CSRF-Token 机制是 Web 应用程序中常用的安全机制,它可以防止跨站请求伪造攻击,但会给爬虫造成一定的困扰。本文将介绍在使用 Python3 爬虫时,处理 CSRF-Token 机制需要注意的问题及示例。
1 CSRF-Token 机制的原理
在 Web 开发中,每次发送请求时,服务器都会生成一个 CSRF-Token。当用户访问 Web 页面时,该 CSRF-Token 将被嵌入到 Web 表单、请求 URL 或 请求头 中。当用户提交表单或者发送请求时,该 CSRF-Token 将会被服务器验证,以防止跨站请求伪造攻击。
2 爬虫处理 CSRF-Token 机制的问题
由于爬虫不同于浏览器,它无法直接接收服务器生成的 CSRF-Token。因此,在使用爬虫时,我们需要解决如下问题:
- CSRF-Token 在哪生成?
- 如何将 CSRF-Token 嵌入到请求中?
3 CSRF-Token 可能存在的位置
在使用 Python3 爬虫时,针对不同类型的 CSRF-Token 有不同的获取方法。一般来说,CSRF-Token 可能位于 Web 表单、响应头或响应体中。
如果你认为 CSRF-Token 位于请求 URL 或 请求头 中,你需要找到生成 CSRF-Token 的具体请求报文或者网页元素,而不是从这个请求 URL 中直接分离 CSRF-Token。因为 CSRF-Token 会动态更新。具体来说,我们需要先分析网页或者应用程序,找到生成 CSRF-Token 的具体请求报文或者网页元素,然后从中获取 CSRF-Token。
下面,我们将分别介绍这三种情况的获取方法。
3.1 CSRF-Token 位于 Web 表单时
如果 CSRF-Token 位于 Web 表单中,我们可以使用 Beautiful Soup 库或者正则表达式来查找表单元素,然后获取 CSRF-Token。具体代码如下所示:
3.1.1 使用 Beautiful Soup 库
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
csrf_token = soup.find('input', {'name': 'csrf_token'}).get('value')
在上面的代码中,我们使用 requests 库来发送 GET 请求,并使用 Beautiful Soup 库来查找 CSRF-Token。
其中 Beautiful Soup 库需要使用pip3安装:
pip3 install BeautifulSoup4
3.1.2 使用正则表达式
import re
import requests
url = 'http://example.com'
response = requests.get(url)
csrf_token = re.findall(r'<input.*?name="csrf_token".*?value="(.*?)".*?>', response.text)[0]
在上面的代码中,我们使用 requests 库来发送 GET 请求,并使用正则表达式来匹配 CSRF-Token。
3.2 CSRF-Token 位于 响应体 时
我们需要首先通过分析 HTML 页面或者 JavaScript 代码,找到生成 CSRF-Token 的具体请求报文。比如,假设生成 CSRF-Token 的请求报文为:
POST /api/csrf_token HTTP/1.1
Host: example.com
Content-Type: application/json
Authorization: Bearer 1234567890
{"user_id": "1234567890"}
我们可以使用 requests 库来发送该请求报文,并从响应体中获取 CSRF-Token。具体代码如下所示:
import requests
url = 'http://example.com/api/csrf_token'
headers = {
'Authorization': 'Bearer 1234567890',
'Content-Type': 'application/json'
}
data = {
'user_id': '1234567890'
}
response = requests.post(url, headers=headers, json=data)
csrf_token = response.json().get('csrf_token')
在上面的代码中,我们使用 requests 库来发送 POST 请求,并使用 response.json() 来解析响应的 JSON 数据,从而获取 CSRF-Token。
需要注意的是,由于 CSRF-Token 会动态更新,因此我们需要在每次请求时重新获取 CSRF-Token。
