前言
这是关于一篇异构联邦学习的综述,希望能从这篇文章对联邦学习有一个大致的了解。作者从一开始就呈现了文章总体的思维导图,非常具有指引效果。
这是论文地址:
Heterogeneous Federated Learning: State-of-the-art and Research Challenges
Background
什么是联邦学习
通俗的来说就是:
允许多个设备或数据源在不共享原始数据的情况下,共同训练模型以提高预测性能。
主要目的:
保护隐私。
联邦学习:机器学习的分布式计算方法,旨在让多个参与方共同训练模型,而无需将其原始数据集集中存储在一个地方。这种方法允许在保护数据隐私的前提下,进行模型的训练和更新。
联邦学习的诞生背景:传统的机器学习方法通常涉及将所有数据集中到一个中央服务器或者云端进行训练,但这可能会引发数据隐私和安全问题。联邦学习通过在本地设备(例如移动设备、传感器等)上进行模型训练,只共享模型参数的聚合信息,而不共享原始数据,从而解决了这些隐私问题。
联邦学习的工作方式大致如下:
- 初始化阶段: 在联邦学习开始时,中央服务器或者云端会初始化一个全局模型。
- 本地训练: 参与方(本地设备)使用自己的本地数据集对全局模型进行训练。这个训练过程只在本地设备上进行,不会共享原始数据。
- 模型聚合: 参与方将训练得到的模型参数更新发送回中央服务器,中央服务器对这些参数进行聚合,得到一个新的全局模型。
- 迭代更新: 重复进行本地训练和模型聚合的过程,直到全局模型收敛到一个满意的状态。
所以我们可以看到,联邦学习最主要的就是模型整合。
联邦学习的优势在于:
- 数据隐私保护: 原始数据保留在本地,不需要共享,因此可以更好地保护数据隐私。
- 降低数据传输需求: 仅传输模型参数更新,而不是原始数据,从而减少了数据传输的需求。
- 适用于分布式数据: 适用于数据分布在不同地点或设备上的情况,如移动设备上的个人数据。
tip:边缘计算和联邦学习有什么关系?
- 边缘计算(Edge Computing)是一种分布式计算范式,它将计算资源和数据处理功能放置在物理世界中数据生成的地方,即靠近数据源的地方,而不是集中在远程的云数据中心。
- 联邦学习可以视为边缘计算中的一种重要技术,它允许在边缘节点上进行分布式计算和机器学习,以满足隐私、带宽和实时性等方面的要求。
联邦学习和边缘计算的互补性:
- 数据分布在边缘节点上:在边缘计算环境中,数据通常分布在边缘设备、传感器或物联网设备上,而不是集中存储在云中。联邦学习允许在这些分布式数据源上训练模型,而无需将数据传输到中心位置,从而提高了数据的隐私性和降低了通信成本。
- 数据分布在边缘节点上:在边缘计算环境中,数据通常分布在边缘设备、传感器或物联网设备上,而不是集中存储在云中。联邦学习允许在这些分布式数据源上训练模型,而无需将数据传输到中心位置,从而提高了数据的隐私性和降低了通信成本。
- 降低带宽需求:边缘设备通常具有有限的带宽和计算资源,而联邦学习的分散训练方法可以在这些设备上执行局部模型更新,然后将模型参数聚合在中心服务器上,从而减少了对大量数据传输的依赖。
什么是异构联邦学习
联邦学习的核心理念——将模型训练分布在多个参与方之间,保护数据隐私的同时提高模型的整体性能。这意味着参与方之间可能存在一些差异(数据or计算环境),但这些差异通常指的是异构性。
通俗易懂的讲:
在模型整合的过程中,参与方带来的差异——>研究异构联防学习
