基于spark对美国新冠肺炎疫情数据分析
GCC的同学不要抄袭呀!!!严禁抄袭
有任何学习问题可以加我微信交流哦!bmt1014
前言
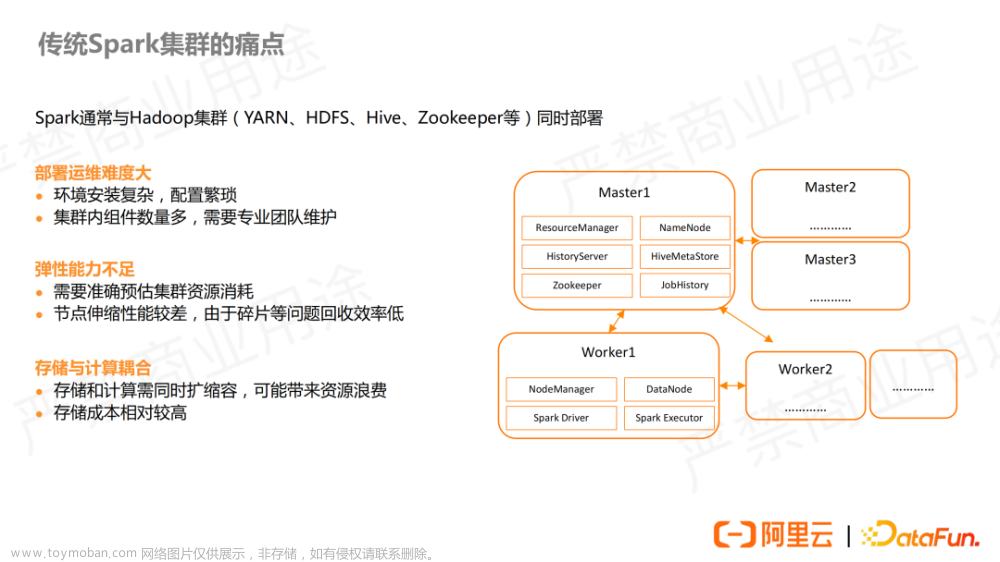
2020年美国新冠肺炎疫情是全球范围内的一场重大公共卫生事件,对全球政治、经济、社会等各个领域都产生了深远影响。在这场疫情中,科学家们发挥了重要作用,积极探索病毒特性、传播机制和防控策略,并不断推出相关研究成果。
本篇论文旨在使用 Spark 进行数据处理分析,以了解2020年美国新冠肺炎疫情在该国的传播情况,并探讨各州疫情数据之间的相互关系。在数据处理和可视化方面采用 Spark 和 Python 技术进行实现。
通过对数据的收集、清理、整合和分析,希望能够更全面地了解该疫情在美国的传播情况,为疫情防控提供数据支持和指导,同时也为数据分析领域的技术应用提供一个实际案例。
1、需求分析
对美国2020年新冠新冠肺炎确诊病例进行数据分析,以Python为编程语言,使用Spark对数据进行分析,描述分析结果,并且用python对分析结果进行可视化。主要有以下两个方面的分析:
时间趋势分析:分析每日/每周/每月的新增确诊病例数、治愈率和死亡率的变化趋势,以及与时间相关的其他指标。
地理分布分析:分析不同州/城市的确诊病例数、死亡数、治愈数等,探究地域差异与人口密度等因素的关系。为今后疫情防控提供经验和参考。
1.1数据来源
使用的数据集来自数据网站Kaggle的美国新冠肺炎疫情数据集(从学习通-期末大作业中下载数据集),该数据集以数据表us-counties.csv组织,其中包含了美国发现首例新冠肺炎确诊病例至2020-05-19的相关数据。数据包含以下字段:
字段名称 字段含义 例子
date 日期 2020/1/21;2020/1/22;
county 区县(州的下一级单位) Snohomish;
state 州 Washington
cases 截止该日期该区县的累计确诊人数 1,2,3…
deaths 截止该日期该区县的累计死亡人数 1,2,3…
部分数据如图:
图1-us-counties.csv文件数据图
1.2具体要求和目标
1)原始数据集是以.csv文件组织的,为了方便spark读取生成RDD或者DataFrame,首先将csv转换为.txt格式文件。转换操作使用python实现。
2)将文件上传至HDFS文件系统中,路径为:“/user/hadoop/us-counties.txt”
3)采用编程方式读取us-counties.txt生成DataFrame。
4)使用Spark对数据进行分析。主要统计以下指标,所有结果保存为.json文件,分别是:
(1)统计美国各州的累计确诊人数和死亡人数和病死率,并将 结果保存到Mysql数据库中。
(2)统计美国确诊人数最多的十个州。
(3)统计美国死亡人数最多的十个州。
(4)统计美国确诊人数最少的十个州。
5)将Spark计算结果.json文件下载到本地文件夹。对结果进行数据可视化。
6)程序源代码要求关键代码有行注释,函数有IPO注释,类和对象有属性注释、方法注释。
2、总体设计
2.1本次实验所用环境
(1)Oracle VM VirtualBox虚拟机
(2)Ubuntu系统
(3)Hadoop2.10.0 ,MySQL
(4)使用Python: 3.8
(5)Spark: 2.4.7
(6)Anaconda和Jupyter Notebook
2.2实现流程

图2-流程图
3、详细设计
3.1 使用python对文件类型转换
代码:
import pandas as pd
data = pd.read_csv(“us-counties.csv”)
file_dir = ‘./’
data.to_csv(file_dir + ‘us-counties.txt’, sep=‘\t’,index=False, header = True)
运行之后在同级目录下多了一个us-counties.txt文件
3.2 上传文件到hdfs
通过设置共享文件夹,将windows的us-counties.txt文件上传到Ubuntu系统上
代码:
