启动命令
neo4j console
Cypher句法由四个不同的部分组成, 每一部分都有一个特殊的规则:
start——查找图形中的起始节点。
match——匹配图形模式, 可以定位感兴趣数据的子图形。
where——基于某些标准过滤数据。
return——返回感兴趣的结果。
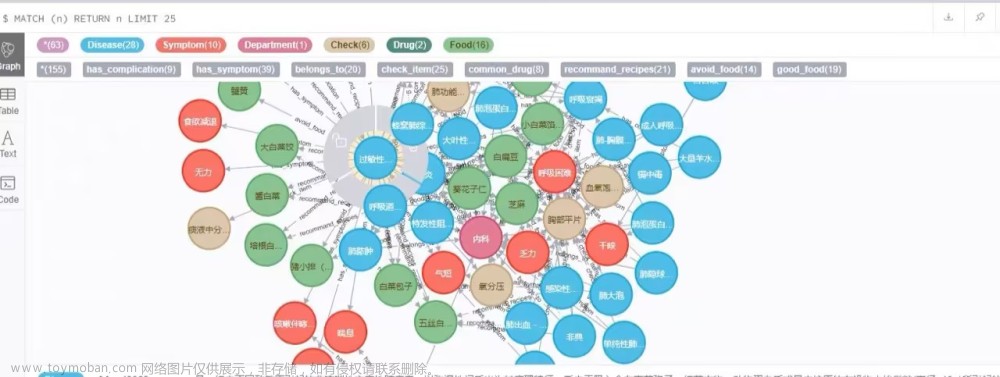
查询图谱视图(节点与节点直接关系图)
查询图谱视图(节点直接及相互关系)
CALL db.schema.visualization()1、创建节点
-- 创建类型为Person,属性为 {id: 1,name:'盘古',birthday:date("2000-08-18")} 的节点
create(n:Person{id: 1,name:'盘古',birthday:date("2000-08-18")})return n
create(:`Person`{id: 100,name:'测试'})
-- 批量创建节点
create(n:Person{id: 2,name:'鸿钧',birthday:date("2000-08-20")}),
(:Person{id: 3,name:'太上老君',birthday:date("2000-08-21")})
-- 创建节点为Person 和 Power 顶点数据,即一个节拥有多个类型
create(:`Person`:`Power`{id: 100,name:'测试'})
-- 抽取所有结点中包含国家的的字段进行去重,用于创建国家节点数据
MATCH (n) WHERE (n.`国家`) IS NOT NULL
with
distinct n.`国家` AS gj
MERGE(g:`国家`{name:gj})
return g;
-- 批量创建
-- 使用unwind可以利用缓存进行快速创建大量数据,UNWIND只能对同一类型的数据进行处理
-- set n += p.properties 可以对任意个属性进行合并
UNWIND [
{name: 'Wang, Li', properties:{name: 'Wang, Li'}},
{name: 'zhangsan', properties:{name: 'zhangsan', age:'14'}}
] AS p
merge(n:`作者`{name: p.name}) set n += p.properties;
UNWIND $props AS p
match (n:文献{name: p.head}), (m:作者{name: p.tail})
create (n)-[:连接]->(m);java 创建
/**
* 创建图结点数据
* 批量创建脚本 UNWIND $props AS p create(n:Person{name:'xx'})
*
* @param nodeList 结点数据
*/
private void createGraphNodeWithUnwind(List<DataNodeVO> nodeList) {
// 对数据信息分组处理,以 label 分组,因UNWIND只能对同一类型的数据进行处理
Map<String, List<DataNodeVO>> nodeGroupMap = nodeList.stream().collect(Collectors.groupingBy(r -> r.getLabel()));
List<DataNodeVO> groupRelation = null;
// 分批次处理关系
for (Map.Entry<String, List<DataNodeVO>> entity : nodeGroupMap.entrySet()) {
groupRelation = entity.getValue();
// 按照节点id进行分组,有些节点包含多属性
Map<String, List<DataNodeVO>> nodeIdGoupMap = groupRelation.stream().collect(Collectors.groupingBy(r -> r.getNodeId()));
List<Map<String, Object>> nodeDataList = new ArrayList<>(groupRelation.size());
List<DataNodeVO> dataNodes = null;
for (Map.Entry<String, List<DataNodeVO>> node : nodeIdGoupMap.entrySet()) {
dataNodes = node.getValue();
// 属性数据
Map<String, Object> properties = new HashMap<>(8);
dataNodes.stream().forEach(r -> {
properties.put(r.getProperty(), this.convertDataType(r.getDataType(), r.getPropertyValue()));
});
if (CollectionUtil.isNotEmpty(properties)) {
Map<String, Object> item = new HashMap<>(8);
item.put("label", entity.getKey());
item.put("name", properties.get(GraphConstants.DEFAULT_GRAPH_NODE_NAME));
item.put("properties", properties);
nodeDataList.add(item);
}
}
Map<String, Object> parameters = new HashMap<>(1);
parameters.put("props", nodeDataList);
// sql格式:UNWIND $props AS p create/merge(n:Person{name: p.name} set n += p.properties)
String relationSql = "UNWIND $props AS p merge(n:" + entity.getKey() + "{name: p.name}) set n += p.properties";
neo4jService.runTx(relationSql, parameters);
