hadoop完全分布式搭建
1 完全分布式介绍
Hadoop运行模式包括:本地模式(计算的数据存在Linux本地,在一台服务器上 自己测试)、伪分布式模式(和集群接轨 HDFS yarn,在一台服务器上执行)、完全分布式模式。
本地模式:(hadoop默认安装后启动就是本地模式,就是将来的数据存在Linux本地,并且运行MR程序的时候也是在本地机器上运行)
伪分布式模式:伪分布式其实就只在一台机器上启动HDFS集群,启动YARN集群,并且数据存在HDFS集群上,以及运行MR程序也是在YARN上运行,计算后的结果也是输出到HDFS上。本质上就是利用一台服务器中多个java进程去模拟多个服务
完全分布式:完全分布式其实就是多台机器上分别启动HDFS集群,启动YARN集群,并且数据存在HDFS集群上的以及运行MR程序也是在YARN上运行,计算后的结果也是输出到HDFS上。
在真实的企业环境中,服务器集群会使用到多台机器,共同配合,来构建一个完整的分布式文件系统。而在这样的分布式文件系统HDFS相关的守护进程也会分布在不同的机器上,例如:
- NameNode守护进程,尽可能的单独部署在一台硬件性能较好的机器中。
- 其他的每台机器上都会部署一个Datanode守护进程,一般的硬件环境即可。
- SecondaryNameNode守护进程最好不要和NameNode在同一台机器上
2 部署环境
2.1 搭建环境&软件
| 软件 & 平台 | 备注 |
|---|---|
| 宿主系统 | windows10 |
| 虚拟机软件、系统 | vmware17,centos7.5 |
| 虚拟机 | 主机名:node1, ip:192.168.149.111 主机名:node2 , ip:192.168.149.112 主机名:node3 , ip:192.168.149.113 |
| hadoop版本 | hadoop-3.3.0-Centos7-64-with-snappy.tar.gz |
| SSH远程连接工具 | xshell7 |
| 软件安装包上传路径 | /export/software |
| 软件安装路径 | /export/software/jdk 、 /export/software/hadoop |
| jdk环境 | jdk-8u241-linux-x64 |
2.2 守护进程布局
| NameNode | DataNode | SecondaryNameNode | |
|---|---|---|---|
| hadoop1 | √ | √ | |
| hadoop2 | √ | ||
| hadoop3 | √ | √ |
3 准备工作
- 三台机器的防火墙必须是关闭的.
- 确保三台机器的网络配置畅通(NAT模式,静态IP,主机名的配置)
- 确保/etc/hosts文件配置了ip和hostname的映射关系
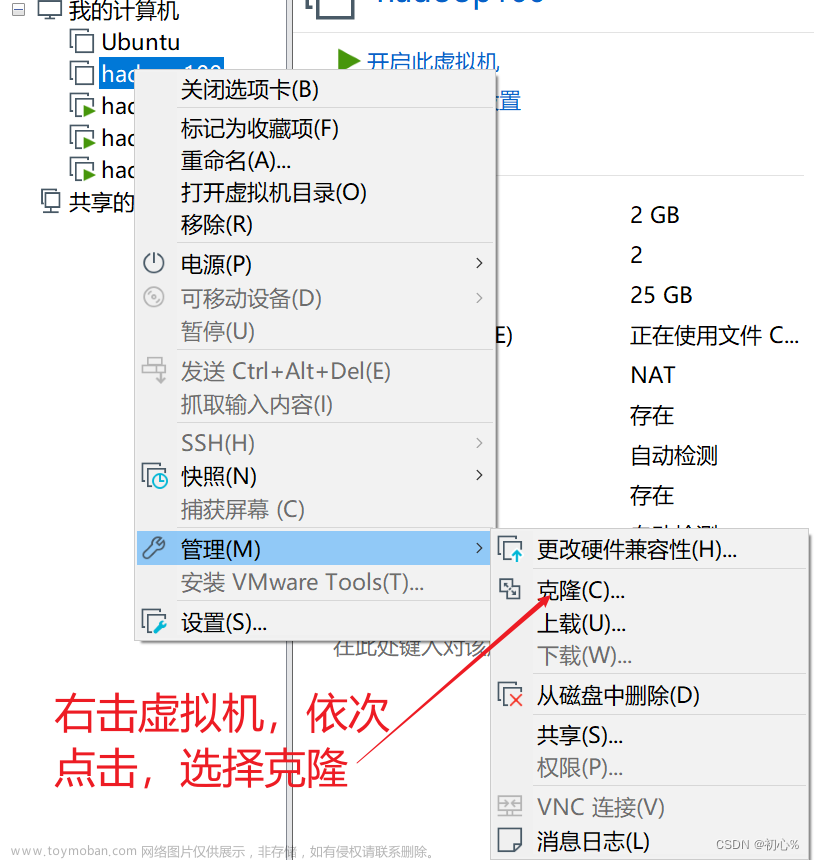
- 确保配置了三台机器的免密登陆认证(克隆会更加方便)
- 确保所有机器时间同步
- jdk和hadoop的环境变量配置
3.0 安装ifconfig 和vim
如果没有ifconfig
yum search ifconfig
yum install net-tools.x86_64
yum -y install vim
3.1 关闭防火墙
# 三台虚拟机均操作
systemctl status firewalld # 查看防火墙状态
systemctl stop firewalld # 关闭防火墙
systemctl disable firewalld # 禁止使用防火墙
3.2 配置静态ip
# 三台虚拟机均操作
vim/etc/sysconfig/network-scripts/ifcfg-ens32
IPADDR="192.168.149.111"
NETMASK="255.255.255.0"
GATEWAY="192.168.149.2"
DNS1="114.114.114.114"
3.3 配置hostname的映射关系
# 三台虚拟机均操作
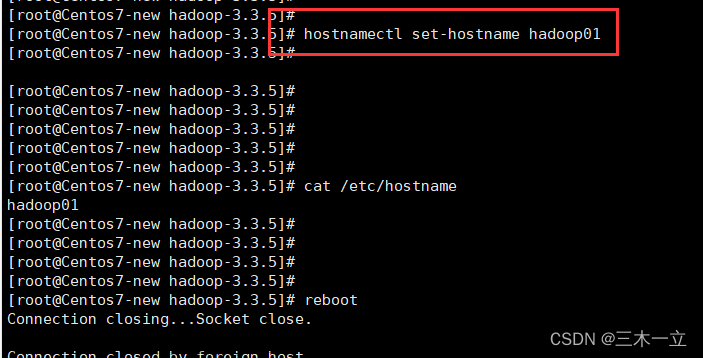
# 1. 修改主机名
vim /etc/hostname
node1
# 或者
hostnamectl --static set-hostname node1
# 2. 修改映射
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.149.111 node1
192.168.149.112 node2
192.168.149.113 node3
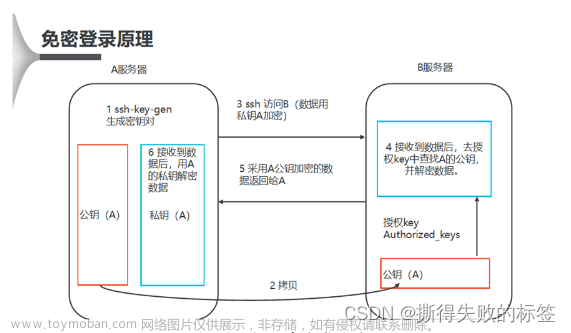
3.4 免密登陆认证
# ssh免密登录(只需要配置node1至node1、node2、node3即可)
# 1. node1生成公钥私钥 (一路回车)
ssh-keygen
# 2. node1配置免密登录到node1 node2 node3
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
sh
# 如果失败,查看/root目录下的.ssh
ls -la
# 将已有的.ssh删除,重复上述操作
# 3. 进行验证
ssh node1
ssh node2
ssh node3
# 同时配置其余两台机器
3.5 时间同步
# 集群时间同步
yum -y install ntpdate
ntpdate ntp5.aliyun.com