sudo mount -t vboxsf sharefile /home/hadoop/下载
其中sharefile为共享文件夹路径,/home/hadoop/下载路径为虚拟机路径
切换到hadoop目录,启动hdfs
代码:
cd /usr/local/hadoop/
./sbin/start-all.sh
新开一个终端,将us-counties.txt文件上传到hdfs
代码:
cd /usr/local/hadoop/
./bin/hdfs dfs -put /home/hadoop/文档/us-counties.txt /user/hadoop/
./bin/hdfs dfs -ls /user/hadoop/
3.3 启动mysql和pyspark
启动mysql
mysql -u root -p
启动pyspark
cd /usr/local/spark
./bin/pyspark
3.4 pyspark读取数据并且分析
(1)统计美国各州的累计确诊人数和死亡人数和病死率,并将结果保存到Mysql数据库中
代码:
读取txt文件
rdd = spark.sparkContext.textFile(“/user/hadoop/us-counties.txt”)
将数据转换为DataFrame格式
df = rdd.map(lambda x: x.split(“\t”))
schemaString = “date country state cases deaths”
fields = [StructField(field_name,StringType(),True) for field_name in schemaString.split(" ")]
schema = StructType(fields)
df = df.map(lambda p:Row(p[0],p[1],p[2],p[3],p[4]))
df = spark.createDataFrame(df,schema) #将表头和数据进行连接
将数据类型转换为对应的类型
df = df.withColumn(“cases”, df[“cases”].cast(“int”))
df = df.withColumn(“deaths”, df[“deaths”].cast(“int”))
df = df.withColumn(“date”, df[“date”].cast(“date”))
统计美国各州的累计确诊人数和死亡人数和病死率
from pyspark.sql.functions import when
from pyspark.sql.functions import format_string
result1 = df.groupBy(“state”).sum(“cases”, “deaths”)
将分母为0的值转换为0
result1 = result1.select(“state”, “sum(cases)”, “sum(deaths)”).withColumn(
“mortality_rate”,
when(result1[“sum(cases)”] == 0, 0).otherwise(result1[“sum(deaths)”]/result1[“sum(cases)”]))
#将数据写入数据库,数据库名为spark,表名为result1(表不用创建)
result1.write.format(“jdbc”).options(
url=“jdbc:mysql://localhost:3306/spark”,
driver=“com.mysql.jdbc.Driver”,
dbtable=“result1”,
user=“root”,
password=“1”
).mode(“overwrite”).save()
#将数据保存到Ubuntu本地
result1.repartition(1).write.format(“csv”).save(“file:///usr/local/test/result1.csv”)
(2)统计美国确诊人数最多的十个州
代码:
#根据state字段进行分组,求和cases数据,再根据求和的累计确诊数据降序排序,取出前10