}
}2、查询所有数据
-- 查询所有信息
MATCH (n) return n
-- 查询指定类型(Person和City)节点
MATCH (h:Person),(m:City) return h,m
-- 通过条件查询,查询主键id为0的节点,主键查询使用(),如果使用.则表示为属性
match(p:Person) where id(p)=0 return p
-- 通过属性查询,查询属性id=1 数据
match(p:Person) where p.id=1 return p
-- 查询指定数量
match(n:Person) return n limit 10
-- 模糊搜索
match(m:Movie) where m.name=~('.*大战.*') return m
-- 对所有结点的任何属性进行模糊搜索
match (n)
with n, [x in keys(n) WHERE n[x]=~'.*发.*'] as doesMatch
where size(doesMatch) > 0
return n
-- 对节点类型为'文献' 和 '作者' 的任何属性进行模糊搜索
match (n) where labels(n) in [['文献'],['作者']]
with n, [x in keys(n) WHERE n[x]=~'.*发.*'] as doesMatch
where size(doesMatch) > 0
return n3、修改实体
-- 修改主键id为1的Person的生日
match(p:Person) where id(p)=1 set p.birthday="2000-01-01" return p
-- 修改属性id为1的Person的生日
match(p:Person) where p.id=1 set p.birthday="1900-01-01" return p
-- 使用map赋值, 注意: 这样会清除所有原属性
match (p { name: 'Peter' })
set p = { name: 'Peter Smith', position: 'Entrepreneur' }
return p
-- 如果要保留原属性, 把=变成+=
match (p { name: 'Peter' })
set p += { name: 'Peter Smith', position: 'Entrepreneur' }
return p
-- 完全复制一个节点或者关系
-- SET可用于将所有属性从一个节点或关系复制到另一个节点. 目标节点或关系的原属性会被清空.
match (at { name: 'Andy' }),(pn { name: 'Peter' })
set at = pn
return at.name, at.age, at.hungry, pn.name, pn.age
-- 修改标签(label)
-- 修改一个
match (n { name: 'Stefan' })
set n:German
return n.name, labels(n) AS labels
-- 修改多个
match(n{name: 'Peter'})
set n:Swedish:Bossman
return n.name, labels(n) as labels
4、删除
------------------ 只能删除不带连接的节点 start ---------------
-- 通过属性id删除数据
match(n:Person{id:1}) delete n
-- 通过条件删除,删除 主键id > 1的数据
MATCH (r) WHERE id(r) > 1 DELETE r
-- 删除 作者、文献、期刊所有节点
match(n:`作者`),(m:`文献`),(k:`期刊`) delete n,m,k
-- 删除属性
-- 删除 code 属性
match(d:`期刊`{name: '西北地质'}) remove d.code
-- 删除一个属性
-- 将这个属性置为null, 就是删除一个属性, 如下
match (n { name: 'Andy' })
set n.name = NULL
return n.name, n.age
-- 删除所有的属性
-- 使用一个空的map和等号, 这样即可删除节点所有属性
match (p { name: 'Peter' })
set p = { }
return p.name, p.age
------------------ 只能删除不带连接的节点 end ---------------
------------------ 删除节点连带着全部关系 start ---------------
-- 用 detach 删除
match(p:`期刊`{name: '西北地质'}) detach delete p
------------------ 删除节点连带着全部关系 start ---------------
5、创建关系
--------------- 无结点,即创建节点的同时创建边关系 start --------------------
-- 创建两个节点node1和node2及type属性prop=value边关系
CREATE (node1)-[:type {prop: 'value'}]->(node2)
-- 三条语句一起执行
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix)
-- 一条语句创建节点同时创建边
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'}),(Keanu:Person {name:'Keanu Reeves', born:1964}), (Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix)
-- 创建两个节点多个关系
CREATE (Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix), (Keanu)-[:ACTED_IN2 {roles:['Neo']}]->(TheMatrix)
-- 批量创建
create (a { name:"a" })-[:rel1]->(b {name :"b"}),(c {name:"c"})-[:rel2]->(d {name:"d"}),...
