- Java后端-学习路线-笔记汇总表【黑马程序员】
- ElasticSearch-学习笔记01【ElasticSearch基本介绍】【day01】
- ElasticSearch-学习笔记02【ElasticSearch索引库维护】
- ElasticSearch-学习笔记03【ElasticSearch集群】
- ElasticSearch-学习笔记04【Java客户端操作索引库】【day02】
- ElasticSearch-学习笔记05【SpringDataElasticSearch】
目录
06-postman工具的安装
01、新建索引
02、postman工具介绍
07-使用postman创建索引
01、创建索引
02、设置映射mappings
08-使用postman设置mapping映射
01、创建索引后设置Mapping
02、删除索引库
09-删除索引库
01、使用postman删除索引库
02、复合查询-PUT
03、复合查询-POST
04、复合查询-DELETE
10-向索引库中添加文档
01、ES与关系型数据库的通俗比较
02、创建文档
03、不指定id添加文档
11-使用head向索引库中添加文档
12-删除文档操作
13-修改文档操作
14-根据id查询文档
01、创建数据
02、根据id查询数据
15-根据关键词进行查询
16-queryString查询
17-使用head插件查询索引库
18-在ES中查看分析器的分词效果
01、中文分词测试
02、英文分词测试
03、IK分词器
06-postman工具的安装
01、新建索引
新建索引
分片数:分成5份;副本数:每1片都有一个备份。
在对es进行管理的时候一般都使用http方式发送一些json数据来进行控制。
在复合查询处发送json数据,但是直接用网页编写json数据较为麻烦,使用postman工具编写json数据较为方便。





02、postman工具介绍
postman是一个英语单词,名词,作名词时意为“邮递员;邮差”。
Postman是一个接口测试工具,在做接口测试的时候,Postman相当于一个客户端,它可以模拟用户发起的各类HTTP请求,将请求数据发送至服务端,获取对应的响应结果, 从而验证响应中的结果数据是否和预期值相匹配;并确保开发人员能够及时处理接口中的bug,进而保证产品上线之后的稳定性和安全性。 它主要是用来模拟各种HTTP请求的(如:get/post/delete/put..等等),Postman与浏览器的区别在于有的浏览器不能输出Json格式,而Postman更直观接口返回的结果。
postman:发送http请求,接收服务端响应的工具。es支持restful形式的接口。

07-使用postman创建索引
01、创建索引
Postman官网:Postman
增删改查:get、post、put、delete。
- 查询数据:GET
- 修改数据:POST
- 增加数据:PUT
- 删除数据:DELETE
发送json数据-http请求-创建索引库。Body:请求数据,选择raw(原生)。


02、设置映射mappings
{
"mappings": {
"article": {//type名称,相当于表,type可以有多个。
"properties": {//属性,字段
"id": {
"type": "long",
"store": true,
"index": "not_analyzed"//默认不索引
},
"title": {
"type": "text",
"store": true,
"index": "analyzed",
"analyzer": "standard"//标准分词器
},
"content": {
"type": "text",//文本类型
"store": true,//存储
"index": "analyzed",//要索引
"analyzer": "standard"//标准分词器
}
}
}
}
}

08-使用postman设置mapping映射
01、创建索引后设置Mapping
http://127.0.0.1:9200/blog/hello/_mappings
- blog:索引名称
- hello:type名称
- _mappings:设置mappings
{
"hello": {//type名称,相当于表,type可以有多个。
"properties": {//属性,字段
"id": {
"type": "long",
"store": true,
"index": "not_analyzed"//默认不索引
},
"title": {
"type": "text",
"store": true,
"index": "analyzed",
"analyzer": "standard"//标准分词器
},
"content": {
"type": "text",//文本类型
"store": true,//存储
"index": "analyzed",//要索引
"analyzer": "standard"//标准分词器
}
}
}
}
先创建索引库,后设置mappings也是可以的。


02、删除索引库
删除索引库:

09-删除索引库
01、使用postman删除索引库

02、复合查询-PUT

03、复合查询-POST
{
"hello": {
"properties": {
"id": {
"type": "long",
"store": true,
"index": "not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index": "analyzed",
"analyzer": "standard"
},
"content": {
"type": "text",
"store": true,
"index": "analyzed",
"analyzer": "standard"
}
}
}
}
{"hello":{"properties":{"id":{"type":"long","store":true,"index":"not_analyzed"},"title":{"type":"text","store":true,"index":"analyzed","analyzer":"standard"},"content":{"type":"text","store":true,"index":"analyzed","analyzer":"standard"}}}}

04、复合查询-DELETE

10-向索引库中添加文档
01、ES与关系型数据库的通俗比较
(6)基于 Elasticsearch 的实践——建立一个员工目录_furuiyang_的博客-CSDN博客_人力体系文件如何建目录
es 集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
ES与关系型数据库的通俗比较 关系型数据库 Relational DB Databases(数据库) Tables(数据表) Rows(行) Columns(字段) ES Elasticsearch Indices(索引库) Types(表) Documents(记录) Fields(字段)
02、创建文档
请求url:POST localhost:9200/blog/hello/1
- blog:index(索引库)
- hello:type(表)
- 1:文档id

请求体:
{
"id": 1,
"title": "新添加的文档",
"content": "新添加的文档的内容。"
}请求成功后返回的数据:
{
"_index": "blog",
"_type": "hello",
"_id": "1", //文档真正的id
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1, //成功
"failed": 0
},
"created": true
}
03、不指定id添加文档
不指定id的话,es会自动生成id,类似于uuid,保证id唯一不重复。一般情况下,保证id字段和真正的主键一致。


