【常见名词】
1、token
token是LLM中处理的最小文本单元,token的分割有多种策略:
(1)基于空格分词:即以空格为分隔,将文本分割成词组。对于英文可以使用这种方式。
(2)基于词典分词:根据预设的词典,在词典中可以匹配到的词组作为一个token;
(3)基于字节对齐分词:按照字节个数将文本分割,常见的中文模型使用2字节或3字节对;
(4)基于子词分词:将单词拆分为更小的子词组成token,例如"learning"可以拆分为[“learn”,“##ing”];
(5)BPE分词:通过统计学将高频词组 合并 为一个token。(GPT系列采用的方式:是一种基于数据压缩原理的算法,它可以根据语料库中出现频率最高的字节对(byte pair)来合并字节,从而生成新的字节。)
一、LLM的低资源模型微调
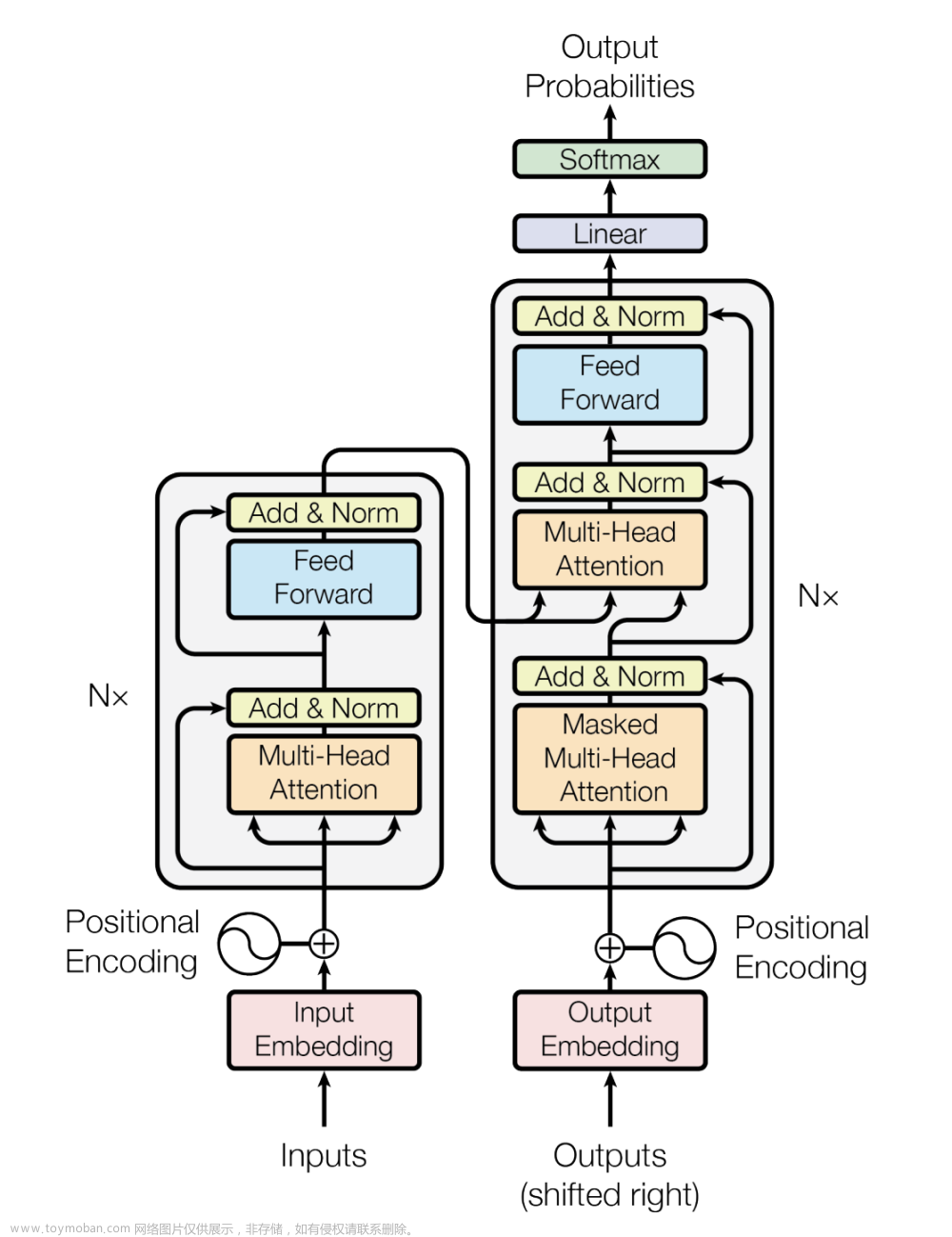
(1)p tuning v2
(2)Lora
这种方法有点类似于矩阵分解,可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,r<<d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多,下图中对矩阵A使用随机高斯初始化,对矩阵B使用0进行初始化。
推理计算的时候,因为没有改变预训练权重,所以换不同的下游任务时,lora模型保存的权重也是可以相应加载进来的,通过矩阵分解的方法参数量减少了很多。
二、向量数据库
1、Milvus(v2.1.4):云原生自托管向量数据库(Ubuntu下)
- milvus的GitHub
- 支持元数据存储。
1)安装(Docker Compose方式):
- 参考博客:https://blog.csdn.net/hello_dear_you/article/details/127841589
- 官网说明:https://milvus.io/docs/v2.1.x/install_standalone-docker.md
【注意】安装的时候,如果第一次安装错了版本,直接重新走下面的步骤的时候很可能启动时,milvus-minio秒退!!