异构联邦学习的主要特点包括:
- 异构数据: 参与方的数据可能来自不同的领域、行业或地区,具有不同的特征分布和属性。这可能导致模型在不同参与方之间表现不一致。
- 异构计算能力(机构设备): 不同参与方的计算能力可能不同,有些设备可能更强大,可以进行更多的计算和模型更新,而其他设备可能计算资源有限。
- 异构通信环境: 不同参与方之间的通信环境也可能不同,有些设备可能具有较快的网络连接,而其他设备可能连接较慢。
- 异构模型: 参与方所希望用到的模型更加的本地化。所以不同参与方用到的模型有所差异
为了应对这些异构性,异构联邦学习采取了一些策略,如:
- 模型适应性调整: 在模型训练过程中,根据不同参与方的特点,对模型进行适应性调整,以提高在异构数据上的性能表现。
- 计算资源分配: 根据不同设备的计算能力,动态调整模型训练的频率或资源分配,以平衡训练的负载。
- 通信优化: 考虑不同通信环境,采用不同的通信策略,以减少在通信过程中的开销。
Abstract
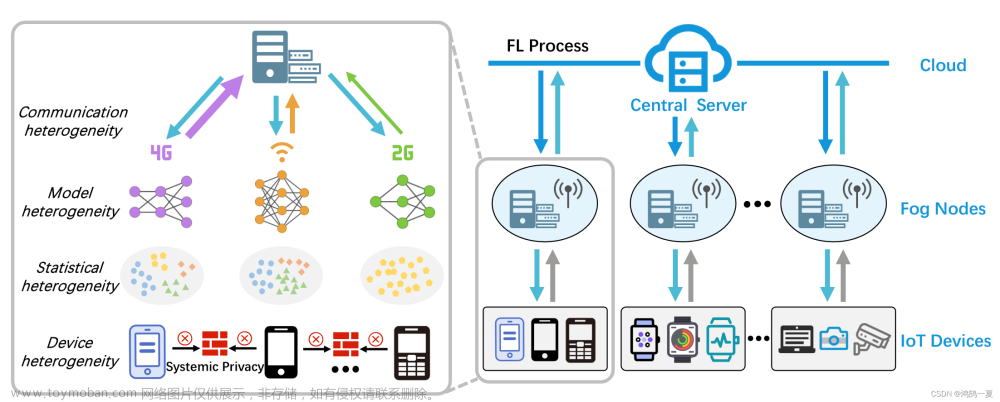
- 异构性问题,并将其分为四类:统计异构性、模型异构性、通信异构性和设备异构性。
- 关于异构联邦学习的论文进行了综述,并对现有的技术进行了合理和全面的分类。
- 该分类法将最先进的方法分为三个不同的层次:数据层、模型层和服务器层。
Introduction
- 边缘设备—(隐私数据)—>联邦学习:数据非中心化&协同训练以避免隐私泄露
- 联邦学习依赖于强假设,但现实生活中数据分布、模型结构、通信网络和系统边缘设备有很大差异,所以联邦学习应该还要更结合差异性,所以异构联邦学习分为这四大类:统计异构、模型异构、通信异构和设备异构。
Survey

总体架构图如上:
- 从五个不同的方面系统地总结了研究中存在的挑战。
- 在新的分类学背景下,回顾了当前最先进的方法,并对它们的优势和局限性进行了深入讨论。
- 对未解决的问题和未来发展的开放性问题进行了展望分析。
Research Challenges (研究挑战)
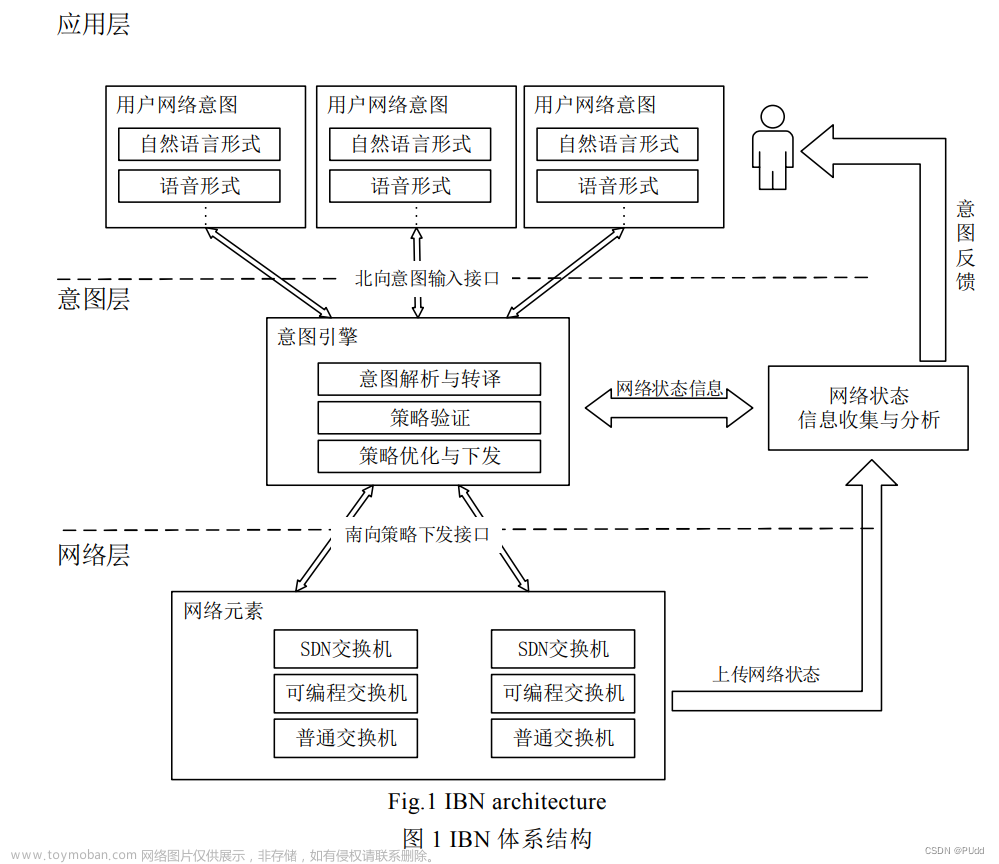
下图为多层联邦学习的基本架构:
在cloud-fog-IoT计算环境中(如上图),根据参与者的角色和能力,将参与者分为不同的层次,包括云层(cloud Server)、雾层(Fog Nodes)和物联网层(IoT Devices)。
- 云层是执行全局模型聚合和更新的中心服务器。它具有较高的计算和存储能力,但与边缘节点的通信成本也较高。
- 雾层是由多个边缘服务器(例如,基站)组成的中间层,可以与云层和物联网层进行通信。
- 物联网层由边缘设备(例如,智能手机、传感器等)组成,进行局部模型训练,并与雾层通信。并且允许物联网设备以点对点的方式与其邻居进行通信。
a formulaic definition of federated learning:
- K名客户端:{ C 1 C_1 C1, C 2 C_2 C2, …, C k C_k Ck }
- 每名客户端有一个私有数据集: D k = { ( x i k , y i k ) } i = 1 N k D_k=\left.\{(x_i^k,y_i^k)\}_{i=1}^{N_k}\right. Dk={(xik,yik)}i=1Nk
