Wei, Yi, et al. “Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
重点记录
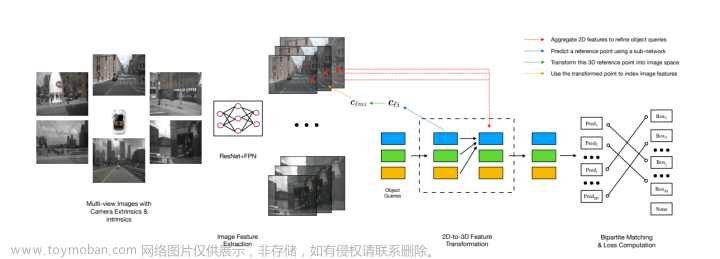
- 将占用网格应用到多个相机构成的3D空间中;
- 使用BEVFormer中的方法获取3D特征, 然后使用交叉熵损失计算loss;
- 和BEVFormer区别是BEV中z轴高度为1, 这里为获取3D特征不能设置为1, 文中为16;
- 注意会生成不同尺度的3D特征, 会在每个尺度上做一个监督;
- 提出了稠密占用网格语义标签生成方法;
- 分离lidar点云中的静态场景和动态目标为两个集合
- 将静态场景转换到参考坐标系中
- 将运动目标归一化到相对坐标系中
- 根据当前帧pose从参考坐标系中恢复静态场景
- 根据当前帧中的物体ID将运动目标填充回来
- 对当前恢复并填充完的点云进行泊松重建
- 用最近邻给稠密给标签, 体素化得到占用网格
稠密语义标签生成
Needs
- lidar 点云
- lidar 点云bbox标注, 需要有类别和tracking ID
- lidar 分割标注 / 或者图像分割标注
步骤
场景划分
- 一个场景中的所有点云根据bbox标注划分为静态场景 P s P_s Ps 和动态目标 P o P_o Po 两个集合, 分割标注和静态场景处理相似, 记为 P s s e g P^{seg}_s Psseg, 注意: 只有关键帧才有语义标签
- 静态场景, 分割标注所有点云变换到参考坐标系(通常为场景开始帧), 然后将所有点云合并
- 动态目标点云按照tracking ID分组, 每组中的为不同frame中物体, 假如有物体1在场景中出现10帧,可以表示为 {1: [frame_i_pts, …]}, 这里的frame_i_pts表示在第i帧中出现的bbox框中的点云, 并且需要将frame_i_pts点云归一化操作, 1.bbox最小点作为坐标原点 2.根据yaw角旋转至y轴正方形; 然后将所有场景中物体点云合并, 得到{1: pts1, …}
- 动态目标
P
o
P_o
Po 中点云根据tracking ID分别填充到静态场景
P
s
P_s
Ps 和分割标注
P
s
s
e
g
P^{seg}_s
Psseg中, 得到稠密点云
- 注意: 根据bbox将框外的点云删除
获取当前帧稠密标签
- 根据当前帧位姿将静态场景 P s P_s Ps , 分割标注 P s s e g P^{seg}_s Psseg 变换到当前帧中, 并根据设置的点云范围裁切, 记为 P c u r P_{cur} Pcur 和 P c u r s e g P^{seg}_{cur} Pcurseg
- 将 P c u r P_{cur} Pcur转换成mesh, 然后使用泊松重建, 再离散化得到占用网格(体素), 此步骤用来填充空洞
- 根据 P c u r s e g P^{seg}_{cur} Pcurseg 采用最近邻算法给转换后的占用网格赋值语义标签, 得到稠密占用网格语义标签
Q&A
- 场景中所有帧都会cut动态物体后转换到参考坐标系时, 会不会存在某些帧动态物体未bbox导致没有cut掉, 导致在最终参考坐标系中合并的静态场景中出现动态目标?
- 可能存在上述情况, 静态场景中出现动态目标, 将该场景变换到当前帧, 再填充保留的动态目标, 会出现同一目标出现在两个位置, 导致标签存在歧义; 所以, 需要bbox标注准确且不能漏标; nuscenes场景中的每一帧点云都有bbox标注, 分割语义标签只有关键帧有;
代码
 文章来源:https://www.toymoban.com/news/detail-765392.html
文章来源:https://www.toymoban.com/news/detail-765392.html
open3d 可视化 Occ网格
代码 文章来源地址https://www.toymoban.com/news/detail-765392.html
文章来源地址https://www.toymoban.com/news/detail-765392.html
到了这里,关于[论文笔记] SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!