(1)创建目录:
mkdir Milvus
(2)下载YAML文件
wget https://github.com/milvus-io/milvus/releases/download/v2.1.4/milvus-standalone-docker-compose.yml -O docker-compose.yml
(3)在YAML文件所在目录下启动Milvus
sudo docker compose up -d # docker v2,若是v1则使用docker-compose;使用docker compose version查看docker版本
【注意】
① 如果没有docker命令,则安装:
sudo snap install docker
② 这个命令开始执行之后会自动下载Milvus对应的镜像文件,需要等待一段时间。 当镜像下载完成后,相应的容器也会启动。
(4)查看Milvus的启动状态:
sudo docker compose ps

(5)停止Milvus
sudo docker compose down
2)管理工具(仅支持Milvus 2.0 之后的):
(1) Milvus_cli
(2) Attu可视化管理界面官方安装教程
- attu的GitHub
- 注意 attu 和 milvus 版本之间的对应关系,否则会登录不了,点击connect报
400 Bad Request。
| milvus | attu |
|---|---|
| 2.0.x | 2.0.5 |
| 2.1.x | 2.1.5 |
| 2.2.x | 2.2.6 |
① 使用Docker Compose方式进行安装,
step1:通过Docker Compose方式安装完成milvus(即下载完YAML文件);
step2:编辑下载好的YAML文件,在service语句块添加以下内容:
attu:
container_name: attu
image: zilliz/attu:v2.1.5
environment:
MILVUS_URL: milvus-standalone:19530
ports:
- "8001:3000" # 我的8000端口一直提示被占用,所以换成了8001端口
depends_on:
- "standalone"
step3:启动milvus:sudo docker-compose up -d
② 使用docker安装
docker run -p 8001:3000 -e MILVUS_URL={your machine IP}:19530 zilliz/attu:v2.1.5
step4:安装完成后,在连网的浏览器输入:http://{ your machine IP }:8001即可进入attu登录界面。
(your machine IP为安装milvus的机器ip;下图为attu的登陆界面,没有放开账号密码认证。)
3)python操作:基于pymilvus == 2.1.3
- 注意Milvus版本和pymilvus版本之间的对应,否则会报错:
pymilvus.exceptions.MilvusException: <MilvusException: (code=1, message=this version of sdk is incompatible with server, please downgrade your sdk or upgrade your server)>
两者之间的版本对应:官网
| Milvus | pymilvus |
|---|---|
| 2.2.12 | 2.2.14 |
| 2.2.11 | 2.2.13 |
| 2.1.4 | 2.1.3 |
| 2.1.2 | 2.1.2 |
- pymilvus不同版本之间差异很大。
- milvus的字段数据类型(dtype):仅可以在向量类型字段((BINARY_VECTOR、FLOAT_VECTOR))上创建索引
| 数据类型 | 说明 |
|---|---|
| NONE | |
| BOOL | |
| INT8 | 支持主键字段 |
| INT16 | 支持主键字段 |
| INT32 | 支持主键字段 |
| INT64 | 支持主键字段 |
| FLOAT | |
| DOUBLE | |
| STRING | |
| VARCHAR | |
| BINARY_VECTOR | 二值型向量,可以在该类型字段上创建索引 (适用下表中的后两种索引) |
| FLOAT_VECTOR | 浮点型向量,可以在该类型字段上创建索引(适用下表中的前九种索引) |
| UNKNOWN |
- 索引类型(index_type)与向量度量类型(metric_type):
| 索引类型 | 说明 | 可用的度量类型 |
|---|---|---|
| FLAT | 适用于需要 100% 召回率且数据规模相对较小(百万级)的向量相似性搜索应用 | “L2”, “IP” |
| IVFLAT / IVF_FLAT | 基于量化的索引,适用于追求查询准确性和查询速度之间理想平衡的场景(高速查询、要求高召回率) | “L2”, “IP” |
| IVF_SQ8 | 基于量化的索引,适用于磁盘或内存、显存资源有限的场景(高速查询、磁盘和内存资源有限、接受召回率的小幅妥协) | “L2”, “IP” |
