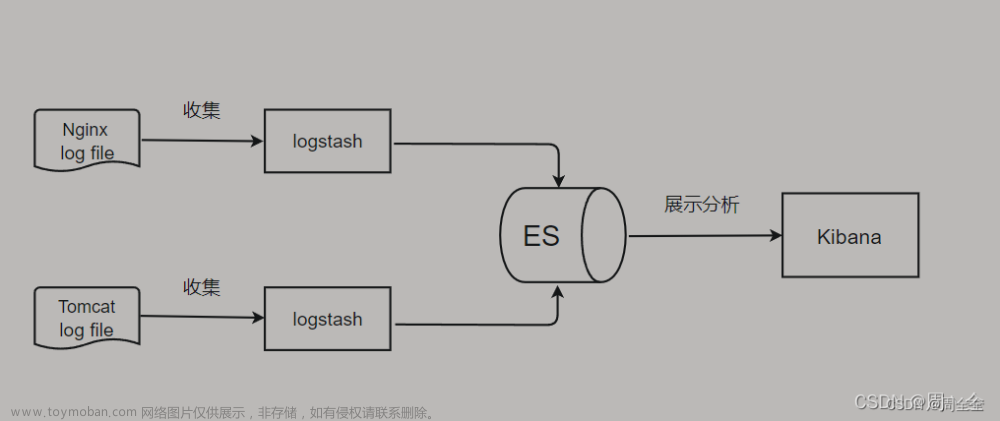
一、基本命令
1、获取所有_cat命令
curl -X GET localhost:9200/_cat2、获取es集群服务健康状态
curl -X GET localhost:9200/_cat/health?vepoch: 时间戳的 Unix 时间戳格式,表示快照生成的时间。
timestamp: 可读性更强的时间戳格式,表示快照生成的时间(08:06:34)。
cluster: Elasticsearch 集群的名称,这里是 "es-cluster"。
status: 集群的健康状态,这里是 "yellow"。Elasticsearch 集群状态通常有三种:green(绿色,健康),yellow(黄色,部分健康),red(红色,不健康)。"yellow" 状态表示集群中的某些副本不可用,但主分片是可用的。
node.total: 集群中节点的总数,这里是 1 个节点。
node.data: 充当数据节点的节点数,这里是 1 个节点。
shards: 集群中分片的总数,这里是 98 个分片。
pri: 主分片(primary shard)的数量,这里是 98 个主分片。
relo: 正在进行重新定位的分片数量,这里是 0。
init: 初始化的分片数量,这里是 0。
unassign: 未分配的分片数量,这里是 27。
pending_tasks: 挂起的任务数,这里是 0。
max_task_wait_time: 最大任务等待时间,这里是没有具体数值。
active_shards_percent: 活动分片的百分比,这里是 78.4%。这表示在集群中,有 78.4% 的分片是活动的,而剩下的可能是不可用或者正在恢复的。
3、查看es节点信息
curl -X GET localhost:9200/_cat/nodes?vip: 节点的IP地址,这里是"192.168.52.11"。
heap.percent: 节点的堆内存使用百分比,这里是67%。
ram.percent: 节点的系统内存使用百分比,这里是98%。
cpu: 节点的CPU使用率,这里是10%。
load_1m: 1分钟负载平均值,这里是0.69。
load_5m: 5分钟负载平均值,这里是0.36。
load_15m: 15分钟负载平均值,这里是0.50。
node.role: 节点的角色,这里是"*",表示这是一个主节点(master node)。
master: 指示该节点是否是主节点,这里是"*",表示它是主节点。
name: 节点的名称,这里是"node-1"。
4、查看es指定节点信息
curl -X GET localhost:9200/_nodes/node-1?pretty=true二、索引操作
1、查看ES中所有的索引
curl -X GET localhost:9200/_cat/indices?vhealth: 索引的健康状态,这里是 "yellow"。Elasticsearch 索引的健康状态有三种:green(绿色,健康),yellow(黄色,部分健康),red(红色,不健康)。"yellow" 状态表示索引的某些分片处于未分配状态,但主分片是可用的。
status: 索引的状态,这里是 "open"。这表示索引处于打开状态,可以进行读取和写入操作。
index: 索引的名称,这里是 "nginx-access-log-2023.09.13"。
uuid: 索引的唯一标识符。
pri: 主分片(primary shard)的数量,这里是 1 个主分片。
rep: 副本分片(replica shard)的数量,这里也是 1 个副本分片。
docs.count: 索引中文档的总数,这里是 20。
docs.deleted: 索引中已删除的文档数量,这里是 0。
store.size: 索引的存储大小,这里是 34.1KB。
pri.store.size: 主分片的存储大小,这里也是 34.1KB。
2、新建索引
curl -X PUT localhost:9200/testyf3、新建索引并增加数据 POST /索引/端点
POST /data/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2022-01-01" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2022-01-02" }4、追加数据
# 追加新增字段
POST /data/_bulk
{"update":{"_id":"1"}}
{"doc":{"title":"this is java and elasticsearch blog"}}5、删除索引
curl -X DELETE localhost:9200/testyf6、查看指定索引信息
curl -X GET localhost:9200/nginx-access-log-2023.09.13?pretty7、查看索引的统计信息
curl -X GET localhost:9200/nginx-access-log-2023.09.13/_stats?pretty三、文档操作
一)查询索引中的全部文档
curl -X GET localhost:9200/nginx-access-log-2023.09.13/_search?pretty注意:?pertty 表示让数据格式化,更好的展示
2)根据条件查询索引中的文档
单一条件搜索:
1、搜索 response_code 包含 200
POST /nginx-access-log-2023.09.13/_search?pretty
{
"query": {
"match": {
"response_code": "200"
}
}
}2、搜索 message 包含 34 或者 包含 36
POST /nginx-access-log-2023.09.25/_search?pretty
{
"query": {
"match": {
"message": "34 36"
}
},
"size": 1000
}3、搜索 message 包含 34 并且 包含 36
POST /nginx-access-log-2023.09.25/_search?pretty
{
"query": {
"match": {
"message": {
"query": "34 36",
"operator": "and"
}
}
},
"size": 1000
}
4、搜索 message 包含 34 36 15 22 中超过 50% 以上比例的
