集成SAM,可以通过文本提示做检测/分割等任务。

我们计划通过结合 Grounding DINO 和 Segment Anything 来创建一个非常有趣的演示,旨在通过文本输入检测和分割任何内容! 并且我们会在此基础上不断完善它,创造出更多有趣的demo。
我们非常愿意帮助大家分享和推广基于Segment-Anything的新项目,更多精彩的demo和作品请查看社区:亮点扩展项目。 您可以提交新问题(带有项目标签)或新拉取请求以添加新项目的链接。


该项目背后的核心思想是结合不同模型的优势,构建一个非常强大的管道来解决复杂问题。 值得一提的是,这是一个组合强专家模型的工作流程,其中所有部件都可以单独或组合使用,并且可以替换为任何相似但不同的模型(例如用 GLIP 或其他探测器替换 Grounding DINO / 替换 Stable- 使用 ControlNet 或 GLIGEN 进行扩散/与 ChatGPT 结合)。
一、Preliminary Works
在这里,我们提供了一些您在尝试演示之前可能需要了解的背景知识。
- Segment-Anything:
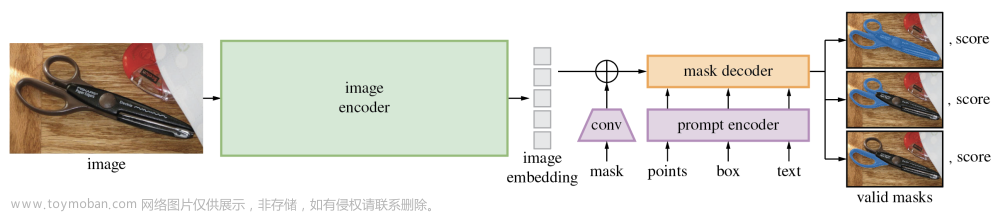
强大的基础模型旨在分割图像中的所有内容,这需要提示(如框/点/文本)来生成掩模
2. Grounding DINO:
强大的零样本检测器,能够生成带有自由格式文本的高质量框和标签。

3. OSX
一种强大而高效的单阶段运动捕捉方法,可从单目图像生成高质量的 3D 人体网格。 OSX还发布了大规模上半身数据集UBody,用于更准确地重建上半身场景。

4. Stable-Diffusion
超强大的开源潜在文本到图像扩散模型。

5. RAM
RAM is an image tagging model, which can recognize any common category with high accuracy.
- BLIP
A wonderful language-vision model for image understanding.
- Visual ChatGPT
A wonderful tool that connects ChatGPT and a series of Visual Foundation Models to enable sending and receiving images during chatting.
- Tag2Text
An efficient and controllable vision-language model which can simultaneously output superior image captioning and image tagging.
- VoxelNeXt
A clean, simple, and fully-sparse 3D object detector, which predicts objects directly upon sparse voxel features.
二、Highlighted Projects
在这里,我们提供了一些您可能会感兴趣的令人印象深刻的作品:
2.1 Semantic-SAM
通用图像分割模型,能够以任何所需的粒度分割和识别任何内容.
2.2 SEEM: Segment Everything Everywhere All at Once
强大的提示分割模型支持使用各种类型的提示(文本、点、涂鸦、引用图像等)以及提示的任意组合进行分割。
2.3 OpenSeeD
一个用于开放词汇分割和检测的简单框架,支持通过框输入生成掩模的交互式分割.
2.4 LLaVA
Visual instruction tuning with GPT-4.
三、Installation
该代码需要 python>=3.8,以及 pytorch>=1.7 和 torchvision>=0.8。 请按照此处的说明安装 PyTorch 和 TorchVision 依赖项。 强烈建议安装支持 CUDA 的 PyTorch 和 TorchVision。
3.1 Install with Docker
Open one terminal:
make build-image
make run
就是这样。
如果您想允许跨 docker 容器进行可视化,请打开另一个终端并输入:
xhost +
3.2 Install without Docker
如果您想为Grounded-SAM构建本地GPU环境,您应该手动设置环境变量,如下所示:
export AM_I_DOCKER=False
export BUILD_WITH_CUDA=True
export CUDA_HOME=/path/to/cuda-11.3/
安装Segment Anything:
python -m pip install -e segment_anything
安装 DINO 接地:
python -m pip install -e GroundingDINO
安装扩散器:
pip install --upgrade diffusers[torch]
Install osx:
git submodule update --init --recursive
cd grounded-sam-osx && bash install.sh
Install RAM & Tag2Text:
git submodule update --init --recursive
cd Tag2Text && pip install -r requirements.txt
以下可选依赖项对于掩模后处理、以 COCO 格式保存掩模、示例笔记本以及以 ONNX 格式导出模型是必需的。 运行示例笔记本还需要 jupyter。
pip install opencv-python pycocotools matplotlib onnxruntime onnx ipykernel
四、GroundingDINO: Detect Everything with Text Prompt
以下是运行 GroundingDINO 演示的分步教程:
4.1 Download the pretrained weights
cd Grounded-Segment-Anything
# download the pretrained groundingdino-swin-tiny model
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
4.2 Running the demo
python grounding_dino_demo.py
4.3 Running with Python
from groundingdino.util.inference import load_model, load_image, predict, annotate
import cv2
model = load_model("GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py", "./groundingdino_swint_ogc.pth")
IMAGE_PATH = "assets/demo1.jpg"
TEXT_PROMPT = "bear."
BOX_THRESHOLD = 0.35
TEXT_THRESHOLD = 0.25
image_source, image = load_image(IMAGE_PATH)
boxes, logits, phrases = predict(
model=model,
image=image,
caption=TEXT_PROMPT,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD
)
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
cv2.imwrite("annotated_image.jpg", annotated_frame)
如果您想使用 Grounding DINO 在一个句子中检测多个物体,我们建议用 分隔每个名称。 。 一个例子:猫。 狗 。 椅子 。
4.4 Check the annotated image
带注释的图像将保存为./annotated_image.jpg。文章来源:https://www.toymoban.com/news/detail-766490.html
 文章来源地址https://www.toymoban.com/news/detail-766490.html
文章来源地址https://www.toymoban.com/news/detail-766490.html
到了这里,关于【计算机视觉 | 目标检测 | 图像分割】Grounded Segment Anything:Grounding DINO + Segment Anything Model (SAM)介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