| IVF_PQ | 基于量化的索引,适用于追求高查询速度、低准确性的场景(超高速查询、磁盘和内存资源有限、接受召回率的实质性妥协) | “L2”, “IP” |
| HNSW | 基于图的索引,适用于追求高查询效率的场景(高速查询、要求尽可能高的召回率、内存资源大的情景) | “L2”, “IP” |
| ANNOY | 基于树的索引,适用于追求高召回率的场景(低维向量空间) | “L2”, “IP” |
| RHNSW_FLAT | 基于量化和图的索引,高速查询、需要尽可能高的召回率、内存资源大的情景 | “L2”, “IP” |
| RHNSW_PQ | 基于量化和图的索引,超高速查询、磁盘和内存资源有限、接受召回率的实质性妥协 | “L2”, “IP” |
| RHNSW_SQ | 基于量化和图的索引,高速查询、磁盘和内存资源有限、接受召回率的小幅妥协 | “L2”, “IP” |
| BIN_FLAT | - | “JACCARD”, “TANIMOTO”, “HAMMING”, “SUBSTRUCTURE”, “SUPERSTRUCTURE” |
| BIN_IVF_FLAT | - | “JACCARD”, “TANIMOTO”, “HAMMING” |
(1)创建conda环境Milvus,并安装pymilvus
pip install pymilvus
【注意】操作时使用docker-compose ps -a查看milvus运行状态,确保milvus容器处在开启状态。
2、Faiss
- FAISS的GitHub
- C++编写的向量索引工具,是针对稠密向量进行相似性搜索和聚类的一个高效类库;有python接口,有CPU版和GPU版,可以直接pip安装。
- 不支持元数据存储
pip install faiss-cpu==1.7.3
# 或者conda环境中安装
conda install faiss-cpu -c pytorch # cpu 版本
conda install faiss-gpu cudatoolkit=8.0 -c pytorch # GPU 版本 For CUDA8
3、Pinecone:完全托管的云原生向量数据库
python中使用:
# langchain中的模块
from langchain.vectorstores import Pinecone
4、postgreSQL+pgvector插件
GitHub网址:https://github.com/pgvector/pgvector
详细内容参见博客:https://blog.csdn.net/lucky_chaichai/article/details/118575261
三、LangChain+外挂知识库
1、简介
- langchain中文网:https://www.langchain.com.cn/
- LangChain是一个链接面向用户程序和LLM之间的一个中间层,用以集成LLM和自有知识库的数据。
- LangChain,可以通过将其它计算资源和自有的知识库结合,通过输入自己的知识库来“定制化”自己的大语言模型,防止“AI幻觉”;
- 使用langchain将外挂知识库与LLM结合的策略是:
在向量数据库中索引 question 的相似向量(度量准则包括余弦距离、欧式距离等),找到top_n条向量对应的关联文本作为context,根据预设的模板拼接得到最终的prompt,如:
已知信息:{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}
外挂知识库+LLM的一般过程:
2、安装
pip install langchain
3、主要的几大模块:
LLM API模块:langchain.llms
文本分块器:langchain.text_splitter(text_splitter中常用分类器介绍)
向量模型加载、向量化模块:langchain.embeddings
向量存储、索引模块:from langchain.vectorstores import Milvus, FAISS, Pinecone, Chroma
文件操作模块:langchain.docstore、angchain.document_loaders
langchain.agents
四、AI web工具
1、Gradio==3.28.3
- Gradio的GitHub:https://github.com/gradio-app/gradio
- Gradio支持Markdown文本显示规则,
‘\n’换行不起作用,需要替换为‘<br/>’; - 目前感觉这个真的仅适合做小demo(可能我还不是太精通吧);
- 组件的value是什么数据类型,则在触发事件的函数 fn 中就直接看作该类型进行操作。
gr.Interface()、gr.Blocks()两种方式搭建UI界面:
| 组件/事件监听器 | 描述 |
|---|---|
| State(value) | 隐藏组件,用于存储一些组件交互需要使用的变量,可以通过组件之间的交互改变其值,可以使用obj.value获取其值 |
| Markdown(value) | Markdown格式的文本输入输出,在页面上遵循Markdown规范显示文本(value) |