POST /nginx-access-log-2023.09.25/_search?pretty
{
"query": {
"match": {
"message": {
"query": "34 36 15 22",
"minimum_should_match": "50%"
}
}
},
"size": 1000
}
5、使用sort对查询数据排序,并按照size返回查询的数量(desc:降序 / asc:升序)
GET /data/_search?size=2
{
"query": {
"match": {
"title": "java elasticsearch"
}
},
"sort": {
"postDate": {
"order": "desc"
}
}
}多条件搜索:
1、(&&使用 must )搜索 response_code 包含 200,并且 @timestamp 包含 "2023-09-25T12:43:46.000Z"
POST /nginx-access-log-2023.09.25/_search?pretty
{
"query": {
"bool": {
"must": [{
"match": {
"response_code": "200"
}
},{
"match": {
"@timestamp": "2023-09-25T12:43:46.000Z"
}
}]
}
},
"size": 100
}2、(|| 使用 should )搜索 response_code 包含 200,或者 @timestamp 包含 "2023-09-25T12:43:46.000Z"
POST /nginx-access-log-2023.09.25/_search?pretty
{
"query": {
"bool": {
"should": [{
"match": {
"response_code": "200"
}
},{
"match": {
"@timestamp": "2023-09-25T12:43:46.000Z"
}
}]
}
},
"size": 100
}3、(|| 使用 should )搜索 response_code 包含 200,或者 @timestamp 包含 "2023-09-25T12:43:46.000Z",或者 message 包含 "Windows",至少满足2个以上
POST /nginx-access-log-2023.09.25/_search?pretty
{
"query": {
"bool": {
"should": [{
"match": {
"response_code": "200"
}
},{
"match": {
"@timestamp": "2023-09-25T12:43:46.000Z"
}
},{
"match": {
"message": "Windows"
}
}],
"minimum_should_match": 2
}
},
"size": 100
}4、搜索 response_code 包含 200,并且 @timestamp 不包含 "2023-09-25T12:43:46.000Z"
POST /nginx-access-log-2023.09.25/_search?pretty
{
"query": {
"bool": {
"must": [{
"match": {
"response_code": "200"
}
}],
"must_not": [{
"match": {
"@timestamp": "2023-09-25T12:43:46.000Z"
}
}]
}
},
"size": 100
}5、统计 response_code 包含 200 的有多少个
POST /nginx-access-log-2023.09.25/_count?pretty
{
"query": {
"bool": {
"must": [{
"match": {
"response_code": "200"
}
}]
}
}
} 3)转换
term:不分词,直接匹配字段的完整值
match:根据字段的分词器对搜索文本进行分词
1、普通match如何转换为term+should
转换前:
GET /data/_search
{
"query": {
"match": {
"title": "java elasticsearch"
}
}
}转换后:
GET /data/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": "java"
}
},
{
"term": {
"title": "elasticsearch"
}
}
]
}
}
}2、and match如何转换为term+must
转换前:
GET /data/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
}转换后:
GET /data/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": "java"
}
},
{
"term": {
"title": "elasticsearch"
}
}
]
}
}
}3、minimum_should_match如何转换
转换前:文章来源:https://www.toymoban.com/news/detail-764462.html
GET /data/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch hadoop spark",
"minimum_should_match": "75%"
}
}
}
}转换后:文章来源地址https://www.toymoban.com/news/detail-764462.html
GET /data/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": "java"
}
},
{
"term": {
"title": "elasticsearch"
}
},
{
"term": {
"title": "hadoop"
}
},
{
"term": {
"title": "spark"
}
}
],
"minimum_should_match": 3
}
}
}到了这里,关于ES常用查询命令的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!