1.训练好的pt模型转换为onnx格式
使用yolov5-lite自带的export.py导出onnx格式,图像大小设置320,batch 1
之后可以使用 onnxsim对模型进一步简化
onnxsim参考链接:onnxsim-让导出的onnx模型更精简_alex1801的博客-CSDN博客
python export.py --weights weights/v5lite-e.pt --img 320 --batch 1
python -m onnxsim weights/v5lite-e.onnx weights/yolov5-lite-sim.onnx2.使用onnxruntime调用onnx模型实时推理(python版本
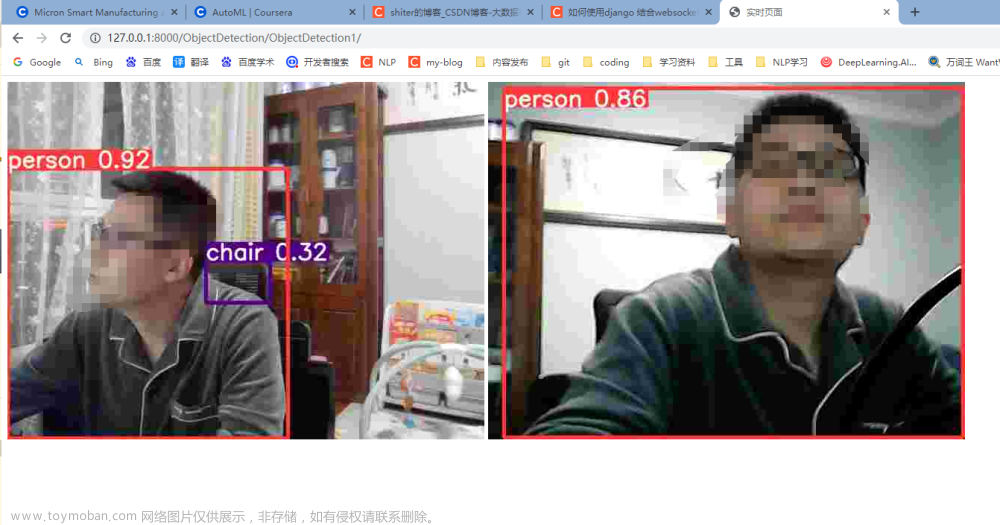
这个版本的推理FPS能有11+FPS
这两处换成自己的模型和训练的类别即可:
parser.add_argument('--modelpath', type=str, default="/media/xcy/dcd05f09-46df-4879-bfeb-3bab03a6cc3a/YOLOv5-Lite/weights/v5lite-e.onnx",
help="onnx filepath")
parser.add_argument('--classfile', type=str, default='coco.names',
help="classname filepath")
参考github:GitHub - hpc203/yolov5-lite-onnxruntime: 使用ONNXRuntime部署yolov5-lite目标检测,包含C++和Python两个版本的程序
import cv2
import numpy as np
import argparse
import onnxruntime as ort
import time
class yolov5_lite():
def __init__(self, model_pb_path, label_path, confThreshold=0.5, nmsThreshold=0.5, objThreshold=0.5):
so = ort.SessionOptions()
so.log_severity_level = 3
self.net = ort.InferenceSession(model_pb_path, so)
self.classes = list(map(lambda x: x.strip(), open(label_path, 'r').readlines()))
self.num_classes = len(self.classes)
anchors = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
self.nl = len(anchors)
self.na = len(anchors[0]) // 2
self.no = self.num_classes + 5
self.grid = [np.zeros(1)] * self.nl
self.stride = np.array([8., 16., 32.])
