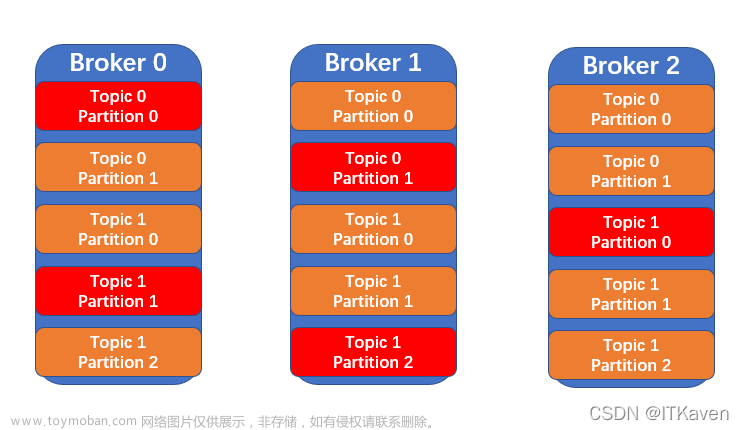
首先通过这个命令什么也不加参数可以看到参数的详解
./kafka-topics.sh
创建一个topic基本参数
连接kafka : --zookeeper
操作一个topic : --topic
对一个topic进行什么样的操作?增–create删–delete改–alter查–describe
指定分区数:–partitions
指定副本个数:–replication-factor
1、创建一个test0主题并指定分区数1副本数1
./kafka-topics.sh --zookeeper 192.168.124.8:2181 --topic test0 --create --replication-factor 1 --partitions 1
2、查看都有哪些主题
./kafka-topics.sh --zookeeper 192.168.124.8:2181 --list
3、查看主题test0的详细信息
./kafka-topics.sh --zookeeper 192.168.124.8:2181 --topic test0 --describe
4、修改分区为3 分区数只能增加不能减少!
./kafka-topics.sh --zookeeper 192.168.124.8:2181 --topic test0 --alter --partitions 3
5、另外这里不能通过命令行的方式去修改副本
./kafka-topics.sh --zookeeper 192.168.124.8:2181 --topic test0 --alter --replication-factor 3
6、发送消息到topic
./kafka-console-producer.sh --broker-list 192.168.124.8:9092 --topic test0
7、消费者查看消息
# 增量消费数据,以前发送的不能读取到
./kafka-console-consumer.sh --bootstrap-server 192.168.124.8:9092 --topic message
# --from-beginning 读取历史消息
./kafka-console-consumer.sh --bootstrap-server 192.168.124.8:9092 --topic message --from-beginning
主题创建
./kafka-topics.sh --zookeeper 192.168.124.8:2181 --topic message --create --replication-factor 1 --partitions 1
生产者
kafka生产者发送消息
添加依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
// 简单发送数据
@Test
void SimpleSendData(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.8:9092");
// 指定key和value的序列化类型
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// create producer 我们写入 hello 的时候 没有key 实际key="" value="hello" 所以都是String 对应下面的K, V
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
//简单消息发送
kafkaProducer.send(new ProducerRecord<>("message", "hello world "));
// close
kafkaProducer.close();
}
进入容器消费者查看消息是否发送成功
docker exec -it kafka /bin/bash
cd /opt/kafka_2.13-2.8.1/bin
# 消费者 消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.124.8:9092 --topic message --from-beginning
发现消息正常消费。
带有回调函数发送消息
@Test
void testProducerCallback(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.8:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// create producer
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
// 也可以定义一个类实现Callback接口
kafkaProducer.send(new ProducerRecord<>("message", "hello world exec callback"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){// 没有异常发送成功
System.out.println("topic :" +metadata.topic());
System.out.println("分区partition :" +metadata.partition());
/*
topic :message
分区partition :0
*/
}else {
// 打印异常信息
exception.printStackTrace();
}
}
});
// close
kafkaProducer.close();
}
lombda简化写法
@Test
void testProducerCallbacklombda(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.8:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// create producer
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
// 也可以定义一个类实现Callback接口
kafkaProducer.send(new ProducerRecord<>("message", "hello world exec callback2"), ((metadata, exception) -> {
if(exception==null){// 没有异常发送成功
System.out.println("topic :" +metadata.topic());
System.out.println("分区partition :" +metadata.partition());
/*
topic :message
分区partition :0
*/
}else {
// 打印异常信息
exception.printStackTrace();
}
}));
// close
kafkaProducer.close();
}
上述都是异步发送消息
同步发送 sync
调用 send() 方法,然后再调用 get() 方法等待 Kafka 响应。如果服务器返回错误,get() 方法会抛出异常,
如果没有发生错误,我们会得到 RecordMetadata 对象,可以用它来查看消息记录。
指定分区发送
@Test
void userPortitionsSend(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.8:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// create producer
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
/*
默认的分区规则 DefaultPartitioner
指定发送到哪个分区 0 后面有个key 空即可
*/
kafkaProducer.send(new ProducerRecord<>("message", 2,"","hello world exec callback3"),((metadata, exception) -> {