3.6 jdk环境变量配置
# 1. 将jdk安装包上传到/export/software/jdk
# 2. 解压jdk安装包
tar -xvf jdk-8u241-linux-x64.tar.gz
# 3. 配置环境变量
vim /etc/profile
export JAVA_HOME=/export/software/jdk/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 4. 重新加载环境变量文件
source /etc/profile
# 5. 查看jdk环境
java -version
3.7 hadoop安装与环境变量配置
# 1. 将hadoop安装包上传到/export/software/hadoop
# 2. 解压hadoop
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
# 3 .配置环境变量
vim /etc/profile
export HADOOP_HOME=/export/software/hadoop/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
4 hadoop文件配置
配置文件位置: /$HADOOP_HOME/etc/hadoop
4.1 core-site.xml
<!-- 设置namenode节点 -->
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9820</value>
</property>
<!-- 设置Hadoop本地保存数据路径
hdfs基础路径,被其他属性所依赖的路径
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/software/hadoop/hadoop-3.3.0/tmp</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
4.2 hdfs-site.xml
<!-- 块的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置SNN进程运行机器位置信息
secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>node1:9870</value>
</property>
4.3 hadoop-env.sh
#文件最后添加
export JAVA_HOME=/export/software/jdk/jdk1.8.0_241
# Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4.4 workers
node1
node2
node3
4.5 mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
4.6 yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
5 启动hadoop
5.1 格式化namenode
(首次启动)格式化namenode文章来源:https://www.toymoban.com/news/detail-765434.html
hdfs namenode -format
5.2 启动服务
start-dfs.sh # 启动HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
stop-dfs.sh # 停止HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
hadoop-daemon.sh start namenode # 只开启NameNode
hadoop-daemon.sh start secondarynamenode # 只开启SecondaryNameNode
hadoop-daemon.sh start datanode # 只开启DataNode
hadoop-daemon.sh stop namenode # 只关闭NameNode
hadoop-daemon.sh stop secondarynamenode # 只关闭SecondaryNameNode
hadoop-daemon.sh stop datanode # 只关闭DataNode
start-all.sh # 启动所有服务
stop-all.sh # 关闭所有服务
5.3 查看节点
jps
# node1
6371 NameNode
7461 Jps
7094 NodeManager
6519 DataNode
6942 ResourceManager
# node2
3617 DataNode
3938 Jps
3731 SecondaryNameNode
3815 NodeManager
# node3
3594 Jps
3355 DataNode
3471 NodeManager
5.4 开启页面
Web UI页面文章来源地址https://www.toymoban.com/news/detail-765434.html
- HDFS集群:http://192.168.149.111:9870/
- YARN集群:http://192.168.149.111:8088/
到了这里,关于hadoop01_完全分布式搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!