数据聚合
聚合的分类
聚合 (aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
桶(Bucket)聚合:用来对文档做分组
TermAggregation:按照文档字段值分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量(Metric)聚合:用以计算一些值,比如: 最大值、最小值、平均值等Avg:求平均值Max:求最大值Min:求最小值Stats:同时求max、min、avg、sum等
管道(pipeline)聚合: 其它聚合的结果为基础做聚合
参与聚合的字段类型必须是:keyword、数值、日期、布尔
DSL实现Bucket聚合
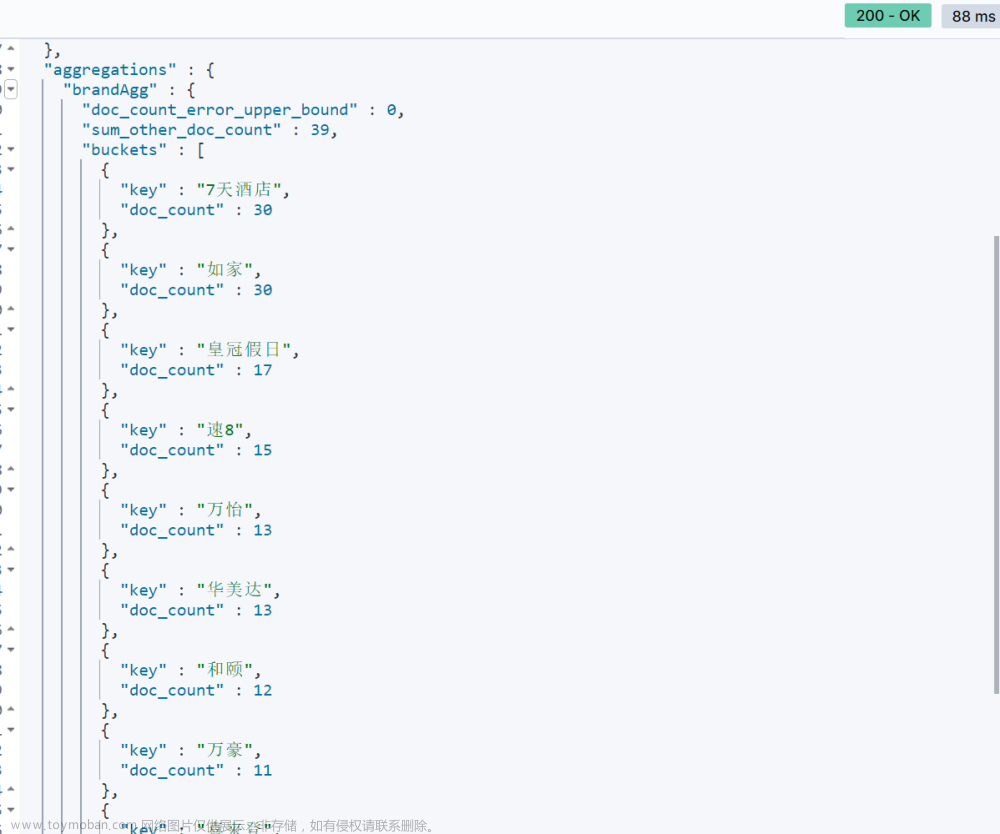
现在,我们要统计所有数据中的酒店品牌有几种,此时可以根据酒店品牌的名称做聚合。类型为term类型,DSL示例

查询结果,在buckets中,返回了所有酒店品牌和该品牌酒店的数量

Bucket聚合-聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照 count降序排序。我们可以修改结果排序方式

可以看到,查询出的聚合结果,品牌按照其酒店数量由少到多排列

Bucket聚合-限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可

价格在200以下的酒店品牌只有三家

DSL实现Metrics聚合
例如,我们要求获取每个品牌的用户评分的min、max、avg等值我们可以利用stats聚合

可以看到,对分数score增加过stats聚合后,聚合结果增加了每个品牌的分数的最小值、最大值等

RestAPI实现聚合
我们以品牌聚合为例,演示下Java的RestClient使用,先看请求组装

编写一个测试类


再看下聚合结果解析

在测试类中编写解析代码


多条件聚合
案例:在IUserService中定义方法,实现对品牌、城市、星级的聚合
需求:搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的