另外需要注意的是,有些网站在后台生成 CSRF-Token 时可能会根据不同的请求参数生成不同的 Token,这意味着您需要在发送完整的请求(包括所有参数)之后才能获取到完整的 CSRF-Token。如果在获取 CSRF-Token 时发现它不正确或已过期,您可以尝试重新请求页面并获取新的 CSRF-Token。
3.3 CSRF-Token 位于 响应头 时
CSRF-Token 除了可以存在于响应体(Response Body)之外,还可能被隐藏在请求的响应头(Response Header)中。因此,在获取 CSRF-Token 时,您还应该查看完整的响应头,以查看是否有其他的 CSRF-Token。具体代码如下所示:
import requests
url = 'http://example.com/api/csrf_token'
headers = {
'Authorization': 'Bearer 1234567890',
'Content-Type': 'application/json'
}
data = {
'user_id': '1234567890'
}
response = requests.post(url, headers=headers, json=data)
csrf_token = dict(response.headers)['Csrf-Token']
以上就是针对 CSRF-Token 存在的三个位置获取 CSRF-Token 的 两种方法。在实际爬虫过程中,我们需要根据 CSRF-Token 的具体位置来选择相应的方法来获取 CSRF-Token。
3.4 注意事项
Request 请求的构造过程往往只有以下两步:
- 首先,去网站上找一下对应的请求链接。
- 使用 requests.get或requests.post 发起请求就行。
然而,由于 CSRF-Token 往往用于判断同一个会话的合法性,因此有这种机制的时候,需要保证获取 CSRF-Token 的请求和下一个请求处于同一个会话中(会话:Session),所以需要额外使用 requests.Session,然后将 requests.get 或 requests.post 直接替换成 Session.get 或 Session.post。
下面是一个简单的示例:
import requests
# 创建一个 Session 对象
session = requests.Session()
# 先请求登录页面获取 csrf_token
login_url = 'http://example.com/login'
login_page = session.get(login_url).text
csrf_token = re.findall('csrf_token=(.*?)&', login_page)[0]
# 使用获取到的 csrf_token 登录
data = {
'username': 'admin',
'password': '123456',
'csrf_token': csrf_token
}
login_result = session.post(login_url, data=data)
# 在同一个 Session 下进行其他操作
data = {
'param1': 'value1',
'param2': 'value2',
'csrf_token': csrf_token
}
result = session.post('http://example.com/other_operation', data=data)
在上面的代码中,我们首先使用 session.get 获取登录页面,然后使用正则表达式获取其中的 csrf_token,接着使用 session.post 发起登录请求,并在同一个 session 对象下进行其他操作,确保处于同一个会话中,从而绕过 CSRF-Token 的检查。
4 将 CSRF-Token 嵌入到请求中
获取 CSRF-Token 后,我们需要将它嵌入到请求中,以便服务器可以验证请求的合法性。在使用 Python3 爬虫时,需要根据具体的网址判断 CSRF-Token 的嵌入位置,嵌入位置一般在请求头或请求参数中。下面我们将介绍这两种嵌入位置应该如何嵌入。
4.1 CSRF-Token 嵌入请求头
在请求头中嵌入 CSRF-Token 的方法和普通的请求头差不多,只需要在请求头中加入 X-CSRF-Token 或者 X-XSRF-Token 等字段(根据具体网址判断字段名称),并将获取到的 CSRF-Token 作为该字段的值即可。示例代码如下:
import requests
url = 'http://example.com/submit_form'
csrf_token = '1234567890abcdef'
headers = {
'X-CSRF-Token': csrf_token,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