self.anchor_grid = np.asarray(anchors, dtype=np.float32).reshape(self.nl, -1, 2)
self.confThreshold = confThreshold
self.nmsThreshold = nmsThreshold
self.objThreshold = objThreshold
self.input_shape = (self.net.get_inputs()[0].shape[2], self.net.get_inputs()[0].shape[3])
def resize_image(self, srcimg, keep_ratio=True):
top, left, newh, neww = 0, 0, self.input_shape[0], self.input_shape[1]
if keep_ratio and srcimg.shape[0] != srcimg.shape[1]:
hw_scale = srcimg.shape[0] / srcimg.shape[1]
if hw_scale > 1:
newh, neww = self.input_shape[0], int(self.input_shape[1] / hw_scale)
img = cv2.resize(srcimg, (neww, newh), interpolation=cv2.INTER_AREA)
left = int((self.input_shape[1] - neww) * 0.5)
img = cv2.copyMakeBorder(img, 0, 0, left, self.input_shape[1] - neww - left, cv2.BORDER_CONSTANT,
value=0) # add border
else:
newh, neww = int(self.input_shape[0] * hw_scale), self.input_shape[1]
img = cv2.resize(srcimg, (neww, newh), interpolation=cv2.INTER_AREA)
top = int((self.input_shape[0] - newh) * 0.5)
img = cv2.copyMakeBorder(img, top, self.input_shape[0] - newh - top, 0, 0, cv2.BORDER_CONSTANT, value=0)
else:
img = cv2.resize(srcimg, self.input_shape, interpolation=cv2.INTER_AREA)
return img, newh, neww, top, left
def _make_grid(self, nx=20, ny=20):
xv, yv = np.meshgrid(np.arange(ny), np.arange(nx))
return np.stack((xv, yv), 2).reshape((-1, 2)).astype(np.float32)
def postprocess(self, frame, outs, pad_hw):
newh, neww, padh, padw = pad_hw
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
ratioh, ratiow = frameHeight / newh, frameWidth / neww
# Scan through all the bounding boxes output from the network and keep only the
# ones with high confidence scores. Assign the box's class label as the class with the highest score.
classIds = []
confidences = []
boxes = []
for detection in outs:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > self.confThreshold and detection[4] > self.objThreshold:
center_x = int((detection[0] - padw) * ratiow)
center_y = int((detection[1] - padh) * ratioh)
width = int(detection[2] * ratiow)
height = int(detection[3] * ratioh)
left = int(center_x - width / 2)
top = int(center_y - height / 2)
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
# Perform non maximum suppression to eliminate redundant overlapping boxes with
# lower confidences.
indices = cv2.dnn.NMSBoxes(boxes, confidences, self.confThreshold, self.nmsThreshold)
for i in indices:
i = i[0] if isinstance(i, (tuple, list)) else i
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
frame = self.drawPred(frame, classIds[i], confidences[i], left, top, left + width, top + height)
return frame
def drawPred(self, frame, classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), thickness=4)
label = '%.2f' % conf
label = '%s:%s' % (self.classes[classId], label)
# Display the label at the top of the bounding box
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
# cv.rectangle(frame, (left, top - round(1.5 * labelSize[1])), (left + round(1.5 * labelSize[0]), top + baseLine), (255,255,255), cv.FILLED)
cv2.putText(frame, label, (left, top - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), thickness=2)
return frame
def detect(self, srcimg):
img, newh, neww, top, left = self.resize_image(srcimg)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
