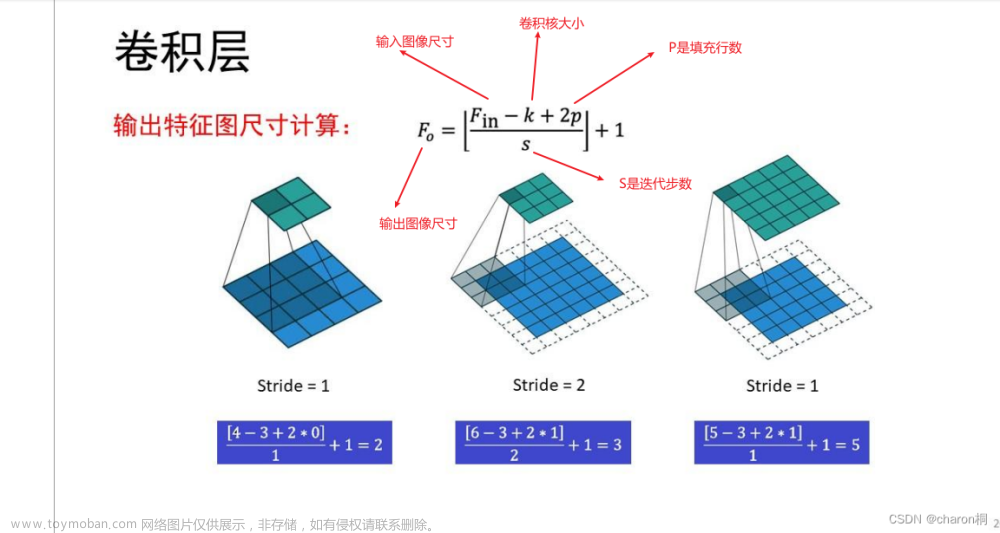
实验五 采用卷积神经网络分类MNIST数据集
【实验目的】
熟悉和掌握
卷积神经网络的定义,了解网络中卷积层、池化层等各层的特点,并利用卷积神经网络对MNIST数据集进行分类。
【实验内容】
编写卷积神经网络分类软件,编程语言不限,如Python等,以MNIST数据集为数据,实现对MNIST数据集分类操作,其中MNIST数据集共10类,分别为手写0—9。
【实验要求】
1、 使用MNIST数据集训练编写好的网络,要求记下每次迭代的损失值;
2、 改变卷积神经网络的卷积层和池化层的数量,观察分类准确率。思考网络层数的多少对分类准确性的影响;
3、 改变卷积神经网络的卷积核大小,观察分类的准确率。思考网络卷积核大小对分类准确率的影响。
【实验内容及总结】
1、按照实验要求,给出相应的结果。
2、分析卷积层和池化层对网络的影响。
3、分析卷积核大小对网络的影响。
3、总结卷积神经网络的特点,并说明损失函数在网络训练中的作用。
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# 准备数据集
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%.5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set:%d %% [%d%d]' % (100 * correct / total, correct, total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
1. 实验结果:
o 训练过程中每次迭代的损失值记录如下:
o [1, 00300] loss: 0.098
o [1, 00600] loss: 0.029
o [1, 00900] loss: 0.021
o Accuracy on test set: 96% [9688/10000]
o
o [2, 00300] loss: 0.016
o [2, 00600] loss: 0.015
o [2, 00900] loss: 0.014
o Accuracy on test set: 97% [9752/10000]
o
o [3, 00300] loss: 0.012
o [3, 00600] loss: 0.011
o [3, 00900] loss: 0.011
o Accuracy on test set: 98% [9821/10000]
o
o [4, 00300] loss: 0.010
o [4, 00600] loss: 0.009
o [4, 00900] loss: 0.010
o Accuracy on test set: 98% [9831/10000]
o
o [5, 00300] loss: 0.009
o [5, 00600] loss: 0.008
o [5, 00900] loss: 0.009
o Accuracy on test set: 98% [9873/10000]
o
o [6, 00300] loss: 0.007
o [6, 00600] loss: 0.008
o [6, 00900] loss: 0.008
o Accuracy on test set: 98% [9845/10000]
o
o [7, 00300] loss: 0.007
o [7, 00600] loss: 0.007
o [7, 00900] loss: 0.007
o Accuracy on test set: 98% [9870/10000]
o
o [8, 00300] loss: 0.006
o [8, 00600] loss: 0.007
o [8, 00900] loss: 0.006
