、A-Z、0-9、_ |
| \W | 匹配特殊字符,即非字母、非数字、非下划线 |
字符簇常见写法:
① [abcdefg] 代表匹配abcdefg字符中的任意某个字符(1个)
② [aeiou] 代表匹配a、e、i、o、u五个字符中的任意某个字符
③ [a-z] 代表匹配a-z之间26个字符中的任意某个
④ [A-Z] 代表匹配A-Z之间26个字符中的任意某个
⑤ [0-9] 代表匹配0-9之间10个字符中的任意某个
⑥ [0-9a-zA-Z] 代表匹配0-9之间、a-z之间、A-Z之间的任意某个字符
字符簇 + 托字节结合代表取反的含义:
① [^aeiou] 代表匹配除了a、e、i、o、u以外的任意某个字符
② [^a-z] 代表匹配除了a-z以外的任意某个字符
\d 等价于 [0-9], 代表匹配0-9之间的任意数字
\D 等价于 [^0-9],代表匹配非数字字符,只能匹配1个
2、查多少
| 代码 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无(0到多) |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次(1到多) |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有(0或1) |
| {m} | 匹配前一个字符出现m次,匹配手机号码\d{11} |
| {m,} | 匹配前一个字符至少出现m次,\w{3,},代表前面这个字符最少要出现3次,最多可以是无限次 |
| {m,n} | 匹配前一个字符出现从m到n次,\w{6,10},代表前面这个字符出现6到10次 |
基本语法:
正则匹配字符.或\w或\S + 跟查多少
如\w{6, 10}
如.*,匹配前面的字符出现0次或多次
3、从哪查
| 代码 | 功能 |
|---|---|
| ^ | 匹配以某个字符串开头 |
| $ | 匹配以某个字符串结尾 |
正则工具箱 :文章来源:https://www.toymoban.com/news/detail-764093.html
正则表达式代码生成工具 等文章来源地址https://www.toymoban.com/news/detail-764093.html
到了这里,关于Python高级语法与正则表达式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!