outs = self.net.run(None, {self.net.get_inputs()[0].name: blob})[0].squeeze(axis=0)
row_ind = 0
for i in range(self.nl):
h, w = int(self.input_shape[0] / self.stride[i]), int(self.input_shape[1] / self.stride[i])
length = int(self.na * h * w)
if self.grid[i].shape[2:4] != (h, w):
self.grid[i] = self._make_grid(w, h)
outs[row_ind:row_ind + length, 0:2] = (outs[row_ind:row_ind + length, 0:2] * 2. - 0.5 + np.tile(
self.grid[i], (self.na, 1))) * int(self.stride[i])
outs[row_ind:row_ind + length, 2:4] = (outs[row_ind:row_ind + length, 2:4] * 2) ** 2 * np.repeat(
self.anchor_grid[i], h * w, axis=0)
row_ind += length
srcimg = self.postprocess(srcimg, outs, (newh, neww, top, left))
# cv2.imwrite('result.jpg', srcimg)
return srcimg
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--imgpath', type=str, default="",
help="image path")
parser.add_argument('--modelpath', type=str, default="/media/xcy/dcd05f09-46df-4879-bfeb-3bab03a6cc3a/YOLOv5-Lite/weights/v5lite-e.onnx",
help="onnx filepath")
parser.add_argument('--classfile', type=str, default='coco.names',
help="classname filepath")
parser.add_argument('--confThreshold', default=0.5, type=float, help='class confidence')
parser.add_argument('--nmsThreshold', default=0.6, type=float, help='nms iou thresh')
args = parser.parse_args()
# srcimg = cv2.imread(args.imgpath)
# print(args.imgpath,srcimg)
net = yolov5_lite(args.modelpath, args.classfile, confThreshold=args.confThreshold, nmsThreshold=args.nmsThreshold)
print(net)
counter = 0
start_time = time.time()
# 1 加载视频文件
capture = cv2.VideoCapture(0)
# 2 读取视频
ret, frame = capture.read()
fps = capture.get(cv2.CAP_PROP_FPS) # 视频平均帧率
while ret:
counter += 1 # 计算帧数
if (time.time() - start_time) != 0: # 实时显示帧数
cv2.putText(frame, "FPS {0}".format(float('%.1f' % (counter / (time.time() - start_time)))), (30, 50),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255),
2)
# 3 ret 是否读取到了帧,读取到了则为True
cv2.imshow("video", frame)
ret, frame = capture.read()
print("FPS: ", counter / (time.time() - start_time))
counter = 0
start_time = time.time()
srcimg = net.detect(frame)
# winName = 'Deep learning object detection in onnxruntime'
# cv2.namedWindow(winName, cv2.WINDOW_NORMAL)
# cv2.imshow(winName, srcimg)
# 4 若键盘按下q则退出播放
if cv2.waitKey(20) & 0xff == ord('q'):
break
# 5 释放资源
capture.release()
# 6 关闭所有窗口
cv2.destroyAllWindows()3.使用NCNN+opencv来读取模型实时推理(C++版本
此版本能够在笔记本上达到33+FPS,正在整理代码。后续发
代码整理好了,如下:需要VS2019配置ncnn之后即可运行。
LINUX配置NCNN可以参考我的另一篇博客:Ubuntu20.04配置NCNN推理框架(转换yolov5 onnx格式到ncnn格式-CSDN博客文章来源:https://www.toymoban.com/news/detail-764423.html
WINDOWS配置比较简单,大家搜一搜都能搜到。文章来源地址https://www.toymoban.com/news/detail-764423.html
#include "layer.h"
#include "net.h"
#if defined(USE_NCNN_SIMPLEOCV)
#include "simpleocv.h"
#else
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#endif
#include <float.h>
#include <stdio.h>
#include <vector>
#include<iostream>
#include <chrono>
//#define YOLOV5_V60 1 //YOLOv5 v6.0
#define YOLOV5_V62 1 //YOLOv5 v6.2 export onnx model method https://github.com/shaoshengsong/yolov5_62_export_ncnn
#if YOLOV5_V60 || YOLOV5_V62
#define MAX_STRIDE 64
#else
#define MAX_STRIDE 32
class YoloV5Focus : public ncnn::Layer
{
public:
YoloV5Focus()
{
one_blob_only = true;
}