--------------- 无结点,即创建节点的同时创建边关系 end --------------------
--------------- 有结点,即对已存在的节点创建边关系 start --------------------
-- 创建 a -> b 的关系
# 语法1
MATCH(a:Person),(b:Person) WHERE a.id=2 AND b.id=3 CREATE(a)-[r:徒弟]->(b) RETURN r
MATCH(a:Power),(b:Person) WHERE a.name='人界' AND b.name='女娲' CREATE(a)-[r:所属]->(b) RETURN r
# 语法2
match (a:Student {name:"xiaoming"}), (b:Student {name:"zhangsan"})
create (a)-[r:同学]->(b) return a.name, type(r), b.name
# 将student属性class和Class的name相同的进行创建关系
match(n:`Student`),(m:`Class`)
with
n, m
where n.class = m.name
MERGE (n)-[s:`属于`]-(m)
return n,s,m;
-- 批量创建关系, 使用 UNWIND,数据为 List<Map<String. Object>>
UNWIND $props AS p match (n:文献{name: p.head}), (m:作者{name: p.tail}) create (n)-[:连接]->(m)
-- 说明: $props 为List<Map<String. Object>> 数组数据的变量参数,p为别名,p.head表示取map的head属性
-- 批量创建关系
UNWIND [
{head: '鸿钧', tail: '太上老君', properties:{name: '大徒弟'}},
{head: '鸿钧', tail: '元始天尊', properties:{name: '二徒弟', age:'14'}}
] AS p
match (n:Person{name: p.head}), (m:Person{name: p.tail}) MERGE (n)-[r:`徒弟`]->(m) SET r += p.properties
--------------- 有结点,即对已存在的节点创建边关系 end --------------------6、删除边关系
-- 删除reba节点的关系`期刊`
match(p:Person{name: "reba"})-[r:`期刊`]->() delete r
-- 删除 作者-> 期刊 的边关系 连接
match(n:`作者`)-[r:`连接`]->(m:`期刊`) delete r
-- 删除所有 边关系"连接"
MATCH (n)-[rel:`连接`]->(r) delete rel7、查询边关系
-- 查询所有边关系为"作者"的边
MATCH (n)-[rel:`作者`]->(r) return rel
--查询边关系为"作者"头结点 name为xx的数据
MATCH (n)-[rel:`作者`]->(r) where n.name='xx' return n, rel, r8、db命令
-- 所有可用的标签
call db.labels()
-- 所有的关系
call db.relationshipTypes()
9、导入
-- 如果需要导入其他文件系统文件,注释掉 dbms.directories.import=import
-- 是否允许从远程url load csv,默认不可以,如果允许远程url打开下面注释
dbms.security.allow_csv_import_from_file_urls=true
-- 导入csv,默认导入文件在neo4j安装目录import文件夹下
load csv with headers
from 'file:///tmdb_5000_movies.csv' as csv
create (
p:Movie{
title: csv.title,
url: csv.homepage,
year: toInteger(csv.year)
}
)
-- 无列名时可以使用列序号索引
load csv
from 'file:///tmdb_5000_movies.csv' as row
create (
p:Movie{
title: row[0],
url: row[1],
year: toInteger(row[2])
}
)
-- 导入关系
-- 无列名
load csv
from 'file:///tmdb_5000_movies.csv' as row
match(from:`Movie`{名称:row[0]}),(to:`Author`{名称:row[1]})
merge (from)-[r:作者]->(to)
--有列名
load csv with headers
from 'file:///tmdb_5000_movies.csv' as row
match(from:`Movie`{名称:row.from}),(to:`Author`{名称:row.to})
merge (from)-[r:作者]->(to)
10、OPTIONAL
如果某个关系是可选的,可使用OPTINAL MATCH。这很类似SQL中outer join的工作方式。如果关系存在就返回,否则在相应的地方返回null
-- 返回电影The Matrix这个节点的外向关系
MATCH (a:Movie { title: 'The Matrix' })
OPTIONAL MATCH (a)--(x)
RETURN x
-- 如果可选的元素为null,那么该元素的属性也返回null
-- 返回了x元素(查询中为null),它的name属性也为null
MATCH (a:Movie { title: 'The Matrix' })
OPTIONAL MATCH (a)-->(x)
RETURN x, x.name