- ∣ x k ∣ = N k |x^k|=N_k ∣xk∣=Nk and N = ∑ k = 1 K N k N=\sum_{k=1}^KN_k N=∑k=1KNk
- 每个客户端都有一个本地模型or称之为初始模型: f ( θ k ) f(\theta_k) f(θk)
- 私有数据 x k x^k xk在本地模型 θ k \theta_k θk上得到的output: f ( x k , θ k ) f(x^k,\theta_k) f(xk,θk)
对于传统的集中式机器学习框架来说:
- 数据集是直接整合每个客户端的私有数据集 D c e n t r a l = D 1 ∪ D 2 ∪ . . . ∪ D K \begin{aligned}D_{\boldsymbol{central}}&=D_1\cup D_2\cup...\cup D_K\end{aligned} Dcentral=D1∪D2∪...∪DK
- 训练是直接在中央模型上训练 θ c e n t r a l \theta_{central} θcentral
但是弊端就是无法保护用户的数据隐私性。于是我们才考虑这种联邦学习。
联邦学习就是考虑不上传私有数据的情况下,协同的训练模型。
训练基本过程:
-
模型初始化:服务器选择符合条件的客户端{ C 1 C_1 C1, C 2 C_2 C2, …, C k C_k Ck }作为参与者,并在第一轮初始化全局模型 θ g l o b a l 1 \theta^1_{global} θglobal1。
-
模型广播:服务器将当前全局模型 θ g l o b a l t − 1 \theta^{t-1}_{global} θglobalt−1发送给所有参与客户端,作为本地模型 { θ 1 t − 1 , θ 2 t − 1 , . . . , θ K t − 1 } \{\theta_1^{\boldsymbol{t}-1},\theta_2^{\boldsymbol{t}-1},...,\theta_K^{\boldsymbol{t}-1}\} {θ1t−1,θ2t−1,...,θKt−1}的初始化。
-
本地更新。每个参与的客户端 C k C_k Ck利用私有数据集 D k D_k Dk进行如下的局部模型更新:
θ k t ← θ k t − 1 − α ∇ θ L k ( f ( x k , θ k t − 1 ) , y k ) , \theta_k^t\leftarrow\theta_k^{t-1}-\alpha\nabla_\theta\mathcal{L}_k(f(x^k,\theta_k^{t-1}),y^k), θkt←θkt−1−α∇θLk(f(xk,θkt−1),yk),
其中,α表示学习率,Lk ( · )表示每个客户端k的计算损失。 -
模型聚合。服务端计算更新后,客户端模型参数的集合 ∑ k = 1 K N k N θ k t \sum_{k=1}^K\frac{N_k}N\theta_k^t ∑k=1KNNkθkt。
-
全局更新。服务器根据聚合结果更新下一个epoch的全局模型,具体如下: θ g l o b a l t + 1 ← ∑ k = 1 K N k N θ k t . \theta_{global}^{t+1}\leftarrow\sum_{k=1}^K\frac{N_k}N\theta_k^t. θglobalt+1←k=1∑KNNkθkt.