result2 = df.groupBy(“state”).sum(“cases”).orderBy(“sum(cases)”, ascending=False).limit(10)
#将结果设置分区数为1,文件类型为json,以覆盖的方式写入
result2.repartition(1).write.format(“json”).mode(“overwrite”).save(“file:///usr/local/test/quezhentop10.json”)
(3)统计美国死亡人数最多的十个州
代码:
#根据state字段进行分组,求和deaths数据,再根据求和的死亡最多的十个州数据降序排序,取出前10
result3 = df.groupBy(“state”).sum(“deaths”).orderBy(“sum(deaths)”, ascending=False).limit(10)
result3.repartition(1).write.format(“json”).mode(“overwrite”).save(“file:///usr/local/test/deathstop10.json”)
(4)统计美国确诊人数最少的十个州
代码:
#根据state字段进行分组,求和cases数据,再根据求和的确诊数据升序排序,取出前10
result4 = df.groupBy(“state”).sum(“cases”).orderBy(“sum(cases)”).limit(10)
result4.repartition(1).write.format(“json”).mode(“overwrite”).save(“file:///usr/local/test/quezhenbot10.json”)
4、程序运行结果测试与分析
4.1 使用python转换txt文件类型结果,如图3所示

图3-txt文件图
4.2 启动hdfs,上传文件

图4-启动hdfs
图5-上传文件到hdfs图
4.3 启动mysql和pyspark
如图6、7
图6-启动mysql图
图7-启动pyspark
4.4 统计美国各州的累计确诊人数和死亡人数和病死率结果
在pyspark上查看结果,如图8
图8-累计确诊、死亡、病死率图
在mysql上查看数据,如图9
图9-mysql累计确诊、死亡、病死率图
4.5 统计美国确诊人数最多的十个州结果
如图10
图10-确诊人数最多的十个州
4.6统计美国死亡人数最多的十个州结果
如图11
图11-死亡人数最多的十个州
4.7统计美国确诊人数最少的十个州
如图12
图12-确诊人数最少的十个州
4.8 pyecharts绘制累计确诊数和死亡数的折线图
如图13:
图13-计确诊数和死亡数折线图
在2020年3月份,随着时间的增加,累计确诊数也随着不断增加,死亡数也在4月初以后居高不下。
4.9 每个州的累计确诊和死亡数的折线图
如图14、图15:
图14-累计确诊和死亡数的折线图一
图15-累计确诊和死亡数的折线图二
可以看出每个州的确诊人数都是随着时间不断上升。
4.10 各州的累计确诊人数和死亡人数
如图16
图16-各州的累计确诊人数和死亡人数
说明:累计病例数和死亡人数呈高度正相关关系。这意味着如果一个州的累计病例数较高,则其死亡人数也可能较高。累计病例数和死亡人数的分布不均。例如,纽约州的累计病例数和死亡人数远高于其他州,而南达科他州的累计病例数和死亡人数则相对较低。
4.11确诊数最多的20个州–词云图
如图17
图17-词云图
说明:1、词云图中的字号和颜色反映了各州的确诊数大小。字号越大表示该州的确诊数越高,颜色较深则意味着该州在确诊数排名中处于上位。从词云图可以看出,纽约州确诊数明显高于其他州。而其他州的确诊数则相对较少
2、词云图中的字体名称和布局随机生成,因此每次生成的词云图可能会不同,但是其反映的信息是一致的。
3、通过制作词云图,可以直观地展示和比较各州之间的确诊数差异,并有助于我们更好地理解和分析疫情的发展态势。
4.12 美国死亡人数最多的十个州
如图18
图18-死亡人数最多的十个州
说明:横轴表示各州名称,纵轴表示各州的死亡人数。