-- 可选关系类型,可在查询中指定可选的关系类型
MATCH (a:Movie { title: 'The Matrix' })
OPTIONAL MATCH (a)<-[r: ACTED_IN]-()
RETURN r11、配置
1、修改指定数据库
#默认
#dbms.default_database=neo4j
#修改
dbms.default_database=movies
2、修改可以从任意目录读取
#默认从import目录读取
dbms.directories.import=import
# 注释后可以从任意路径读取文件
#dbms.directories.import=import
3、修改是否允许从远程url load csv
# 默认不启用
#dbms.security.allow_csv_import_from_file_urls=true
# 开启后可以允许从远程url load csv
dbms.security.allow_csv_import_from_file_urls=true
4、允许其他电脑访问客户端
# 默认只允许 localhost 访问
#dbms.default_advertised_address=localhost
#允许其他客户端访问,启用配置
dbms.default_advertised_address=0.0.0.0
dbms.connector.bolt.listen_address=0.0.0.0:7687
dbms.connector.http.listen_address=0.0.0.0:7474
12、apoc扩展与使用
-- 参考地址:https://www.yii666.com/blog/393843.html?action=onAll
-- 下载地址:https://neo4j.com/labs/apoc/4.4/installation/
-- 将对应的版本jar下载下来放入plugins文件夹中,重启服务
-- 使用命令 return apoc.version() 查询版本信息
-- 导出文件需要配置,在neo4j.conf 中添加
apoc.export.file.enabled=true
不配置,导出可能会报错
-- 导出json
CALL apoc.export.json.all("all.json",{useTypes:true})
-- 会将数据导出到安装包更目录下
-- 导出cypher
-- 参考地址:https://blog.csdn.net/GraphWay/article/details/109616926
-- 导出全部数据
call apoc.export.cypher.all("cypher_all.cypher", {cypherFormat:'updateAll'})
-- 使用查询语句导出
CALL apoc.export.cypher.query(
query,
file,
{configuration}
)
-- 示例:
CALL apoc.export.cypher.query(
"MATCH p=()-[rel:`包含`]->(),q=()-[rel2:`属于`]->() return p,q",
"cypher_pd.cypher",
{cypherFormat:'updateAll'}
)1
neo4j配置文件
#***************************** 基础运行配置 ************************************
# 如果想自定义neo4j数据库数据的存储路径,要同时修改dbms.active_database 和 dbms.directories.data 两项配置,
# 修改配置后,数据会存放在${dbms.directories.data}/databases/${dbms.active_database} 目录下
# 安装的数据库的名称,默认使用${NEO4J_HOME}/data/databases/graph.db目录
dbms.active_database=graph.db
dbms.directories.data=data
# 插件路径
#dbms.directories.plugins=plugins
# 证书路径
#dbms.directories.certificates=certificates
# 日志路径
dbms.directories.logs=logs
# jar包路径
#dbms.directories.lib=lib
# 脚本运行路径
#dbms.directories.run=run
#***************************** 权限配置 ************************************
# 是否开启身份验证,注释后无需验证,默认false
dbms.security.auth_enabled=true
# 认证模式 `native` or `ldap`
#dbms.security.auth_provider=native
# 使用时缓存的身份验证和授权信息的生存时间(TTL)
#dbms.security.auth_cache_ttl=10m
# 身份验证缓存和授权缓存的最大容量
#dbms.security.auth_cache_max_capacity=10000
# 设置身份验证的事件记录到安全日志。如果设置为“false”,将只记录失败的身份验证事件
#dbms.security.log_successful_authentication=true
#***************************** 内存配置 ************************************
# 初始化内存和限定最大内存,默认情况下,Java堆大小是动态地根据可用的系统资源计算。
dbms.memory.heap.initial_size=16g
dbms.memory.heap.max_size=16g
