1.项目分析
- 数据来源:巨潮资讯
- 项目需求:按照股票代码,公司名称,年报全称,年份,下载链接等要素写入excel表
- 使用语言:python
- 第三方库:requests, re , time等
成品展示:

2. 快速上手
废话就到这里,直接开干!
1.寻找接口
众所周知,爬取网页数据一般可以通过寻找网页结构规律和爬取接口两种方式,简单起见,笔者直接使用了搜索接口。
下图为巨潮资讯网首页。

小手一点,年报直接出现,这是针对具体公司的年报可以直接搜索,那么该如何爬取所有的记录呢?
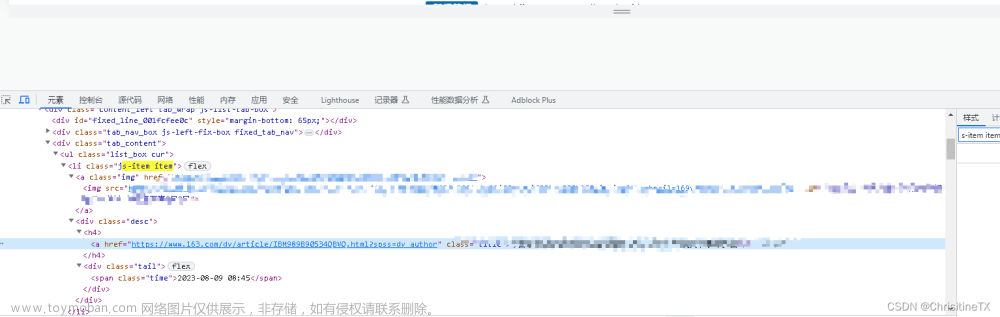
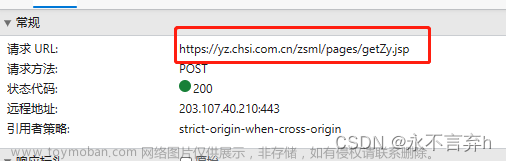
F12打开开发者工具,进行简单的网络抓包。
通过切换页面,发现网络上有响应,发现搜索接口。

没错,就是这段链接!
searchkey:搜索内容;pageNum:当前页码; type = shj:沪深京主板……
当然,也可以加入参数&sdate=2015-01-01&edate=2022-01-01&来指定搜索链接。
直接get,返回一个json文件,也包含股票代码,公司名称,还有关键的下载链接!

2.获取数据
既然找到了json文件,那么就很好入手,直接打开pycharm。
先根据接口,写好访问参数。
import requests
import re
import openpyxl
import time
# 设置搜索参数
search_key = "年报"
url_template = "http://www.cninfo.com.cn/new/fulltextSearch/full?searchkey={}&sdate=2016-01-01&edate=2017-01-01&isfulltext=false&sortName=pubdate&sortType=desc&pageNum={}&type=shj"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}然后使用request进行访问,注意程序的稳健性!爬取众多文件很容易报错,所以要做好异常机制处理,笔者做了失败重试以及多次失败后直接跳过的机制。
# 发送HTTP请求并获取响应
all_results = []
page_num =1 #设置首页
total_pages = 1 #初始化最大页面
max_retries = 2 #最大重试次数
retry_count = 0
while page_num <= total_pages:
url = url_template.format(search_key, page_num)
response = None
# 重试机制
while retry_count <= max_retries:
# 发送请求
try:
response = requests.get(url,headers=headers)
response.raise_for_status()
break
except requests.exceptions.RequestException as e:
print(f"出现错误!: {e}")
print(f"5秒后重试...")
time.sleep(5)
retry_count += 1
if retry_count > max_retries:
print(f"{max_retries} 次重试后均失败. 跳过第 {page_num}页.")
page_num += 1
retry_count = 0
continue
然后就是不断循环,将每次得到的json文件合并到all_result中
# 解析数据
try:
data = response.json()
all_results.extend(data["announcements"])
total_pages = data["totalpages"]
print(f"正在下载第 {page_num}/{total_pages}页")
page_num += 1
retry_count = 0
except (ValueError, KeyError) as e:
print(f"Error parsing response data: {e}")
print(f"5秒后重试...")
time.sleep(5)
retry_count += 1
continue
这一部是关键!json文件如果处理过程中报错,很容易前功尽弃!又需要重头开始。
经过笔者测试,该接口最大页数为2000,大于该数字必定报错,因此爬取时可以限定时间范围。
3.保存数据
当json文件合并好后,就是对数据的分析和保存了!
笔者使用了openpyxl库来创建excel表格。
由于json文件数据过于杂乱,因此必须做好剔除工作。
# 创建Excel文件并添加表头
workbook = openpyxl.Workbook()
worksheet = workbook.active
worksheet.title = "Search Results"
worksheet.append(["公司代码", "公司简称", "标题", "发布日期", "年报链接"])
# 定义需要剔除的标题关键词
exclude_keywords = ["摘要", "英文版", "披露", "风险提示", "督导","反馈","回复","业绩","说明会","意见","审核","独立董事","半年","已取消","补充","提示性","制度","规程","审计","ST","公告","声明","说明","受托"]
# 解析搜索结果并添加到Excel表格中
for item in all_results:
company_code = item["secCode"]
company_name = item["secName"]
title = item["announcementTitle"].strip()
# 剔除不需要的样式和特殊符号,并重新组合标题
title = re.sub(r"<.*?>", "", title)
title = title.replace(":", "")
title = f"《{title}》"
adjunct_url = item["adjunctUrl"]
year = re.search(r"\d{4}", adjunct_url).group()
publish_time = f"{year}"
#拼串,将PDF文件的下载链接拼完整!
announcement_url = f"http://static.cninfo.com.cn/{adjunct_url}"
# 检查标题是否包含排除关键词
exclude_flag = False
for keyword in exclude_keywords:
if keyword in title:
exclude_flag = True
break
# 如果标题不包含排除关键词,则将搜索结果添加到Excel表格中
if not exclude_flag:
worksheet.append([company_code, company_name, title, publish_time, announcement_url])
最后只需要将数据全部保存,就大功告成了!
workbook.save(f"上市企业年报链接_2015.xlsx") 文章来源:https://www.toymoban.com/news/detail-765322.html
文章来源:https://www.toymoban.com/news/detail-765322.html
笔者已将部分年报打包,关注同名公众号回复「年报」即可获取哦~文章来源地址https://www.toymoban.com/news/detail-765322.html
到了这里,关于【Python爬虫实战】1.爬取A股上市公司年报链接并存入Excel的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!