virtual int forward(const ncnn::Mat& bottom_blob, ncnn::Mat& top_blob, const ncnn::Option& opt) const
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
int outw = w / 2;
int outh = h / 2;
int outc = channels * 4;
top_blob.create(outw, outh, outc, 4u, 1, opt.blob_allocator);
if (top_blob.empty())
return -100;
#pragma omp parallel for num_threads(opt.num_threads)
for (int p = 0; p < outc; p++)
{
const float* ptr = bottom_blob.channel(p % channels).row((p / channels) % 2) + ((p / channels) / 2);
float* outptr = top_blob.channel(p);
for (int i = 0; i < outh; i++)
{
for (int j = 0; j < outw; j++)
{
*outptr = *ptr;
outptr += 1;
ptr += 2;
}
ptr += w;
}
}
return 0;
}
};
DEFINE_LAYER_CREATOR(YoloV5Focus)
#endif //YOLOV5_V60 YOLOV5_V62
struct Object
{
cv::Rect_<float> rect;
int label;
float prob;
};
static inline float intersection_area(const Object& a, const Object& b)
{
cv::Rect_<float> inter = a.rect & b.rect;
return inter.area();
}
static void qsort_descent_inplace(std::vector<Object>& faceobjects, int left, int right)
{
int i = left;//下标0
int j = right; //下标最后一位
float p = faceobjects[(left + right) / 2].prob; //取一个中轴
while (i <= j)
{
while (faceobjects[i].prob > p) //如果前半段 的 大于 》 p
i++; //下标前移
while (faceobjects[j].prob < p) //如果后半段的小于 p
j--; // j往中间
if (i <= j)
{
// swap
std::swap(faceobjects[i], faceobjects[j]); //前半段的和后半段的交换
i++; // i前移
j--; // j往中间
}
}
#pragma omp parallel sections
{
#pragma omp section
{
if (left < j) qsort_descent_inplace(faceobjects, left, j);
}
#pragma omp section
{
if (i < right) qsort_descent_inplace(faceobjects, i, right);
}
}
}
static void qsort_descent_inplace(std::vector<Object>& faceobjects)
{
if (faceobjects.empty())
return;
qsort_descent_inplace(faceobjects, 0, faceobjects.size() - 1);
}
static void nms_sorted_bboxes(const std::vector<Object>& faceobjects, std::vector<int>& picked, float nms_threshold, bool agnostic = false)
{
picked.clear();
const int n = faceobjects.size();
std::vector<float> areas(n);
for (int i = 0; i < n; i++)
{
areas[i] = faceobjects[i].rect.area();
}
for (int i = 0; i < n; i++)
{
const Object& a = faceobjects[i];
int keep = 1;
for (int j = 0; j < (int)picked.size(); j++)
{
const Object& b = faceobjects[picked[j]];
if (!agnostic && a.label != b.label)
continue;
// intersection over union
float inter_area = intersection_area(a, b);
float union_area = areas[i] + areas[picked[j]] - inter_area;
// float IoU = inter_area / union_area
if (inter_area / union_area > nms_threshold)
keep = 0;
}
if (keep)
picked.push_back(i);
}
}
static inline float sigmoid(float x)
{
return static_cast<float>(1.f / (1.f + exp(-x)));
}
static void generate_proposals(const ncnn::Mat& anchors, int stride, const ncnn::Mat& in_pad, const ncnn::Mat& feat_blob, float prob_threshold, std::vector<Object>& objects)
{
const int num_grid = feat_blob.h;
int num_grid_x;
int num_grid_y;
if (in_pad.w > in_pad.h)
{
num_grid_x = in_pad.w / stride;
num_grid_y = num_grid / num_grid_x;
}
else
{
num_grid_y = in_pad.h / stride;
num_grid_x = num_grid / num_grid_y;
}
const int num_class = feat_blob.w - 5; //特征图的w是85 是类别 80 + xywh + 目标置信度
const int num_anchors = anchors.w / 2;
for (int q = 0; q < num_anchors; q++)
{
const float anchor_w = anchors[q * 2];
const float anchor_h = anchors[q * 2 + 1];