| Tab(value) | “标签页”布局组件,在一个页面上可以多个tab切换,value为tab上显示的文字 |
| Row(variant) | 行类型,“default”(无背景)、“panel”(灰色背景色和圆角)或“compact”(圆角和无内部间隙) |
| Column(scale) | “列布局”组件,scale为与相邻列相比的相对宽度 |
| Accordion(label) | 折叠框组件, label为折叠筐的名称(会显示在组件上) |
| Chatbot(value) | 对话框组件,value为对话框默认值,一般为 [[我方None, 他方init_message], …],该组件在“触发”的fn函数中一般作为上述格式的list使用 |
| Textbox(placeholder) | 文本框组件,placeholder为在文本区域提供占位符提示的字符串 |
| Radio() | |
| Button(value, interactive) | 按钮组件,value为按钮上面显示的文字;interactive=False则按钮为禁用状态 |
| Dropdown(choices, label, value) | 下拉框组件,choices为list,其中元素为可选项;label下拉框的名称(会显示在组件上);value为list中的默认选项 |
| Number(value, label) | 创建数字输入和显示数字输出的组件,value为该组件默认值,label为该组件名称(会显示在组件上) |
| change(fn, input, output) | 触发事件,当前组件(如Dropdown)的输入值改变时将会触发这个事件,fn根据输入input生成输出output,input、output均为组件或组件列表,fn的每个参数对应一个输入组件,每个返回值对应一个输出组件 |
| click(fn, input, output) | 触发事件,当前组件(如Button)点击时将会触发这个事件 |
| setup() | |
| submit(fn, input, output) | 触发事件,当前组件(如Textbox)提交(回车)时将会触发这个事件 |
2、Streamlit == 1.25.0
- 在做LLM聊天web UI方面,streamlit要比Gradio复杂的多,功能也更加强大,需要自己对各种组件进行风格渲染(没有现成的chatbot这种组件)。
- 与Gradio相比,需要一点前端基础知识。
- 不同于Gradio,定义的组件对象和使用st.session_state.[组件key]获取的值一样……
- 运行方式:在py文件路径下,执行命令
streamlit run webui_st.py
简单的聊天对话框示例:
import time
import streamlit as st
class MsgType:
'''
目前仅支持文本类型的输入输出,为以后多模态模型预留图像、视频、音频支持。
'''
TEXT = 1
IMAGE = 2
VIDEO = 3
AUDIO = 4
class ST_CONFIG:
user_bg_color = '#77ff77'
user_icon = 'https://tse2-mm.cn.bing.net/th/id/OIP-C.LTTKrxNWDr_k74wz6jKqBgHaHa?w=203&h=203&c=7&r=0&o=5&pid=1.7'
robot_bg_color = '#ccccee'
robot_icon = 'https://ts1.cn.mm.bing.net/th/id/R-C.5302e2cc6f5c7c4933ebb3394e0c41bc?rik=z4u%2b7efba5Mgxw&riu=http%3a%2f%2fcomic-cons.xyz%2fwp-content%2fuploads%2fStar-Wars-avatar-icon-C3PO.png&ehk=kBBvCvpJMHPVpdfpw1GaH%2brbOaIoHjY5Ua9PKcIs%2bAc%3d&risl=&pid=ImgRaw&r=0'
default_mode = '知识库问答'
defalut_kb = ''
def robot_say(msg, kb=''):
st.session_state['history'].append(
{'is_user': False, 'type': MsgType.TEXT, 'content': msg, 'kb': kb})
def user_say(msg):
st.session_state['history'].append(
{'is_user': True, 'type': MsgType.TEXT, 'content': msg})
def format_md(msg, is_user=False, bg_color='', margin='10%'):
'''
将文本消息格式化为markdown文本, 指定user 和 robot消息背景色、左右位置等
Parameters
----------
msg: 文本内容
bg_color: 指定markdown文本的背景颜色
'''
if is_user:
bg_color = bg_color or ST_CONFIG.user_bg_color