11-使用head向索引库中添加文档
{
"id": 2,
"title": "共命运促发展",
"content": "同心筑梦,命运与共。"
}


12-删除文档操作

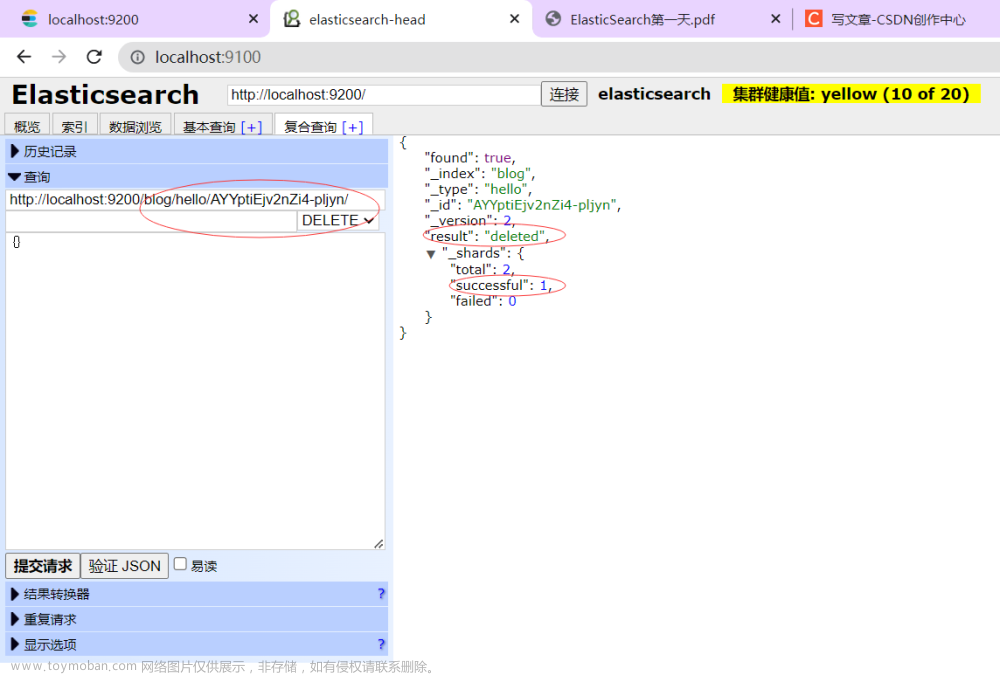
13-修改文档操作


{
"id": 1,
"title": "新添加的文档1",
"content": "新添加的文档的内容。"
}
{
"id": 123,
"title": "修改后的文档1",
"content": "修改之后的文档内容。"
}

14-根据id查询文档
三种查询方式:
- 根据id查询
- 根据关键词查询
- 根据字符串查询
01、创建数据
{
"id": 2,
"title": "修改后的文档2",
"content": "修改之后的文档内容2。"
}
{
"id": 3,
"title": "修改后的文档3",
"content": "修改之后的文档内容3。"
}
{
"id": 4,
"title": "修改后的文档4",
"content": "修改之后的文档内容4。"
}
{
"id": 5,
"title": "修改后的文档5",
"content": "修改之后的文档内容5。"
}
{
"id": 6,
"title": "修改后的文档6",
"content": "修改之后的文档内容6。"
}

02、根据id查询数据

15-根据关键词进行查询
{
"query": {
"term": {
"title": "修"
}
}
}


16-queryString查询
{//查询文档-queryString查询
"query": {
"query_string": {//使用字符串查询
"default_field": "title",//指定默认搜索域
"query": "文档内容"//指定查询条件
}
}
}查询成功案例(分词之后再进行查询):
查询失败案例:


17-使用head插件查询索引库
查询方式(条件之间的逻辑运算):
- must:必须满足;
- must_not:必须不满足(在查询到结果的基础上进行取反过滤);
- should:应该满足;
- match_all:查询全部,不指定条件,类似于“select *”;
- id、term:关键词、query_string:待分析查询;
- range:范围查询;
- fuzzy:模糊查询;
- widcard:通配符查询。


18-在ES中查看分析器的分词效果
01、中文分词测试
http://127.0.0.1:9200/_analyze?analyzer=standard&pretty=true&text=我是程序员

02、英文分词测试
http://127.0.0.1:9200/_analyze?analyzer=standard&text=variously spelled wildcard or wild-card, also known as at-large berth
分词结果:
{
"tokens": [
{
"token": "variously",
"start_offset": 0,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "spelled",
"start_offset": 10,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "wildcard",
"start_offset": 18,
"end_offset": 26,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "or",
"start_offset": 27,
"end_offset": 29,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "wild",
"start_offset": 30,
"end_offset": 34,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "card",
"start_offset": 35,
"end_offset": 39,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "also",
"start_offset": 41,
"end_offset": 45,
"type": "<ALPHANUM>",
"position": 6
},
{
"token": "known",
"start_offset": 46,
"end_offset": 51,
"type": "<ALPHANUM>",
"position": 7
},
{
"token": "as",
"start_offset": 52,
"end_offset": 54,
"type": "<ALPHANUM>",
"position": 8
},
{
"token": "at",
"start_offset": 55,
"end_offset": 57,
"type": "<ALPHANUM>",
"position": 9
},
{
"token": "large",
"start_offset": 58,
"end_offset": 63,
"type": "<ALPHANUM>",
"position": 10
},
{
"token": "berth",
"start_offset": 64,
"end_offset": 69,
"type": "<ALPHANUM>",
"position": 11
}
]
}文章来源:https://www.toymoban.com/news/detail-764875.html

03、IK分词器
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。文章来源地址https://www.toymoban.com/news/detail-764875.html
到了这里,关于ElasticSearch-学习笔记02【ElasticSearch索引库维护】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!