if(exception==null){// 没有异常发送成功
System.out.println("topic :" +metadata.topic());
System.out.println("分区partition :" +metadata.partition());
/*
topic :message
分区partition :2
*/
}else {
// 打印异常信息
exception.printStackTrace();
}
}));
kafkaProducer.close();
}
指定key 按照key的哈希值 对分区取模 映射
kafkaProducer.send(new ProducerRecord<>("message", "a","hello world exec callback"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){// 没有异常发送成功
System.out.println("topic :" +metadata.topic());
System.out.println("分区partition :" +metadata.partition());
/*
topic :message
分区partition :0
*/
}
}
});
希望把订单表里的所有数据发送到 kafka 的某一个分区 ? 实现 只需在key上放上订单的表名字 —一定会发到一个分区上
自定义分区器
1、需求:实现一个分区器实现,发送过来的数据中如果包含zero就发送0号分区,不包含zero就发往1号分区。
2、定义类实现Partitioner接口
MyPartitioner.java
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// get data
String msgValue = value.toString();
int partition;
if(msgValue.contains("zero")){
partition=0;
}else {
partition=1;
}
return partition;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
@Test
void customPartitionSend(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.8:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyPartitioner.class);
// create producer
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
kafkaProducer.send(new ProducerRecord<>("message", "hello world exec callback"),((metadata, exception) -> {
if(exception==null){// 没有异常发送成功
System.out.println("topic :" +metadata.topic());
System.out.println("分区partition :" +metadata.partition());
/*
topic :message
分区partition :2
*/
}else {
// 打印异常信息
exception.printStackTrace();
}
}));
// close
kafkaProducer.close();
}
上述方式实现了自定义分区器。
提高生产者吞吐量
@Test
void testproducer(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092,localhost:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//缓冲区大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,64*1024*1024);// 64M 缓冲区大小
//批次大小 batch.size linger.ms 批次设置32k 延迟设置 5ms 两个合理设置 等5ms 处理
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,32*1024*1024);// 批次大小 32K
//linger.ms
properties.put(ProducerConfig.LINGER_MS_CONFIG,5);// 5ms
//压缩
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");//压缩类型 snappy
// create producer
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("message","hello world "+i));
}
// close
kafkaProducer.close();
}
数据可靠性
acks=0,生产者发送过来数据就不管了,Leader一旦崩掉了,也没有办法。可靠性差,效率高;
acks=1,生产者发送过来数据Leader应答,如果应答完,Leader还没同步给Follower副本就挂了,此时新的leader就会产生,新的Leader就没有办法收到原数据(因为生产者已经认为发送成功了)。可靠性中等,效率中等;
-1(all):生产者发送过来的数据,Leader+isr队列里面的所有收齐数据后应答。-1和all等价
@Test
void testproducer(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092,localhost:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//缓冲区大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,64*1024*1024);// 64M 缓冲区大小
//批次大小 batch.size linger.ms 批次设置32k 延迟设置 5ms 两个合理设置 等5ms 处理
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,32*1024*1024);// 批次大小 32K
//linger.ms
properties.put(ProducerConfig.LINGER_MS_CONFIG,5);// 5ms
//压缩
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");//压缩类型 snappy
//----
properties.put(ProducerConfig.ACKS_CONFIG,"1");// acks 数据可靠性 default all
properties.put(ProducerConfig.RETRIES_CONFIG,3);// 重试次数 default max(int)
//---
// create producer
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("message","hello world "+i));
}
// close
kafkaProducer.close();
}
幂等性
生产者不论向Broker发送多少次重复数据,Broker端都只会持久化一次,保证了不重复。(幂等性默认开启,只保证单分区单会话内不重复,kafka挂掉再重启还是会产生重复数据)
生产者事务
开启事务必须开启幂等性。(!必须指定事务的id,ack=all)第五条消息发送失败,终止了。
@Test
void test(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092,localhost:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//缓冲区大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,64*1024*1024);// 64M 缓冲区大小