const ncnn::Mat feat = feat_blob.channel(q);
for (int i = 0; i < num_grid_y; i++)
{
for (int j = 0; j < num_grid_x; j++)
{
const float* featptr = feat.row(i * num_grid_x + j);
float box_confidence = sigmoid(featptr[4]);
if (box_confidence >= prob_threshold)
{
// find class index with max class score
int class_index = 0;
float class_score = -FLT_MAX;
for (int k = 0; k < num_class; k++)
{
float score = featptr[5 + k];
if (score > class_score)
{
class_index = k;
class_score = score;
}
}
float confidence = box_confidence * sigmoid(class_score);
if (confidence >= prob_threshold)
{
// yolov5/models/yolo.py Detect forward
// y = x[i].sigmoid()
// y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
// y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
float dx = sigmoid(featptr[0]);
float dy = sigmoid(featptr[1]);
float dw = sigmoid(featptr[2]);
float dh = sigmoid(featptr[3]);
float pb_cx = (dx * 2.f - 0.5f + j) * stride;
float pb_cy = (dy * 2.f - 0.5f + i) * stride;
float pb_w = pow(dw * 2.f, 2) * anchor_w;
float pb_h = pow(dh * 2.f, 2) * anchor_h;
float x0 = pb_cx - pb_w * 0.5f;
float y0 = pb_cy - pb_h * 0.5f;
float x1 = pb_cx + pb_w * 0.5f;
float y1 = pb_cy + pb_h * 0.5f;
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = class_index;
obj.prob = confidence;
objects.push_back(obj);
}
}
}
}
}
}
static int detect_yolov5(const cv::Mat& bgr, std::vector<Object>& objects, ncnn::Extractor ex)
{
const int target_size = 320;
const float prob_threshold = 0.25f;
const float nms_threshold = 0.45f;
int img_w = bgr.cols;
int img_h = bgr.rows;
// letterbox pad to multiple of MAX_STRIDE
int w = img_w;
int h = img_h;
float scale = 1.f;
if (w > h)
{
scale = (float)target_size / w;
w = target_size;
h = h * scale;
}
else
{
scale = (float)target_size / h;
h = target_size;
w = w * scale;
}
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR2RGB, img_w, img_h, w, h);
// pad to target_size rectangle
// yolov5/utils/datasets.py letterbox
int wpad = (w + MAX_STRIDE - 1) / MAX_STRIDE * MAX_STRIDE - w;
int hpad = (h + MAX_STRIDE - 1) / MAX_STRIDE * MAX_STRIDE - h;
ncnn::Mat in_pad;
ncnn::copy_make_border(in, in_pad, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 114.f);
const float norm_vals[3] = { 1 / 255.f, 1 / 255.f, 1 / 255.f };
in_pad.substract_mean_normalize(0, norm_vals);
/*ncnn::Extractor ex = yolov5.create_extractor();*/
ex.input("images", in_pad);
std::vector<Object> proposals;
// anchor setting from yolov5/models/yolov5s.yaml
// stride 8
{
ncnn::Mat out;
ex.extract("output", out);
ncnn::Mat anchors(6);
anchors[0] = 10.f;
anchors[1] = 13.f;
anchors[2] = 16.f;
anchors[3] = 30.f;
anchors[4] = 33.f;
anchors[5] = 23.f;
std::vector<Object> objects8;
generate_proposals(anchors, 8, in_pad, out, prob_threshold, objects8);
proposals.insert(proposals.end(), objects8.begin(), objects8.end());
}
// stride 16
{
ncnn::Mat out;
#if YOLOV5_V62
ex.extract("1111", out);
#elif YOLOV5_V60
ex.extract("376", out);
#else
ex.extract("781", out);
#endif
ncnn::Mat anchors(6);
anchors[0] = 30.f;
anchors[1] = 61.f;
anchors[2] = 62.f;
anchors[3] = 45.f;
anchors[4] = 59.f;
anchors[5] = 119.f;
std::vector<Object> objects16;
generate_proposals(anchors, 16, in_pad, out, prob_threshold, objects16);
proposals.insert(proposals.end(), objects16.begin(), objects16.end());
