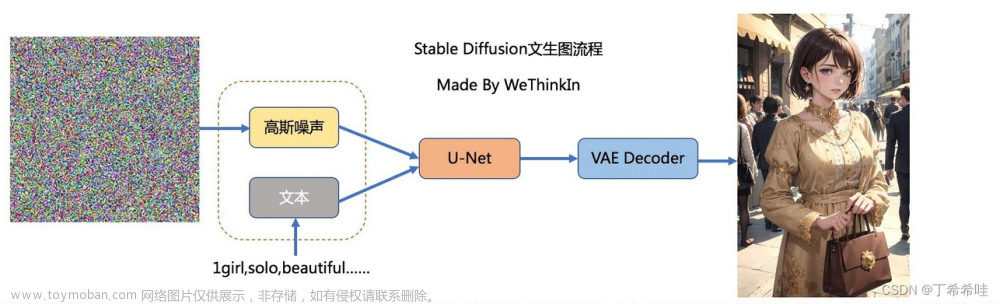
文生图模型之Stable Diffusion - 知乎通向AGI之路码字真心不易,求点赞! https://zhuanlan.zhihu.com/p/6424968622022年可谓是 AIGC(AI Generated Content)元年,上半年有文生图大模型DALL-E2和Stable Diffusion,下半年有OpenAI的文本对话大模型Ch…https://zhuanlan.zhihu.com/p/617134893【stable-diffusion企业级教程08】图文数据集以及标签模型! - 知乎1、数据集1.1 CC数据集(Conceptual Captions)1)cc3m:语言:英文简介: 该数据集由谷歌于 2018 年发布,数据集共包括 330 万对图像-标题对。团队通过创建自动 pipeline,从数十亿网页中提取,过滤和处理候选图像…https://zhuanlan.zhihu.com/p/643722688中文多模态数据集汇总_数据集-阿里云天池本文整理汇总了业界常用的多模态中文数据集,提供了每个数据集的简介、官网、下载地址、Github代码等信息,方便算法研究人员学习研究。https://tianchi.aliyun.com/dataset/1457841.数据集
1.1 laion数据集
laion2B-en数据集,是laion5B的一个子集,更具体的说它是laion-5B中的英文数据集,laion-5B是从网页数据common crawel中筛选出来的图像文本对,包含5.85B的图像文本对,其中文本为英文的数据量为2.32B,这就是laion-2B-en数据集。中文预计143M,有效数据80M,

图片的width和height均在256以上的样本量为1324M,在512以上的是488M,在1024以上为76M,文本平均长度为67.