-
模型部署。服务器将全局模型分发给参与的客户端。
Statistical Heterogeneity (数据异质性)
现象:Non-IID 数据分布是不一致的,并且不服从相同的采样。
从分布角度(四种不同的数据倾斜模式):标签偏斜、特征偏斜、质量偏斜和数量偏斜。
标签偏斜(Label Skew):
标签偏斜指的是目标变量或标签的分布不平衡 。同时,这也可以被分为两类:label distribution skew and label preference skew。
- Label Distribution Skew(标签分布偏斜):
含义:标签分布偏斜是指在一个数据集中,不同类别的标签出现的频率不平衡或不均匀。换句话说,某些类别的样本数量可能远远多于其他类别,而某些类别可能只有很少的样本。虽然即使特征分布是共享的(对于每个标签,数据样本的特征都是相似的,不管它们属于哪个客户端) P i ( x ∣ y ) = P j ( x ∣ y ) P_i(x|y)=P_j(x|y) Pi(x∣y)=Pj(x∣y),但是标签不同 P i ( y ) ≠ P j ( y ) P_i(y)\neq P_j(y) Pi(y)=Pj(y)
示例:在一个垃圾邮件过滤器的数据集中,垃圾邮件的样本数量可能远远多于正常邮件的样本数量,导致标签分布偏斜。或者figure中比如Client1和Client2的标签分布不同。 - Label Preference Skew(标签偏好偏斜):
含义:模型对于不同类别的标签存在偏好或倾向,即模型更容易将样本分配到某些类别,而对其他类别表现较差。这种偏好可以是由于数据不均衡引起的,但它更关注模型的行为而不仅仅是数据分布。
示例:比如在figure中,不同client对同一张图片赋予的标签情感不同。
特征偏斜(Feature Skew):
数据集中的某些特征在不同类别或样本之间的分布不均匀。它也可以被分为两类:Feature distribution skew和Feature condition skew。
-
Feature Distribution Skew(特征分布偏斜):
含义:标签分布一致 P i ( y ∣ x ) = P j ( y ∣ x ) P_i(y|x)~=~P_j(y|x) Pi(y∣x) = Pj(y∣x),特征不同 P i ( x ) ≠ P j ( x ) P_i(x)\neq P_j(x) Pi(x)=Pj(x) 。特征分布偏斜指的是在数据集中,某些特征的取值分布不均匀或不平衡。
示例:手写数字识别中,不同的用户可能会用不同的风格、笔画粗细等书写相同的数字。导致特征分布不同,但是标签结果分布一致。 -
Feature Condition Skew(特征条件偏斜):
含义:特征条件偏斜是指,即使 P i ( y ) = P j ( y ) P_i(y)=P_j(y) Pi(y)=Pj(y),不同客户的特征分布也可能不同,即 P i ( x ∣ y ) ≠ P j ( x ∣ y ) P_i(x|y)\neq P_j(x|y) Pi(x∣y)=Pj(x∣y)。
例如,figure上,日本地区包含大量的柴犬样本,而西伯利亚地区包含大量的哈士奇样本,但它们的标签都是狗。
区别:特征分布偏斜关注单个特征的取值分布,而特征条件偏斜关注特征之间的条件关系或相关性。
质量偏斜(Quality Skew):
数据集中的样本质量不均衡。
有些样本可能包含错误或噪声,而其他样本则质量较高,数据中的质量不均匀分布。在模型训练中,低质量的样本可能会引入噪声,影响模型的性能。
质量偏差可分为label noise skew(标签噪声偏差) and sample noise skew(样本噪声偏差)
数量偏斜(Quantity Skew):
这意味着在客户端之间,本地数据的数量可能是极不平衡的,即长尾分布数据。多个客户端可能存在数据稀缺的问题。数量偏斜可能导致模型在训练和预测中对数量较多的类别表现较好,而对数量较少的类别表现较差。
Model Heterogeneity (模型异质性)