# 用于映射存储文件的内存量(以字节为单位)千字节带有'k'后缀,兆字节带有'm',千兆字节带有'g')。
# 如果Neo4j在专用服务器上运行,那么通常建议为操作系统保留大约2-4千兆字节,
# 为JVM提供足够的堆来保存所有的事务状态和查询上下文,然后保留其余的页面缓存 。
# 默认页面缓存存储器假定机器专用于运行Neo4j,并且试探性地设置为RAM的50%减去最大Java堆大小。
dbms.memory.pagecache.size=28g
#***************************** 网关配置 ************************************
# 只接受本地连接,请注释此行
dbms.connectors.default_listen_address=0.0.0.0
# 客户端可以访问此服务器的地址。这可以是服务器的IP地址或DNS名称,或者可以是位于服务器前面的反向代理的地址。此设置可能会覆盖以下各个连接器
#dbms.connectors.default_advertised_address=localhost
# HTTP 端口,默认7474
dbms.connector.http.enabled=true
#dbms.connector.http.listen_address=:7474
# Bolt 端口,默认7687
dbms.connector.bolt.enabled=true
#dbms.connector.bolt.tls_level=OPTIONAL
#dbms.connector.bolt.listen_address=:7687
# HTTPS 端口,默认7473
dbms.connector.https.enabled=true
#dbms.connector.https.listen_address=:7473
# 线程数
#dbms.threads.worker_count=
#***************************** 集群配置 ************************************
# neo4j运行模式:HA, SINGLE, CORE, READ_REPLICA; 1.安全性:核心服务器(Core)为事物平台处理提供了容错平台 2.可扩展性:只读副本(Read Replica)为图查询提供了一个大规模高可扩展的平台
# 例子:HA集群
#dbms.mode=HA
#ha.server_id=104
#ha.initial_hosts=192.168.1.101:5001,192.168.1.102:5001,192.168.1.103:5001
#ha.host.coordination=192.168.1.101:5001
# 例子:因果集群
# dbms.mode=CORE
# 配置成当前机器IP或hostname
#dbms.connectors.default_advertised_address=192.168.1.101
#causal_clustering.minimum_core_cluster_size_at_formation=2
#causal_clustering.minimum_core_cluster_size_at_runtime=2
#causal_clustering.initial_discovery_members=192.168.1.101:5000,192.168.1.102:5000,192.168.1.103:5000
#causal_clustering.discovery_listen_address=:5000
#causal_clustering.transaction_listen_address=:6000
# 列出此服务器所属的组的名称集。这是一个逗号分隔的列表,名字只能使用字母数字,主要目的是对服务器进行分组,但是也可以指定这里也是唯一的标识符,对于故障排除可能很有用或其他特殊用途。
#causal_clustering.server_groups=
#***************************** 数据导入配置 ************************************
# “LOAD CSV”导入文件限制在`import`目录下。删除注释允许从文件系统的任何地方加载文件;这引入了可能的安全问题。
dbms.directories.import=import
# 是否兼容以前版本的数据,默认true
dbms.allow_upgrade=true
#***************************** 在线备份配置 ************************************
# 启用从该数据库进行在线备份
#dbms.backup.enabled=true
# 备份服务地址绑定,如果是集群时与 causal_cluster.transaction_listen_address 搭配使用
#dbms.backup.address=0.0.0.0:6362
# 对 CC 实例的备份服务进行不可加密(对单实例或HA集群无效)
#dbms.backup.ssl_policy=backup
#***************************** 日志配置 ************************************
# **** info 日志 ****
# 要启用HTTP日志记录,请取消注释此行
#dbms.logs.http.enabled=true
# 要保留的HTTP日志数
#dbms.logs.http.rotation.keep_number=5
# 每个HTTP日志文件的大小
#dbms.logs.http.rotation.size=20m
# **** GC 日志 ****
# 要启用GC日志记录,请取消注释此行
#dbms.logs.gc.enabled=true
# GC日志记录选项 请参见http://docs.oracle.com/cd/E19957-01/819-0084-10/pt_tuningjava.html#wp57013
#dbms.logs.gc.options=-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintPromotionFailure -XX:+PrintTenuringDistribution