data = {
'param1': 'value1',
'param2': 'value2'
}
response = requests.post(url, headers=headers, data=data)
4.2 CSRF-Token 嵌入请求参数
在请求参数中嵌入 CSRF-Token 的方法也很简单,只需要在请求参数中加入名为 csrf_token 的字段,并将获取到的 CSRF-Token 作为该字段的值即可。示例代码如下:
import requests
url = 'http://example.com/submit_form'
csrf_token = '1234567890abcdef'
params = {
'param1': 'value1',
'param2': 'value2',
'csrf_token': csrf_token
}
response = requests.get(url, params=params)
以上代码中,如果是post请求,则需要使用requests.post(url, headers=headers, data=data),将 CSRF-Token 嵌入到 data 字段。
需要注意的是,不同的网站可能采用不同的嵌入位置,甚至可能采用多种嵌入方式,需要具体情况具体分析。
5 示例
下面,我们将使用 requests 库来实现一个简单的爬虫,用于获取西北工业大学的招生计划。
首先,我们需要获取西北工业大学网站的 CSRF-Token。具体代码如下所示:
import requests
import json
headers = {} # 请自行去网站上复制补全
get_token_url = "https://zsb.nwpu.edu.cn/f/ajax_get_csrfToken"
Session = requests.Session()
def get_csrf_token():
global data
update_ts()
response = Session.post(get_token_url, headers=headers, data=data)
csrf_token = json.loads(response.text)['data']
return csrf_token
在上面的代码中,我们使用 requests 库来发送 GET 请求,并使用 Beautiful Soup 库来查找 CSRF-Token。
接下来,我们需要将 CSRF-Token 添加到请求头中,并发送请求。具体代码如下所示:
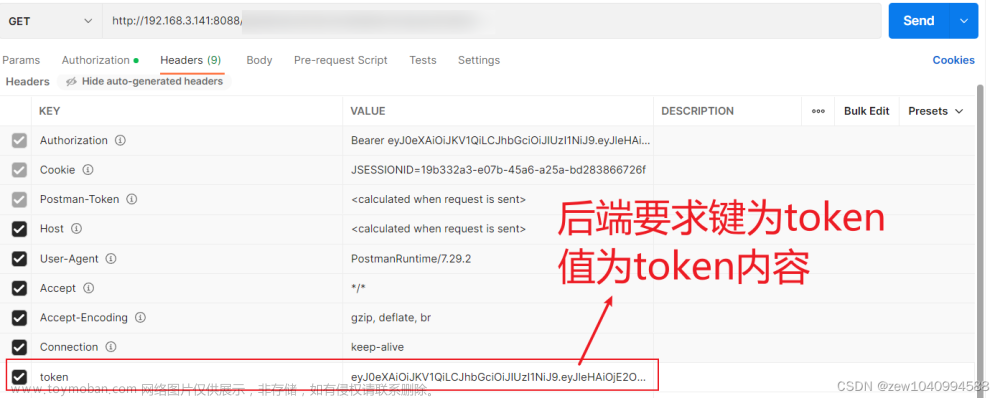
headers["Csrf-Token"] = get_csrf_token()
get_zsjh_url = "https://zsb.nwpu.edu.cn/f/ajax_zsjh"
response = Session.post(get_zsjh_url, headers=headers, data=data)
print(response.text)
在上面的代码中,我们将 CSRF-Token 添加到请求头中,并使用 requests 库发送 POST 请求。由于西北工业大学的招生计划是动态生成的,因此我们需要使用 POST 请求来获取数据。
运行上面的代码后,我们将会得到西北工业大学的招生计划。
需要注意的是,该会话接下来的 CSRF-Token 在这个response 的响应头。因此如果需要继续请求,需要使用这个response的headers去更新 CSRF-Token,代码如下所示:
# update Csrf-Token
headers["Csrf-Token"] = dict(response.headers)['Csrf-Token']
6 总结
在使用 Python3 爬虫时,我们需要了解 CSRF-Token 机制,并正确地处理它,以便服务器可以验证请求的合法性。文章来源:https://www.toymoban.com/news/detail-765961.html
具体来说,我们需要通过发送 GET 请求来获取 CSRF-Token,然后将 CSRF-Token 嵌入到请求中,以便服务器可以验证请求的合法性。在 Python3 中,我们可以使用 requests 库和 Beautiful Soup 库来实现这一过程。文章来源地址https://www.toymoban.com/news/detail-765961.html
到了这里,关于【笔记】Python3|爬虫请求 CSRF-Token 时如何获取Token、Token过期、处理 CSRF-Token 需要注意的问题及示例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!