联邦学习中:假设每个参与的客户端都需要使用具有相同架构的本地模型,更容易聚合。
但在实际中,每个客户端可能以独特的方式设计自己的局部模型架构,且并不愿共享模型细节。
-
Partial Heterogeneity(部分异质性)
有些客户端使用相同的模型结构,有些则不同。通过聚类算法,参与的客户可以被分成许多簇,即每个簇内的结构是相同的。然后用模型参数的加权平均,来实现簇内模型的聚合。 -
Complete Heterogeneity (完全异质性)
所有参与者模型的网络结构是完全不同的。aim:需要为每个客户端学习一个独特的模型,该模型可以更好地处理不同的数据分布,但最终可能导致高学习成本和低通信效率。
Comuunication Heterogeneity (通信异质性)
原因:部署在不同的网络环境中,具有不同的网络连接设置( 3G、4G、5G、Wi - Fi)。延迟不同。
问题:增加了通信成本和通信复杂度。不同的设备可能需要不同的数据量或时间与服务器进行连接和通信。
解决:当有足够数量的客户端将反馈结果发送到服务器端后,可能会丢弃掉具有显著时间差的杂耍器和离线设备。
Device Heterogeneity (设备异质性)
不同设备所具有的不同设备硬件能力( CPU、内存、电池寿命)的差异可能导致不同的存储和计算能力。
State-Of-The-Art(当先现状)
作责将异构联邦学习方法分为数据级、模型级和服务器级3个部分进行综述。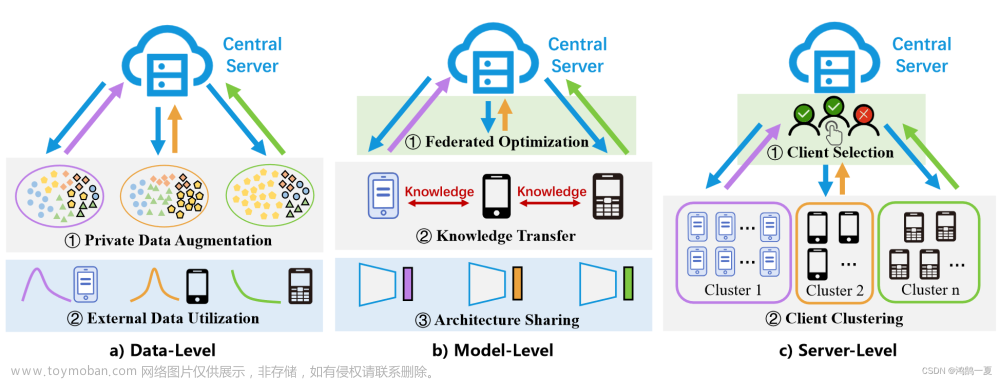
数据级(Data-level)方法:
含义:在客户端之间对数据进行操作,以减少局部数据的统计异质性或提高数据隐私。这包括诸如数据增强和匿名化技术等操作。
解释:用于处理客户端数据差异。数据增强可以通过合成额外的数据来平衡不同客户端的数据分布,而匿名化技术可用于保护客户端数据的隐私。
模型级(Model-level)方法:
含义:在模型层面设计的操作,例如共享部分模型结构和模型优化。
解释:由于不同客户端可能使用不同的模型架构或训练算法。模型级方法将共享或融合来自不同模型的信息,以构建具有全局性能的模型。
服务器级(Server-level)方法:
含义:服务器级方法需要服务器的参与,例如参与客户端选择或客户端聚类。
解释:由于服务器可能具有不同的计算或存储能力,或者需要进行客户端的选择或分组。服务器级方法将有效地协调和管理不同服务器的参与,以确保任务的顺利执行。
Data-Level
数据级方法:在数据层面进行的操作,包括1.私有数据处理和 2.外部数据利用。
- 隐私数据处理:指客户端对私有数据进行内部处理,这些方法包括数据准备(数据收集、过滤、清洗、增广等操作,可以直接缓解统计异质性)和数据隐私保护(确保原始数据信息不被泄露)。
- 外部数据利用:通过引入额外数据进行模型知识蒸馏或对模型更新施加约束。知识蒸馏通常用于处理由模型异构性引起的通信困难,可以在一定程度上缓解数据异构性和通信异构性。
Private Data Processing(隐私数据处理)
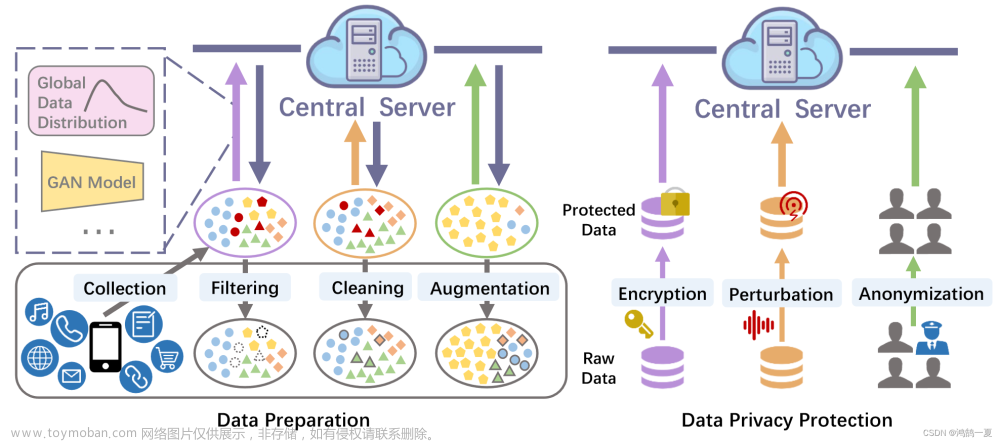
数据准备:包括数据收集、过滤、清洗、增强等(见上图左图)。
- 数据收集:数据收集的数量、质量和多样性重要,so,局部数据收集是联邦学习中需要优化的重要环节。[Li :货币预算约束下选择总质量最高的最优样本组合。]
- 数据过滤:过滤不相关数据。【Xu:用于数据选择的协同数据过滤方法,Safe。可以检测并过滤掉带毒数据。具体做法:Safe首先对局部数据进行聚类,然后测量每个样本与其聚类中心之间的距离,最后将距离聚类中心较远的样本舍弃为带毒数据。】
- 数据清洗:填补缺失值、解决冲突和标准化数据。
- 数据增强:从有限的原始数据中生成更多数据来人为扩充训练数据集。有翻转、旋转、缩放、裁剪、平移、引入高斯噪声。或者使用GAN合成额外的数据。
Non - IID环境中(客户端数据分布不均匀)