# 要保留的GC日志数
#dbms.logs.gc.rotation.keep_number=5
# 保留的每个GC日志文件的大小
#dbms.logs.gc.rotation.size=20m
# **** 调试日志 ****
# 调试日志旋转的大小阈值。如果设置为零,则不会发生滚动(达到指定大小后切割日志文件)。接受二进制后缀“k”,“m”或“g”
#dbms.logs.debug.rotation.size=20m
# 最多保存几个日志文件
#dbms.logs.debug.rotation.keep_number=7
# **** query 日志 ****
# 开启查询语句耗时过高记录日志
#dbms.logs.query.enabled=true
# 如果查询时间超过该时间时记录到日志,等于0时全部记录
#dbms.logs.query.threshold=0
# 每个query日志文件大小,可设置单位 "k", "m" or "g".
#dbms.logs.query.rotation.size=20m
# 保留query日志文件最大个数
#dbms.logs.query.rotation.keep_number=7
# 记录执行查询的参数,默认开启。
#dbms.logs.query.parameter_logging_enabled=true
# 记录查询时间,默认开启
#dbms.logs.query.time_logging_enabled=true
# 记录查询所分配的大小,默认开启
#dbms.logs.query.allocation_logging_enabled=true
# 记录查询时页面操作和错误信息:
#dbms.logs.query.page_logging_enabled=true
# The security log is always enabled when `dbms.security.auth_enabled=true`, and resides in `logs/security.log`.
# **** security 日志 ****
# 安全权限日志需开启身份验证(dbms.security.auth_enabled=true),保存日志在 `logs/security.log`
# 日志输出等级: DEBUG, INFO, WARN and ERROR.
#dbms.logs.security.level=INFO
# 每个日志文件最大块
#dbms.logs.security.rotation.size=20m
# 最小回滚时间
#dbms.logs.security.rotation.delay=300s
# 保留最大日志文件个数.
#dbms.logs.security.rotation.keep_number=7
#***************************** SSL策略配置 ************************************
#bolt.ssl_policy=legacy
#https.ssl_policy=legacy
# SSL policy configuration
#dbms.ssl.policy.default.base_directory=certificates/default
#dbms.ssl.policy.default.allow_key_generation=false
#dbms.ssl.policy.default.trust_all=false
#dbms.ssl.policy.default.private_key=
#dbms.ssl.policy.default.public_certificate=
#dbms.ssl.policy.default.trusted_dir=
#dbms.ssl.policy.default.client_auth=require
#dbms.ssl.policy.default.tls_versions=
#dbms.ssl.policy.default.ciphers=
#***************************** 集群负载均衡配置 ************************************
# 选择要启用的负载平衡插件
#causal_clustering.load_balancing.plugin=server_policies
# 示例: "server_policies" 组件
# 将选择所有可用服务器作为默认策略,该策略是当客户端没有指定策略首选项时使用的策略。默认配置为all()。
#causal_clustering.load_balancing.config.server_policies.default=all()
# 在默认策略下选择组'group1'或'group2'中的服务器
#causal_clustering.load_balancing.config.server_policies.default=groups(group1,group2)
# 稍微高级一点的例子:将选择“group1”、“group2”或“group3”中的服务器,但仅当至少有2个服务器时才这样做。此策略将以“mypolicy”的名称公开。
#causal_clustering.load_balancing.config.server_policies.mypolicy=groups(group1,group2,group3) -> min(2)
#causal_clustering.load_balancing.config.server_policies.policyA=\
#groups(regionA) -> min(2);\
#groups(regionA,regionB) -> min(2);
#causal_clustering.load_balancing.config.server_policies.regionA_only=\
#groups(regionA);\
#halt();