1.2 WUkong数据集
包括1亿对图文对


1.3 Zero数据
Zero,23M,图像和描述对,从互联网上收集,根据用户点击从50亿图文对中筛选出来的,还有一个子数据集,Zero-Corpus-Sub,是供研究用的,2.3M对,是上述数据集的10%。
2.模型训练
2.1 runwayml 1.5
在laion-2B-en数据集上评分为5以上训练的,先用256x256,再用512x512,用了32台8卡A100 40G,bs=32x8x2x2=2048。训练了150000小时,大约25天。
2.2 stability 2.0
在laion-2B-en数据集上评分为4.5以上训练的,
2.3 stability 2.1
sd 2.1在sd 2.0基础上放开了一些nsfw过滤掉的数据,
2.4 mosicML sd 2
使用laion-5B的一个子集,其中包括带有纯英文标题且审美得分为4.5+的样本,第一阶段使用分辨率大于256x256的0.79B样本,第二阶段使用大于512x512的0.3B样本,128台A100,第一个阶段耗时1.6天,55万次迭代,第二阶段耗时4.9天,85万次迭代。
2.5 pai-diffusion
用Wukong数据集中的2千万中文图文数据对进行了约20天的预训练。
2.6 chineseclip
laion-5B中的zh文本大概1.1亿,悟空的7千万,加一下自有数据,总量大概2亿。
2.7 skypaint 天工巧绘
skyclip,由openai-clip蒸馏得到,skyclip训练数据来源:中英文机器翻译任务平行语料、联合国中英文平行语料、laion中英文部分语料、wukong部分中文语料、AI-Challenger翻译任务中英文语料、古诗词中英文语料和提示词手册/魔法书中常见词组合而成的中英文语料。
采用筛选过的laion数据集,宣传文说有1.2亿,文本前使用sai-v1 art作为tag,sd1.5作为预训练模型,16xA100训练了50个小时。
2.8 腾讯混元文生图模型
20亿+未清洗的青铜诗句,用来对所有模型进行粗加工,预训练;6亿+白银数据,用来对生成模型进一步加工;1.12亿+黄金数据,精调训练,数据闭环反馈迭代。
2.9 网易丹青
8亿加数据
2.10 Taiyi
Taiyi sd:
Noah-Wukong数据集(100M)和Zero数据集(23M)用作预训练的数据集,先用IDEA-CCNL/Taiyi-CLIP-RoBERTa-102M-ViT-L-Chinese对这两个数据集的图文对相似性进行打分,取CLIP Score大于0.2的图文对作为训练集。 基于0.2亿筛选过的中文图文对训练。
Taiyi clip:
Noah-Wukong数据集(100M)和Zero数据集(23M)用作预训练的数据集。在悟空数据集和zero数据集上预训练24轮,在A100x32上训练了6天。
2.11 sdxl
未透露训练数据,直说采用内部数据训练,但大概率也是laion-2b-en数据。
2.12 altdiffusion
Wudao数据集和Laion。
2.13 VisCPM-Paint
CPM-Bee(10B)作为文本编码器,unet作为图像解码器,训练中,语言模型参数固定,使用sd2.1初始化视觉编码器,在laion-2b英文数据上训练。进一步在20M清洗后的原生中文图文对数据训练训练,以及120M翻译到中文的图文对数据训练。
2.14 中文StablDiffusion-通用领域
中文StableDiffusion-通用领域https://modelscope.cn/models/damo/multi-modal_chinese_stable_diffusion_v1.0/summary
本模型采用的是Stable Diffusion 2.1模型框架,将原始英文领域的OpenCLIP-ViT/H文本编码器替换为中文CLIP文本编码器chinese-clip-vit-huge-patch14,并使用大规模中文图文pair数据进行训练。训练过程中,固定中文CLIP文本编码器,利用原始Stable Diffusion 2.1 权重对UNet网络参数进行初始化、利用64卡A100共训练35W steps。训练数据包括经中文翻译的公开数据集(LAION-400M、cc12m、Open Images)、以及互联网搜集数据,经过美学得分、图文相关性等预处理进行图像过滤,共计约4亿图文对。
2.15 文本到图像生成扩散模型-中英文-通用领域-tiny
文本到图像生成扩散模型-中英文-通用领域-tinyhttps://modelscope.cn/models/damo/cv_diffusion_text-to-image-synthesis_tiny/summary
文本到图像生成模型由文本特征提取与扩散去噪模型两个子网络组成。文本特征提取子网络为StructBert结构,扩散去噪模型为unet结构。通过StructBert提取描述文本的语义特征后,送入扩散去噪unet子网络,通过迭代去噪的过程,逐步生成复合文本描述的图像。训练数据包括LAION400M公开数据集,以及互联网图文数据。文本截断到长度64 (有效长度62),图像缩放到64x64进行处理。模型分为文本特征提取与扩散去噪模型两个子网络,训练也是分别进行。文本特征提取子网络StructBert使用大规模中文文本数据上预训练得到。扩散去噪模型则使用预训练StructBert提取文本特征后,与图像一同训练文本到图像生成模型。
2.16 通义-文本生成图像大模型-中英文-通用领域
通义-文本生成图像大模型-中英文-通用领域https://www.modelscope.cn/models/damo/cv_diffusion_text-to-image-synthesis/summary
整体模型参数约50亿,支持中英双语输入。训练数据包括LAION5B, ImageNet, FFHQ, AFHQ, WikiArt等公开数据集。经过美学得分、水印得分、去重等预处理进行图像过滤。模型分为文本特征提取、文本特征到图像特征生成、级联扩散生成模型等子网络组成,训练也是分别进行。文本特征提取使用大规模图文样本对数据上训练的CLIP的文本分支得到。文本到图像特征生成部分采用GPT结构,是一个width为2048、32个heads、24个blocks的Transformer网络,利用causal attention mask实现GPT预测。64x64、256x256、1024x1024扩散模型均为UNet结构,在64x64、256x256生成模型中使用了Cross Attention嵌入image embedding条件。为降低计算复杂度,在256扩散模型训练过程中,随机64x64 crop、128x128 crop、256x256 crop进行了multi-grid训练,来提升生成质量;在1024扩散模型中,对输入图随机256x256 crop。
2.17 腾讯太极
原始的数据量级是10亿级,经过过滤我们最终保留了1亿高质量数据,全面覆盖了包括中英文场景、风景、物体、名人、游戏、动画、动漫、艺术、概念的图片。使用的过滤方法包括下面这些步骤文章来源:https://www.toymoban.com/news/detail-765379.html
- 根据图片width、height绝对值和比例等过滤
- 根据简单的纹理复杂度过滤
- 根据太极-CLIP图文匹配模型的图文相关度过滤
- 根据laion aesthitic提出来的美学分数过滤
我们发现训练数据的质量对于模型的效果非常关键,宁缺毋滥;另外我们刚开始发现图片中包含了太多的卡通图片,导致最后生成的效果也是偏卡通风格的,因此后面把卡通图的比例降低,模型效果也随之正常。后期我们也是专门收集了一批游戏和各种风格的数据,引入模型训练,使模型能够适配各种风格。数据迭代跟模型迭代是同步进行的,不断的优化我们的数据集合,让模型生成效果更优。文章来源地址https://www.toymoban.com/news/detail-765379.html
到了这里,关于stable diffusion模型训练时数据量的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!