- Yoon构建了一个平均增强联邦学习( Mean Augmented Federation Learning,MAFL )框架,客户端在保持隐私需求的同时交换平均局部数据以获取全局信息。并且在MAFL框架下设计了一个数据增强算法FedMix。
- Astraea创建了基于局部数据分布的Kullback - Leibler ( KL )散度重新安排客户端训练的中介器。
- 联邦增广:使用GAN。每个客户端可以识别数据样本中缺乏的目标标签。随后,客户端将目标标签的部分数据样本上传至服务器,服务器对上传的数据样本进行过采样以训练一个cGAN。
Data Privacy Protection(数据隐私保护)
本地层面的数据隐私保护方法一般分为三类:namely data encryption数据加密, perturbation扰动 and anonymization匿名化。
- 数据加密
同态加密:它允许在不解密的情况下使用加密数据进行计算。[Asad :将同态加密应用到联邦学习中,使得客户端可以用私钥加密其本地模型,然后发送给服务器。] - 扰动
DP:通过对本地更新进行裁剪和添加噪声来保护客户端的私有信息。[Hu:用于个性化局部DP的联邦学习方法PLDP - PFL。它允许每个客户端根据其隐私数据的敏感程度。] - 匿名化
移除或替换数据中可识别的敏感信息。[Choudhury根据本地数据集的特点,让客户端生成自己的匿名数据映射]
External Data Utilization(外部数据利用)

Knowledge Distillation from External Data(外部数据知识蒸馏)
利用公共数据进行知识蒸馏。
具体:使用在外部数据集上训练的全局teacher模型来帮助客户端为本地数据生成软标签。然后,客户端利用这些软标签作为局部更新的额外监督,从而提高模型的泛化能力,缓解数据异质性的影响。
[利用知识蒸馏来减轻统计异质性——FedFTG训练一个条件生成器来拟合局部模型的输入空间,然后用于生成伪数据。将这些伪数据输入到全局模型和局部模型中进行知识蒸馏,通过缩小它们输出预测之间的库尔贝克-莱布勒散度,将局部模型的知识转移到全局模型中。]
Unsupervised Representation Learning(无监督表征学习)
由于来自客户端的私有数据通常难以标注,因此讨论联邦无监督表示学习,在保持私有数据去中心化和无标签的情况下学习一个通用的表示模型。
FedCA是一种基于对比损失的联合无监督表示学习算法,解决客户端之间数据分布不一致和表示不对齐的问题。客户端通过两个对比学习模块(对齐模块和字典模块)生成局部字典,然后服务器将训练好的局部模型进行聚合,并将局部字典集成到全局字典中。
Model-Level
为每个客户端学习一个适应其私有数据分布的局部模型。且分为三个部分:federated optimization联邦优化、knowledge transfer across models跨模型的知识转移、architecture sharing架构共享。
- 联邦优化:在学习全局信息的同时,使模型适应局部分布。解决统计异质性下的局部模型个性化。
- 跨模型的知识转移:以模型不可知的方式实现多方协作。解决模型和通信的异构性。
- 架构共享:共享部分模型结构实现个性化联邦学习。同时解决统计、模型和设备的异构性。
federated optimization

- 正则化。通过在损失函数中添加惩罚项来帮助防止过拟合的技术。[Fed Prox在Fed Avg 的基础上增加了近端项。服务器将前一个历元t的全局模型分发给客户端]
- 元学习。以往的经验用于指导新任务的学习,允许机器针对不同的任务自行学习一个模型。[Jiang等人认为元学习中的MAML设置与异构联邦学习的个性化目标一致。MAML算法分为元训练和元测试两个阶段,分别对应联邦学习中的全局模型训练和局部模型个性化。]
MAML:首先训练初始化的模型。在对新任务进行训练时,只需要少量的数据就可以在初始模型的基础上进行微调,从而获得令人满意的学习性能。