# 附件配置选项,如果你不知道使用情况,建议注释
#causal_clustering.database=default
#causal_clustering.raft_advertised_address=:7000
#causal_clustering.transaction_advertised_address=:6000
#causal_clustering.leader_election_timeout=7s
# 允许新成员尝试更新其数据以匹配集群其余部分的时间限制
#causal_clustering.join_catch_up_timeout=10m
# The size of the batch for streaming entries to other machines while trying to catch up another machine.
#causal_clustering.catchup_batch_size=64
# When to pause sending entries to other machines and allow them to catch up.
#causal_clustering.log_shipping_max_lag=256
#causal_clustering.raft_log_pruning_frequency=10m
#causal_clustering.raft_log_rotation_size=250M
#causal_clustering.pull_interval=1s
#causal_clustering.cluster_routing_ttl=300s
# HA集群附加配置
#dbms.mode=HA
#ha.server_id=
#ha.initial_hosts=127.0.0.1:5001,127.0.0.1:5002,127.0.0.1:5003
#ha.host.coordination=127.0.0.1:5001
#ha.host.data=127.0.0.1:6001
#dbms.logs.gc.options=-Xlog:gc*,safepoint,age*=trace
#ha.pull_interval=10
#ha.tx_push_factor=1
#ha.tx_push_strategy=fixed_ascending
#ha.branched_data_policy=keep_all
#ha.heartbeat_interval=5s
#ha.heartbeat_timeout=40s
#dbms.security.ha_status_auth_enabled=false
#ha.slave_only=false
#***************************** 其它配置 ************************************
# Enable this to specify a parser other than the default one.
#cypher.default_language_version=3.0
# Determines if Cypher will allow using file URLs when loading data using
# `LOAD CSV`. Setting this value to `false` will cause Neo4j to fail `LOAD CSV`
# clauses that load data from the file system.
#dbms.security.allow_csv_import_from_file_urls=true
# Value of the Access-Control-Allow-Origin header sent over any HTTP or HTTPS
# connector. This defaults to '*', which allows broadest compatibility. Note
# that any URI provided here limits HTTP/HTTPS access to that URI only.
#dbms.security.http_access_control_allow_origin=*
# Value of the HTTP Strict-Transport-Security (HSTS) response header. This header
# tells browsers that a webpage should only be accessed using HTTPS instead of HTTP.
# It is attached to every HTTPS response. Setting is not set by default so
# 'Strict-Transport-Security' header is not sent. Value is expected to contain
# dirictives like 'max-age', 'includeSubDomains' and 'preload'.
#dbms.security.http_strict_transport_security=
# Retention policy for transaction logs needed to perform recovery and backups.
dbms.tx_log.rotation.retention_policy=7 days
#***************************** shell客户端 登陆配置 ************************************
# 启用Neo4j Shell客户端可以登录的远程shell服务器
dbms.shell.enabled=true
# The network interface IP the shell will listen on (use 0.0.0.0 for all interfaces).
#dbms.shell.host=127.0.0.1
# shell 开放端口 1337.
#dbms.shell.port=1337
# 只允许从Neo4j实例读取操作。此模式仍然需要对目录的写访问以用于锁定目的。
#dbms.read_only=false
# 包含JAX-RS资源的JAX-RS软件包的逗号分隔列表,每个安装点一个软件包名称。
# 所列出的软件包名称将在指定的安装点下加载。取消注释此行以装载org.neo4j.examples.server.unmanaged.HelloWorldResource.java neo4j-server-examples下/ examples / unmanaged,最终的URL为http//localhost7474/examples/unmanaged/helloworld/{nodeId}
#dbms.unmanaged_extension_classes=org.neo4j.examples.server.unmanaged=/examples/unmanaged