text = f'''
<div style="background:{bg_color};
margin-left:{margin};
word-break:break-all;
float:right;
padding:2%;
border-radius:2%;">
{msg}
</div>
'''
else:
bg_color = bg_color or ST_CONFIG.robot_bg_color
text = f'''
<div style="background:{bg_color};
margin-right:{margin};
word-break:break-all;
padding:2%;
border-radius:2%;">
{msg}
</div>
'''
return text
def message(msg,
is_user=False,
msg_type=MsgType.TEXT,
icon='',
bg_color='',
margin='10%',
kb='',
):
'''
渲染单条消息(包括双方头像、聊天文本)。目前仅支持文本
返回第2列对象
'''
# 定义界面中的列,若参数为一个整数n,则意为插入n个等尺寸列;若为列表[1, 10, 1]则意为插入3列,数值为各列之间的倍数(数值为小数,则指占界面百分比)
# 该函数中,列cols[0]为robot头像,cols[2]为user头像,cols[1]为聊天消息(markdown文本)
cols = st.columns([1, 10, 1])
empty = cols[1].empty() # 将第2列初始化为空
if is_user:
icon = icon or ST_CONFIG.user_icon
bg_color = bg_color or ST_CONFIG.user_bg_color
cols[2].image(icon, width=40) # 第3列展示user头像
if msg_type == MsgType.TEXT:
text = format_md(msg, is_user, bg_color, margin)
empty.markdown(text, unsafe_allow_html=True) # 将第2列填充user的Markdown文本
else:
raise RuntimeError('only support text message now.')
else:
icon = icon or ST_CONFIG.robot_icon
bg_color = bg_color or ST_CONFIG.robot_bg_color
cols[0].image(icon, width=40) # 第1列展示robot头像
if kb:
cols[0].write(f'({kb})') # 用于向Web应用程序添加任何内容??
if msg_type == MsgType.TEXT:
text = format_md(msg, is_user, bg_color, margin)
empty.markdown(text, unsafe_allow_html=True) # 将第2列填充robot的Markdown文本
else:
raise RuntimeError('only support text message now.')
return empty
def output_messages(
user_bg_color='',
robot_bg_color='',
user_icon='',
robot_icon='',
):
with chat_box.container(): # 为st添加一个多元素容器(chat_box为前面定义的st的占位符)
last_response = None
for msg in st.session_state['history']:
bg_color = user_bg_color if msg['is_user'] else robot_bg_color
icon = user_icon if msg['is_user'] else robot_icon
empty = message(msg['content'],
is_user=msg['is_user'],
icon=icon,
msg_type=msg['type'],
bg_color=bg_color,
kb=msg.get('kb', '')
)
if not msg['is_user']:
last_response = empty
return last_response
if __name__ == "__main__":
webui_title = """
👍langchain-ChatGLM WebUI
"""
robot_say_ininfo = ('您好:\n\n'
'欢迎使用本机器人聊天界面(初版),基于streamlit我还在努力中哦~~🎉') # 注意这个写法,只有一对引号的话第二行会为其他背景色
LLM_MODEL = 'baichuan-130b'
EMBEDDING_MODEL = 'ernie-3.0-base-zh'
modes = ['LLM 对话', '知识库问答', 'Bing搜索问答', '知识库测试']