- 多任务学习。在单个任务上学习的模型可以通过使用相关任务的共享表示或模型来帮助学习其他任务。 如果将每个客户端的局部模型学习视为一个单独的任务,则可以实现多任务学习的思想来解决联邦学习问题。所有参与的客户端协同训练本地模型。
knowledge transfer across models

- 跨模型的知识蒸馏。目标是提炼客户上的知识分布,然后以模型不可知的方式传递学习到的知识。
- 迁移学习。目标是将在源域上学习到的知识应用到不同但相关的目标域上。那么,联邦迁移学习旨在将客户端学习到的知识迁移到公共服务器上进行聚合 or 将全局迁移到客户端上进行个性化学习。
architecture sharing

- Backbone Sharing。客户可能共享Backbone,但他们在个性化需求的神经网络模型中设计了个性化层。在聚合阶段,客户端只需要将Backbone网上传到服务器端,从而在一定程度上降低了通信开销。
[Fed Per将基础层和个性化层结合用于深度前馈神经网络的联邦训练。步骤:FedPer首先使用基于FedAvg的方法在公共数据集上对基础层进行全局训练。随后,每个客户端使用私有数据集使用SGD风格的算法更新个性化图层。] - Classifier Sharing:客户端通过自己的主干进行特征提取,并共享一个公共分类器进行分类。
- Other Part Sharing。根据局部条件自适应地共享局部模型参数的子集。
Server-Level

-
Client Selection
原因:传统的联邦学习在Non - IID数据集上的性能不如其在IID数据集上的性能,在Non - IID数据集上的收敛速度也远慢于其在IID数据集上的收敛速度。为了减轻Non - IID数据引入的偏差,所以要进行Client Selection。
方法:将联邦学习的设备选择问题定义为深度强化学习问题,旨在训练智能体学习合适的选择策略。 -
Client Clustering
通过考虑数据分布的相似性、局部模型和不同客户的参数更新来执行所有客户的个性化聚类。[Briggs为了减少达到收敛所需的通信轮数,同时提高测试精度引入层次聚类步骤,通过客户端更新对全局联合模型的相似性来分离客户端集群。] -
Decentralized(去中心化) Communication
原因:一般的联邦学习算法依赖于一个中心服务器,中心的失效将破坏整个联邦学习过程。因此,一些算法采用去中心化通信,在不依赖中心服务器的情况下,在各种设备之间进行点对点通信。[Lalitha等提出了一个完全分布式的联邦学习算法,其中客户端只能与他们的一跳邻居进行通信,而不依赖于一个集中式的服务器。]
Future Direction(未来方向)
Improving Communication Efficiency
- Kone 的两种方法:从有限空间中学习一个更新;更新模型并将压缩后的模型发送给服务器。
- 通信缓和的联邦学习:衡量局部更新与全局更新是否一致来避免不相关的更新向服务器传输。
- 联邦最大均值差异:引入最大均值来减少通信轮数。
- 去中心化的稀疏训练技术,使得每个局部模型使用个性化的稀疏掩码来选择自己的活跃参数,并且在局部训练和点对点通信过程中保持固定数量的活跃参数。这样,每个局部模型只需要传输一次其活动参数的索引。
bad:
- 大量边缘节点的存在会增加计算成本以及所需的计算能力和存储容量。
- 网络带宽的差异会导致本地模型从客户端发送到服务器的延迟甚至丢失。
- 私有数据集规模的差异也会导致模型更新的延迟。
Federated Fairness(公平性)
协作过程中参与客户端贡献的差异——公平性。系统中可能存在多个搭便车的参与者,所以贡献较多的客户应该从其他客户那里学习更多的知识,并通过协同训练获得更优秀的模型。
- FPFL将联邦学习中的公平性问题视为一个受公平性约束的优化问题,并通过改进差分乘法器MMDM来提高系统的公平性。
- q-FedAvg通过缩小客户端模型精度之间的差异来提高公平性。
- CFFL在联邦学习中根据每个客户端的贡献分配具有不同性能的模型。
Privacy Protection
隐私保护是联邦学习的首要原则。