}
// stride 32
{
ncnn::Mat out;
#if YOLOV5_V62
ex.extract("2222", out);
#elif YOLOV5_V60
ex.extract("401", out);
#else
ex.extract("801", out);
#endif
ncnn::Mat anchors(6);
anchors[0] = 116.f;
anchors[1] = 90.f;
anchors[2] = 156.f;
anchors[3] = 198.f;
anchors[4] = 373.f;
anchors[5] = 326.f;
std::vector<Object> objects32;
generate_proposals(anchors, 32, in_pad, out, prob_threshold, objects32);
proposals.insert(proposals.end(), objects32.begin(), objects32.end());
}
// sort all proposals by score from highest to lowest
qsort_descent_inplace(proposals);
// apply nms with nms_threshold
std::vector<int> picked;
nms_sorted_bboxes(proposals, picked, nms_threshold);
int count = picked.size();
objects.resize(count);
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x - (wpad / 2)) / scale;
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
// clip
x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
}
return 0;
}
static void draw_objects(const cv::Mat& bgr, const std::vector<Object>& objects, double fps)
{
static const char* class_names[] = {
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
"hair drier", "toothbrush"
};
/*cv::Mat image = bgr.clone();*/
cv::Mat image = bgr;
for (size_t i = 0; i < objects.size(); i++)
{
const Object& obj = objects[i];
fprintf(stderr, "%d = %.5f at %.2f %.2f %.2f x %.2f\n", obj.label, obj.prob,
obj.rect.x, obj.rect.y, obj.rect.width, obj.rect.height);
cv::rectangle(image, obj.rect, cv::Scalar(255, 0, 0));
char text[256];
sprintf_s(text, "%s %.1f%%", class_names[obj.label], obj.prob * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = obj.rect.x;
int y = obj.rect.y - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > image.cols)
x = image.cols - label_size.width;
cv::rectangle(image, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(255, 255, 255), -1);
cv::putText(image, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
cv::putText(image, "FPS: " + std::to_string(fps), cv::Point(30, 50),
cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2);
}
//cv::imshow("image", image);
//cv::waitKey(1);
}
int main() {
ncnn::Net yolov5;
yolov5.opt.use_vulkan_compute = true;
/*yolov5.opt.use_bf16_storage = true;*/
yolov5.load_param("../model/v5lite-e.param");
yolov5.load_model("../model/v5lite-e.bin");
ncnn::Extractor ex = yolov5.create_extractor();
/*ex.set_num_threads(4);*/
cv::VideoCapture capture(0); // 打开默认摄像头
int frameCount = 0;
double totalTime = 0.f;
double fps = 0.f;
cv::Mat frame;
std::vector<Object> objects;
while (true) {
auto start = std::chrono::high_resolution_clock::now();
capture >> frame; // 读取摄像头的下一帧图像
// yolo 检测
detect_yolov5(frame, objects,ex);
draw_objects(frame, objects,fps);
// 显示结果
cv::imshow("YOLO检测e", frame);
// 更新帧统计信息
frameCount++;
auto end = std::chrono::high_resolution_clock::now();
double timeSec = std::chrono::duration<double>(end - start).count();
totalTime += timeSec;
// 计算并显示帧率
fps = frameCount / totalTime;
std::cout << "帧率: " << fps << std::endl;
int key = cv::waitKey(1);
if (key == 27) { // 按下 ESC 键退出循环
break;
}
}
capture.release(); // 释放摄像头
cv::destroyAllWindows(); // 关闭显示窗口
return 0;
}
到了这里,关于YOLOV5-LITE实时目标检测(onnxruntime部署+opencv获取摄像头+NCNN部署)python版本和C++版本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!