st.set_page_config(webui_title, layout='wide') # webui_title是浏览器选项卡中显示的页面标题
# session_state在st rerun过程中定义、存储共享变量,可以存储任何对象;只可能在应用初始化时被整体重置。而rerun不会重置session state。
# 调用其中变量的方法:st.session_state.[变量的key]
st.session_state.setdefault('history', []) # history为变量的key,[]为初始值
# 定义“等待提示”,注意每次对界面操作都会加载一次!!!?
with st.spinner(f'正在加载模型({LLM_MODEL} + {EMBEDDING_MODEL}),请耐心等候...'):
time.sleep(2)
# 定义侧边栏
with st.sidebar:
robot_say(robot_say_ininfo)
def on_mode_change():
m = st.session_state.mode
robot_say(f'已切换到"{m}"模式')
index = 0
mode = st.selectbox('对话模式', modes, index,
on_change=on_mode_change, key='mode') # on_change为复选框操作出发的变化函数
print('mode:', mode) # 打印的结果即为mode里面的值(字符串)
chat_box = st.empty() # 为st应用添加一个占位符
# 创建表单容器,clear_on_submit=True表示在用户按下提交按钮后,表单内的所有小部件都将重置为其默认值
with st.form('my_form', clear_on_submit=True):
cols = st.columns([8, 1])
question = cols[0].text_input(
'temp', key='input_question', label_visibility='collapsed') # 第1列为文本输入框
print('question:', question) # 打印结果即为文本框中输入的文本
def on_send():
q = st.session_state.input_question
user_say(q)
print("st.session_state['history']:", st.session_state['history'])
last_response = output_messages()
# last_response.markdown(
# format_md(st.session_state['history'][-1]['content'], False),
# unsafe_allow_html=True
# )
submit = cols[1].form_submit_button('发送', on_click=on_send) # 第2列为按钮,on_click为点击按钮出发的操作函数
output_messages() # 不执行这个函数页面会不展示聊天历史
首次运行结果:
操作效果:
五、其他
1、FastChat
- fastchat的GitHub
- fastchat是一个基于聊天机器人方式对LLM快速训练、部署、评估的开放平台: 将LLM下载到本地后,可以通过fastchat中的 CLI 、Web 两种方式加载 / 调用 / 启动LLM,快速与LLM进行对话:
-
CLI方式(命令行交互界面):
python -m fastchat.serve.cli --model-path [a LLM local folder or a Hugging Face repo name]
- -device cpu:使用CPU运行;
- -num-gpus 2:指定使用的GPU数量;
- -max-gpu-memory 8GiB:指定每个GPU使用的最大内存8G。 -
Web方式(web UI交互界面):
需要三个主要组件:web servers(与用户的接口)、model workers(组织模型)、a controller(协调前两者)
(1)命令行启动:
① python -m fastchat.serve.controller
② python -m fastchat.serve.model_worker --model-path [a LLM local folder or a Hugging Face repo name]
③ python -m fastchat.serve.[gradio_web_server / openai_api_server ]
openai_api_server:启动RESTful API server,为其支持的LLM提供OpenAI-compatible APIs(即通过该命令启动后,可以使用 openai 的方式与model_worker 对应的LLM进行对话);后续也可以接入Langchain(内在逻辑??)。
- -host [ localhost ] --port [ 8000 ]:启动RESTful API server时,需要指定host、port
(2)基于fastchat模块:
from fastchat.serve.controller import Controller, app
from fastchat.serve.model_worker import (AWQConfig, GptqConfig, ModelWorker, app, worker_id)
from fastchat.serve.openai_api_server import (CORSMiddleware, app, app_settings)
CLI的结果:(81个CPU,一个问题要等2分钟差不多……)
web方式启动后,后续基于python的操作:
可以基于openai模块(如下例),也可以基于langchain中的 LLMChain 和 from langchain.chat_models import ChatOpenAI
-
CLI方式(命令行交互界面):
import openai
openai.api_key = "EMPTY"
openai.api_base = "http://localhost:8000/v1"
def test_chat_completion_stream(model = "chatglm2-6b"):
# 流式的测试,参考:https://github.com/lm-sys/FastChat/blob/main/tests/test_openai_api.py
messages = [
{"role": "user",
"content": "Hello! What is your name?"}
]
res = openai.ChatCompletion.create(model=model, messages=messages, stream=True)
for chunk in res:
content = chunk["choices"][0]["delta"].get("content", "")
print(content, end="", flush=True)
print()
def text_chat_completion(model = "chatglm2-6b"):
# create a chat completion
completion = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": "Hello! What is your name?"}]
)
# print the completion
print(completion.choices[0].message.content)
【注意】(Ubuntu)在输入问题的时候删除错别字重新输入后,回车会报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe3 in position 15: invalid continuation byte
1)安装
pip install fschat
2、FastAPI
- FastAPI的GitHub
- FastAPI 是一个高性能 Web 框架,用于构建 API
1)安装文章来源:https://www.toymoban.com/news/detail-764651.html
pip install fastapi
pip install uvicorn
其他参考:
从LangChain+LLM的本地知识库问答到LLM与知识图谱、数据库的结合文章来源地址https://www.toymoban.com/news/detail-764651.html
到了这里,关于LLM预备知识、工具篇——LLM+LangChain+web UI的架构解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!