- DP,它为局部更新添加噪声,并对局部更新的范数进行剪裁,以保留原始的隐私信息。
- DP-Fed Avg采用高斯机制在Fed Avg中加入用户级隐私保护,通过用户级数据进行大量更新。
- Cheng通过在局部更新中加入正则化和稀疏化过程来改进DP - FedAvg。
原始数据匿名化和特征模板保护。
- 原始数据匿名化是指在对原始生物特征数据进行预处理时,采用一种方法使得个人身份识别信息或其他敏感信息如性别、年龄、健康状况等无法从数据中提取出来。
- need:需要设计新颖的原始数据匿名化方案,既能有效保护原始数据的隐私,又能为联邦学习中的模型训练保留足够的个人身份信息。所以,需要权衡数据匿名化的隐私性和实用性。
特征模板保护
- 原始生物特征数据中提取特征模板后,采用某种方法使得原始生物特征数据或其他敏感信息无法从这些特征模板中重构。
- need:需要一种不可逆、可更新、可验证的特征模板保护方案,同时在联邦学习框架下保持被保护特征模板的可区分性。
Attack Robustness
两类主要的攻击:投毒攻击和推断攻击。
- 毒化攻击:试图阻止模型被学习,使模型的学习方向偏离原来的目标。这类攻击包括数据中毒和模型中毒。
1)数据投毒:通过标签翻转和后门插入等方法破坏训练数据的完整性,从而恶化模型性能。
2)模型中毒:无法直接对私有数据进行操作,但可以通过破坏客户端更新来改变模型的学习方向。
-推理攻击推断出用户隐私数据的相关信息,从而泄露用户隐私。
防御策略来增强系统的鲁棒性。
- Xie通过对模型进行裁剪和添加平滑噪声来提高对抗后门攻击的鲁棒性。
- Li在服务器端学习一个检测模型来识别和去除恶意的模型更新,从而在去除无关特征的同时保留有效的基本特征。
Uniform Benchmarks
联邦学习缺乏被广泛认可的基准数据集和面向异构场景的基准测试框架。文章来源:https://www.toymoban.com/news/detail-766331.html
- General Federated Learning Systems:FedML、FedScale、OARF、OARF、FedEval。
- Specific Federated Learning Systems.:
FedReIDBench:是一个用于实现联邦学习person ReID的新基准,它包括9个不同的数据集和2个联邦场景。
PFL-Bench :是一个个性化联邦学习的基准测试程序。十二种不同的数据集变体,包括图像、文本、图和推荐数据,具有统一的数据划分和现实的异构设置。
FedGraphNN:是基于图联邦学习的基准系统,包括来自7个不同领域的广泛数据集、流行的GNN模型和联邦学习算法。 - Datasets:LEAF [ 16 ]包含6类涵盖不同领域的联邦数据集,包括图像分类( FEMNIST ,合成数据集)、图像识别( Celeba )、情感分析等。并且提供了" IID “和” Non-IID "两种抽样方法。
conclusion
- 联邦学习中的异构性问题四类:统计异构性、模型异构性、通信异构性和设备异构性。
- 从三个不同的层次:数据层、模型层和服务器对异构联邦学习的论文进行了综述。
- 值得进一步探索的方向和未来发展的开放性问题进行了展望分析。
结尾
阅读了这一篇论文,明白了联邦学习的大致体系,但是对其中一些具体的解决方法还不是非常的深入了解。一些名词还较为陌生。
我发现要解决联邦学习的异构问题,不仅仅要从联邦学习入手,而且还要扩展到其他很多的知识,比如迁移学习,知识蒸馏,元学习,深度强化学习等。每一方面都可以很深入的探究。所以不仅要看联邦学习的知识架构,还要结合自己实验室主要的擅长方向,然后在那个方向挖掘核心问题,才能做出好的成果。文章来源地址https://www.toymoban.com/news/detail-766331.html
到了这里,关于【论文阅读】异构联邦学习综述:最新进展与研究挑战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!