1,演示视频地址
https://www.bilibili.com/video/BV1Hu4y1L7BH/
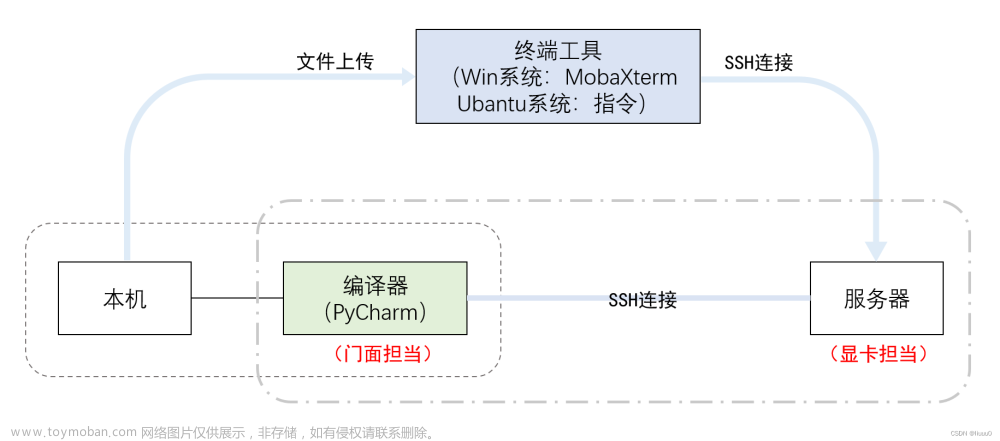
使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat-int4模型,用vllm优化,增加 --num-gpu 2,速度23 words/s
2,使用3090显卡 和使用A40 的方法一样
https://blog.csdn.net/freewebsys/article/details/134698597
安装软件: 先安装最新的torch版本
apt update && apt install -y git-lfs net-tools
#
git clone https://www.modelscope.cn/01ai/Yi-34B-Chat-4bits.git
# 1,安装 torch 模块,防止依赖多次下载
pip3 install torch==2.1.0
# 2,安装 vllm 模块:
pip3 install vllm
# 最后安装
pip3 install "fschat[model_worker,webui]" auto-gptq optimum
安装完成之后就可以使用fastchat启动了。
3,启动脚本增加 --num-gpus 2 即可使用,两个显卡
# run_all_yi.sh
# 清除全部 fastchat 服务
ps -ef | grep fastchat.serve | awk '{print$2}' | xargs kill -9
sleep 3
rm -f *.log
#IP_ADDR=`ifconfig -a | grep -oP '(?<=inet\s)\d+(\.\d+){3}' | head -n 1 `
# 首先启动 controller :
nohup python3 -m fastchat.serve.controller --host 0.0.0.0 --port 21001 > controller.log 2>&1 &
# 启动 openapi的 兼容服务 地址 8000
nohup python3 -m fastchat.serve.openai_api_server --controller-address http://127.0.0.1:21001 \
--host 0.0.0.0 --port 8000 > api_server.log 2>&1 &
# 启动 web ui
nohup python -m fastchat.serve.gradio_web_server --controller-url http://127.0.0.1:21001 \
--host 0.0.0.0 --port 6006 > web_server.log 2>&1 &
# 然后启动模型: 说明,必须是本地ip --load-8bit 本身已经是int4了
# nohup python3 -m fastchat.serve.model_worker --model-names yi-34b \
# --model-path ./Yi-34B-Chat-8bits --controller-address http://${IP_ADDR}:21001 \
# --worker-address http://${IP_ADDR}:8080 --host 0.0.0.0 --port 8080 > model_worker.log 2>&1 &
##
nohup python3 -m fastchat.serve.vllm_worker --num-gpus 2 --quantization awq --model-names yi-34b \
--model-path ./Yi-34B-Chat-4bits --controller-address http://127.0.0.1:21001 \
--worker-address http://127.0.0.1:8080 --host 0.0.0.0 --port 8080 > model_worker.log 2>&1 &
4,运行占用 gpu

5,效果,还是会有英文出现的BUG

6,同时启动界面,方法本地开启 6006 端口即可
只限制在内蒙古机房,其他机房需要企业用户!!
在本地开启 6006 端口即可:

但是模型没有选择出来,不知道咋回事,下次再研究。
7,总结
使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度23 words/s。
随着大模型的参数增加,企业用户再使用的是特别需要大参数的模型了。
因为大模型在更加准确。硬件都不是问题。通过多卡的方式可以成功部署。
2张 3090,或者 4090 就可以部署 Yi-34B-Chat-int4模型了。
但是目前看中文稍微有点小问题,会返回英文,相信很快会迭代下一个版本了。
同时,已经有猎户星空Yi-34B-Chat,基于 yi-34b进行优化了。马上去研究下:文章来源:https://www.toymoban.com/news/detail-766681.html
https://modelscope.cn/models/OrionStarAI/OrionStar-Yi-34B-Chat/summary文章来源地址https://www.toymoban.com/news/detail-766681.html
到了这里,关于使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度23 words/s的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!