//批次大小 batch.size linger.ms 批次设置32k 延迟设置 5ms 两个合理设置 等5ms 处理
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,32*1024*1024);// 批次大小 32K
//linger.ms
properties.put(ProducerConfig.LINGER_MS_CONFIG,5);// 5ms
//压缩
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");//压缩类型 snappy
//----
properties.put(ProducerConfig.ACKS_CONFIG,"all");// acks 数据可靠性 default all
properties.put(ProducerConfig.RETRIES_CONFIG,3);// 重试次数 default max(int)
//---
// 必须指定事务id 否则失败 事务id任意取 只要保证全局唯一即可
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"tranactional_id_01");
// create producer
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
// 初始化 即初始化事务
kafkaProducer.initTransactions();
// 开启事务
kafkaProducer.beginTransaction();
try {
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("message","hello world "+i));
if(i==4){
int j=1/0;
}
}
kafkaProducer.commitTransaction();
} catch (ProducerFencedException e) {
kafkaProducer.abortTransaction();
}finally {
// close
kafkaProducer.close();
}
}
消费者
一个消费者去消费某个主题的数据
docker exec -it kafka /bin/bash
cd /opt/kafka_2.13-2.8.1/bin
# 生产者 生产消息
./kafka-console-producer.sh --broker-list 192.168.124.8:9092 --topic message
生产消息。
public static void main(String[] args) {
Properties properties=new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//!!!! 必须配置组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"message");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList("message"));
while (true){
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 拉的动作 1s 拉一次
consumerRecords.forEach(data->{
System.out.println(data);
});
}
}
消费者消费一个分区
使用生产者对某个分区生产数据
@Test
void userPortitionsSend(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.8:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// create producer
KafkaProducer<String,String> kafkaProducer =new KafkaProducer<String, String>(properties);
/*
默认的分区规则 DefaultPartitioner
指定发送到哪个分区 0 后面有个key 空即可
*/
kafkaProducer.send(new ProducerRecord<>("message", 2,"","hello world exec callback3"),((metadata, exception) -> {
if(exception==null){// 没有异常发送成功
System.out.println("topic :" +metadata.topic());
System.out.println("分区partition :" +metadata.partition());
/*
topic :message
分区partition :2
*/
}else {
// 打印异常信息
exception.printStackTrace();
}
}));
kafkaProducer.close();
}
针对特定分区进行消费文章来源:https://www.toymoban.com/news/detail-767080.html
@Test
void consumerOnePartition(){
Properties properties=new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//!!!! 必须配置组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"message");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
topicPartitions.add(new TopicPartition("message",2));
// 订阅主题对应的分区
consumer.assign(topicPartitions);
while (true){
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 拉的动作 1s 拉一次
consumerRecords.forEach(data->{
System.out.println(data);
});
}
}
offset
kafka默认自动提交offest 默认5s提交一次。
手动提交offest
1、同步提交(commitSync)必须等待offest提交完毕,再去消费下一批数据
2、异步提交(commitAsync)发送完提交offest请求后,就开始消费下一批数据了。
手动提交文章来源地址https://www.toymoban.com/news/detail-767080.html
@Test
void commitCustom(){
Properties properties=new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//!!!! 必须配置组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"message");
// 手动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
topicPartitions.add(new TopicPartition("message",2));
// 订阅主题对应的分区
consumer.assign(topicPartitions);
while (true){
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 拉的动作 1s 拉一次
consumerRecords.forEach(data->{
System.out.println(data);
});
// 手动提交 同步提交
consumer.commitSync();
// 异步提交
//consumer.commitAsync();
}
}
到了这里,关于kafka常见命令介绍和使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!