从柱状图可以看出,纽约州的死亡人数最多,达到了接近100万人,其余州的死亡人数相对较少。柱状图能够使我们更好地了解疫情对不同州的影响程度,有助于政策制定者和公众做出相应的决策和行动。在此基础上,可以针对不同州的疫情情况采取有针对性的措施,以有效遏制病毒的传播并保障公众的健康安全。
4.13 美国各州死率图
如图19
图19-各州死率图
饼图中的各个扇形表示不同的州,其面积大小对应该州的死亡率。
从饼图可以看出,纽约州的死亡率最高,达到了7%,其他州的死亡率相对较低。
4.14 美国累计死亡人数和死亡率饼图
如图20
图20-累计死亡人数和死亡率饼图
上图展示了总死亡人数和未死亡人数的比例。饼图中的两个扇形表示死亡人数和未死亡人数,其面积大小对应该类别的人数。从饼图可以看出,截至目前为止,美国新冠肺炎的累计死亡人数占总病例数的比例约为4.7%,而未死亡的人数占比约为95.3%。
4.15 美国累计病例前十的州–漏斗图
如图21
图21-漏斗图
上图展示了病例数前十的州的比较。漏斗图中的每个环节代表一个州,其大小对应该州的累计病例数。从漏斗图可以看出,排名前三的州分别为纽约州、新泽西州和马萨诸塞州,它们的累计病例数分别为1323万、488万和247万。
4.16 累计病例数最少的十个州
图22
图22-累计病例数最少的十个州
从柱状图可以看出,累计病例数最少的前三个州分别为北马里亚纳群岛、维尔京群岛和阿拉斯加,它们的累计病例数分别为689、3028和16291。
5、结论与心得
通过对美国新冠肺炎疫情数据的处理和分析,得出了以下结论和心得:
1、美国新冠肺炎疫情在2021年初期迅速蔓延,尤其是在东海岸地区。但到了夏季,疫情在一些州开始有所缓解。
2、疫情对不同州的影响程度存在很大差异,一些州的死亡率和感染率明显高于其他州。这与各州的人口密度、经济水平、医疗资源等因素有关。
3、社交距离和口罩等防护措施可以有效减缓病毒传播速度,并降低死亡率和感染率。
4、对疫情数据的及时监测和预警可以帮助政府和公众做出更有效的防控决策。同时,数据处理和分析技术在疫情防控中发挥着越来越重要的作用。
总之,美国新冠肺炎疫情数据分析不仅能够为我们更全面地了解该疫情在该国的传播情况,也能为疫情防控提供数据支持和指导,并且能够在数据分析领域中提供实际案例和技术应用。
学到了以下几点:
1、数据清洗和预处理非常重要。在进行数据分析前,需要对原始数据进行清洗和预处理,包括去除缺失值、重复值、异常值等,以确保得到准确和可靠的结果。
2、数据可视化可以更清晰地展现数据。通过将数据可视化并呈现在图表中,可以更直观地展现数据,发现数据之间的关系和趋势,并有助于进一步分析和推理。
3、分析方法和技术的选择也很重要。在进行数据分析时,需要根据数据特点和问题需求,选择适合的分析方法和技术,以获得更精确和有意义的结论。
在实验过程中,我们遇到了一些困难,其中一个主要问题是数据集的规模比较大,导致数据处理和计算花费时间较长,影响了结果的准确性和实验效率。
为解决这个问题,我们采用了 Spark 技术进行数据处理和分析,利用它的分布式计算能力来加速计算和提高效率。最终,我们成功地完成了实验,并获得了有意义的结果。
参考文献
[1]杨伟民, 姚玉华, 刘宪鹏. “基于Spark的COVID-19数据分析与可视化展示.” 计算机应用研究. 2020年, 第37卷第12期.
[2]林子雨、郑海山、赖永炫.《Spark编程基础(Python版)》[M]. 北京:人民邮电出版社,2020.
[3]林子雨.大数据技术原理与应用[M].北京:人民邮电出版社,2017.
[4]https://blog.csdn.net/weixin_43385372/article/details/117608253文章来源:https://www.toymoban.com/news/detail-767164.html
有关于学习问题的话,可以加我微信交流bmt1014
 文章来源地址https://www.toymoban.com/news/detail-767164.html
文章来源地址https://www.toymoban.com/news/detail-767164.html
到了这里,关于基于spark对美国新冠肺炎疫情数据分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!