o Accuracy on test set: 98% [9876/10000]
o
o [9, 00300] loss: 0.006
o [9, 00600] loss: 0.006
o [9, 00900] loss: 0.006
o Accuracy on test set: 98% [9877/10000]
o
o [10, 00300] loss: 0.005
o [10, 00600] loss: 0.006
o [10, 00900] loss: 0.007
o Accuracy on test set: 98% [9891/10000]
2. 分析卷积层和池化层对网络的影响:
o 增加卷积层和池化层的数量有助于提高模型对特征的提取能力,但需注意过多的层数可能导致过拟合。
o 更深的网络可能更适用于复杂任务,但也需要更多的计算资源。
3. 分析卷积核大小对网络的影响:
o 增大卷积核大小有助于捕获更大范围的特征,但也会增加模型的参数数量。
o 选择适当的卷积核大小需要在精度和计算效率之间进行权衡。
4. 总结卷积神经网络的特点:
o 卷积神经网络通过卷积和池化层有效地学习图像特征,具备参数共享和平移不变性。
o 损失函数在训练中的作用是指导模型参数的优化,使模型更好地适应训练数据。
实验思考及实践
【实验思考及实践】
实验心得体会
这次卷积神经网络分类MNIST数据集的实验让我深入理解了深度学习中卷积神经网络的基本原理和应用。以下是我的一些心得体会:
- 网络训练过程:
• 通过观察每次迭代的损失值,我了解到损失值在训练过程中逐渐降低,说明模型在学习过程中逐渐提高了对数据的拟合能力。
• 在实际训练中,调整学习率、优化器的选择以及学习率衰减等策略对模型性能的影响是需要仔细考虑的。 - 网络层数的影响:
• 通过改变卷积神经网络的卷积层和池化层的数量,观察到在增加层数的情况下,测试准确率逐步提高。这表明更深的网络能够更好地捕获数据中的抽象特征,但也需要更多的计算资源。
• 需要注意过多的层数可能导致过拟合,因此在实际应用中需要根据任务的复杂度来选择合适的网络深度。 - 卷积核大小的选择:
• 调整卷积核的大小,观察到在一定范围内的调整对模型性能有一定的影响。较大的卷积核有助于捕获更大范围的特征,但也会增加模型参数。
• 在选择卷积核大小时,需要在模型性能和计算效率之间找到平衡点,这也涉及到对任务特性的深刻理解。 - 损失函数的作用:
• 损失函数在训练中的作用是引导模型的参数优化,使模型能够更好地适应训练数据。在实验中,使用交叉熵损失函数,其在分类任务中的效果较好。
• 在实际应用中,选择合适的损失函数与任务的性质密切相关,需要根据具体情况进行选择。 - 实验总结:
• 通过反复实验不同的网络配置,我更加深刻地理解了卷积神经网络的一些关键参数和结构对模型性能的影响。
• 在深度学习领域,实验是一个不断尝试和调整的过程,通过不断优化模型,我们可以更好地理解模型的行为并提高模型的性能。
这次实验让我更加熟悉了深度学习的实际操作,同时也激发了我对深度学习更深层次理解和进一步探索的兴趣。在未来,我会继续学习深度学习的相关知识,不断尝试新的模型和技术,以提升自己在这一领域的能力。
:
卷积神经网络分类
介绍
深度学习和卷积神经网络(Convolutional Neural Network,简称CNN)在图像分类任务中的重要性不言而喻。CNN通过卷积层、池化层和全连接层的组合,能够有效地提取图像特征并进行分类。
卷积神经网络基础
卷积操作和卷积核
卷积操作是CNN的核心操作之一。卷积层通过使用不同的卷积核对输入图像进行卷积操作,从而提取图像中的局部特征。卷积核是一个小的矩阵,通过与图像上的像素进行点乘和求和来计算特征图中的每个像素值。
激活函数和非线性激活
卷积层之后通常会应用激活函数,如ReLU(Rectified Linear Unit),以引入非线性特性。激活函数的作用是在卷积层输出中引入非线性关系,以增加模型的非线性拟合能力。