#***************************** JVM参数 ************************************
# G1GC通常在吞吐量和尾部延迟之间达到很好的平衡,而没有太多的调整。
dbms.jvm.additional=-XX:+UseG1GC
# Cypher commit size,提交大小
dbms.jvm.additional=-Xss50M
# 有共同的异常保持生成堆栈跟踪,所以他们可以被调试,无论日志被旋转的频率
dbms.jvm.additional=-XX:-OmitStackTraceInFastThrow
# 确保在启动数据库之前,“initmemory”不仅被分配,而且被提交到进程。这减少了内存碎片,增加了透明大页面的有效性。
# 它还减少了由于堆增长的GC事件而导致性能下降的可能性,其中可用页面缓存的减少导致平均IO响应时间的增加。如果此标志降低性能,请减少堆内存。
dbms.jvm.additional=-XX:+AlwaysPreTouch
# 信任非静态final字段真的是final。这允许更多的优化和提高整体性能。注意:如果使用嵌入模式,或者有可能使用反射或序列化更改最终字段的值的扩展或依赖关系,请禁用此选项!
dbms.jvm.additional=-XX:+UnlockExperimentalVMOptions
dbms.jvm.additional=-XX:+TrustFinalNonStaticFields
# 禁用显式垃圾回收,这是偶尔由JDK本身调用。
dbms.jvm.additional=-XX:+DisableExplicitGC
# 远程JMX监视,取消注释并根据需要调整以下行。需要jmx.access和jmx.password文件的绝对路径。
# 还要确保使用适当的权限角色和密码更新jmx.access和jmx.password文件,所配置的配置只包含名为“monitor”的只读角色,密码为“Neo4j”。
# Also make sure to update the jmx.access and jmx.password files with appropriate permission roles and passwords,
# Unix系统,有关详情,请参阅:http://download.oracle.com/javase/8/docs/technotes/guides/management/agent.html,jmx.password文件需要由运行服务器的用户拥有,并且权限设置为0600。
# Windows系统 有关在设置这些文件权限的详细信息,请参阅:http://docs.oracle.com/javase/8/docs/technotes/guides/management/security-windows.html
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.port=3637
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.authenticate=true
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.ssl=false
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.password.file=/absolute/path/to/conf/jmx.password
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.access.file=/absolute/path/to/conf/jmx.access
# 某些系统无法自动发现主机名,需要配置以下行::
#dbms.jvm.additional=-Djava.rmi.server.hostname=$THE_NEO4J_SERVER_HOSTNAME
# 对于服务器TLS握手中使用的DH-RSA密码套件,将Diffie Hellman(DH)密钥大小从默认1024展开到2048。
# 这是为了保护服务器免受任何潜在的被动窃听。
dbms.jvm.additional=-Djdk.tls.ephemeralDHKeySize=2048
# This mitigates a DDoS vector.
dbms.jvm.additional=-Djdk.tls.rejectClientInitiatedRenegotiation=true
#********************************************************************
# Wrapper Windows NT/2000/XP Service Properties
#********************************************************************
# WARNING - Do not modify any of these properties when an application
# using this configuration file has been installed as a service.
# Please uninstall the service before modifying this section. The
# 请在修改此部分之前卸载服务。 然后可以重新安装该服务。
# 服务的名称
dbms.windows_service_name=neo4j
#********************************************************************
# Other Neo4j system properties
#********************************************************************
dbms.jvm.additional=-Dunsupported.dbms.udc.source=tarball
#********************************************************************
### Neo4j apoc properties
###******************************************************************
dbms.security.procedures.unrestricted=*
#********************************************************************
### Neo4j transcation timeout
###******************************************************************
dbms.transaction.timeout=180180180s
#********************************************************************
#### Neo4j text index 此项配置可能会影响性能
####*****************************************************************
apoc.autoIndex.enabled=true
#********************************************************************
##### CSV File export and import
#####****************************************************************
apoc.export.file.enabled=true
apoc.import.file.enabled=true
dbms.directories.import=import
dbms.security.allow_csv_import_from_file_urls=true扩展资料
关于Neo4j和Cypher批量更新和批量插入优化的5个建议_neo4j unwind批量写入_captain_hwz的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-764614.html
https://www.cnblogs.com/milton/archive/2022/05/02/16179836.html文章来源地址https://www.toymoban.com/news/detail-764614.html
到了这里,关于Neo4j 语法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!