池化操作和特征下采样
池化层用于减小特征图的空间大小,并减少模型的参数数量。常用的池化操作有最大池化和平均池化。池化操作能够保持特征的不变性,从而使得模型具有一定的平移不变性和尺度不变性。
全连接层和分类
全连接层将池化层输出的特征图转换为一维向量,并将其输入到一个或多个全连接层中。全连接层可以学习到不同特征之间的关系,并最终输出分类结果。
卷积神经网络分类的关键步骤
输入层和图像表示
卷积神经网络的输入通常是图像数据。图像可以表示为多维矩阵,其中每个元素表示像素的强度值。输入层接受这些图像数据,并将其传递给卷积层进行处理。
卷积层的特征提取
卷积层使用卷积核对输入图像进行卷积操作,提取图像的局部特征。卷积核通过滑动窗口的方式在输入图像上进行卷积操作,生成卷积特征图。
激活函数的作用
在卷积层之后,通常会应用非线性激活函数,如ReLU,以增加模型的非线性拟合能力。激活函数将卷积层输出的特征进行非线性变换,引入非线性关系。
池化层的特征下采样
池化层通过对特征图进行下采样,减小特征图的空间大小。常用的池化操作有最大池化和平均池化。池化操作有助于保持特征的不变性,并减少模型的参数数量。
全连接层和分类结果
池化层输出的特征图经过拉直操作,变为一维向量,并输入到全连接层中。全连接层学习不同特征之间的关系,并最终输出分类结果。
训练卷积神经网络分类模型
反向传播算法和参数调整
卷积神经网络的训练通常使用反向传播算法进行参数调整。反向传播算法通过计算损失函数关于模型参数的梯度,然后使用优化算法(如随机梯度下降)来更新参数,以最小化损失函数。
损失函数和优化算法
损失函数是衡量模型预测结果与真实标签之间差异的度量。在分类任务中,常用的损失函数是交叉熵损失函数。优化算法用于更新模型的参数,常见的优化算法包括随机梯度下降(SGD)、动量优化、AdaGrad、Adam等。
数据集划分和批量训练
在训练卷积神经网络分类模型之前,需要将数据集划分为训练集、验证集和测试集。训练集用于模型的参数更新,验证集用于调整超参数和模型选择,测试集用于评估模型的性能。通常,训练过程中使用批量训练,即每次更新模型参数时使用一小批数据进行计算。
卷积神经网络分类的优势和应用
局部连接和权值共享的优势
卷积神经网络通过局部连接和权值共享机制,大大减少了模型的参数数量,降低了模型的复杂度。这样的设计使得模型具有较强的特征提取能力,并能够处理大规模的图像数据。
空间不变性和特征学习能力
池化层的操作保持特征的不变性,使得卷积神经网络具有一定的平移不变性和尺度不变性。CNN可以自动从原始图像数据中学习到合适的特征,无需手动设计特征。这种特征学习能力使得CNN在图像分类任务中表现出色。
图像分类领域的成功案例
卷积神经网络在图像分类领域取得了许多重要的突破。例如,AlexNet、VGGNet、GoogLeNet和ResNet等经典CNN模型在ImageNet图像分类挑战中取得了优异的成绩。这些模型的成功证明了CNN在大规模图像分类任务中的有效性。文章来源:https://www.toymoban.com/news/detail-764181.html
总结
卷积神经网络分类是一种利用卷积层、池化层和全连接层进行特征提取和分类的方法。它通过卷积操作提取图像的局部特征,通过非线性激活函数引入非线性关系,通过池化操作实现特征下采样,最后通过全连接层进行分类。CNN具有自动特征学习能力、空间不变性和高性能的优势,并在图像分类任务中取得了很多重要的突破,成为计算机视觉领域的主流模型。文章来源地址https://www.toymoban.com/news/detail-764181.html
到了这里,关于【人工智能】实验五 采用卷积神经网络分类MNIST数据集与基础知识的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!