在IUserService中定义一个方法,实现对品牌、城市、星级的聚合,方法声明如下

实现类中编写具体的业务方法

将选中部分代码抽取出来成为一个单独的方法

然后发请求,解析结果

把解析结果这部分的代码抽取出来,因为后面要对品牌brandAgg、城市cityAgg、星级starAgg的聚合结果都解析一下,抽取方便调用,代码简化

抽取之后,对品牌brandAgg、城市cityAgg、星级starAgg的聚合结果都调用该方法解析出来,然后存到Map中,最终返回即可

编写测试类调用该服务

结果显示如下

带过滤条件的聚合
对接前端接口
前端页面会向服务端发起请求,查询品牌、城市、星级等字段的聚合结果:
可以看到请求参数与之前search时的RequestParam完全-致,这是在限定聚合时的文档范围。
例如:用户搜索“外滩”,价格在300~600,那聚合必须是在这个搜索条件基础上完成。
因此我们需要:
1.编写controller接口,接收该请求
2.修改IUserService#getFilters()方法,添加RequestParam参数
修改getFilters方法的业务,聚合时添加query条件
参数与查询时的参数一致(参考上一篇文章的最后案例)上一篇文章最后的案例1

业务接口定义方法

服务实现类中的方法增加对参数的封装,查询的限定,用的这个方法也和之前查询时的封装方法一样上一篇文章最后的案例1

什么都不限定,返回的聚合信息这么多

限定一个价格区间,发现返回的聚合信息变少了

自动补全
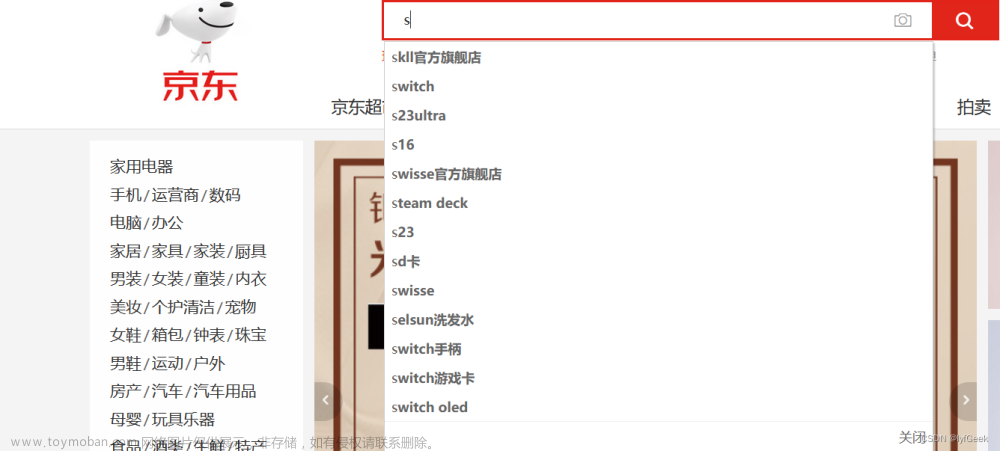
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图

使用拼音分词
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。
安装方式与IK分词器一样,分三步:
1.解压
2.上传到虚拟机中,elasticsearch的plugin目录
3.重启elasticsearch
4.测试
1.解压

2.上传到虚拟机中,elasticsearch的plugin目录

3.重启elasticsearch

4.测试
对每个汉字分出单独的拼音词条,并且还有拼音简写

自定义分词器
elasticsearch中分词器 (analyzer) 的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
tokenizer: 将文本按照一定的规则切成词条 (term)。例如keyword,就是不分词;还有ik_smart
tokenizer filter: 将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等

我们可以在创建索引库时,通过settings来配置自定义的analyzer (分词器)

测试
创建索引库


可以看到完成了自定义的分词器设置

往索引库中新增2条文档,狮子和虱子,然后进行检索查询,shizi,发现查询结果两个文档都查询了出来

但是,当查的匹配信息是调入狮子笼咋办,狮子肯定和虱子没关系,但是因为该name字段的分词器的缘故,虱子也被匹配上了因为拼音一致

拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用

因此字段在创建倒排索引时应该用my analyzer分词器;字段在搜索时应该使用ik smart分词器

在创建索引库时,用上述方法创建,然后再次查询,发现虱子没被匹配上了

completion suggester查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
参与补全查询的字段必须是completion类型
字段的内容一般是用来补全的多个词条形成的数组。

查询语法如下

测试

案例:实现hotel索引库的自动补全、拼音搜索功能
实现思路如下:
1.修改hotel索引库结构,设置自定义拼音分词器
2.修改索引库的name、all字段,使用自定义分词器
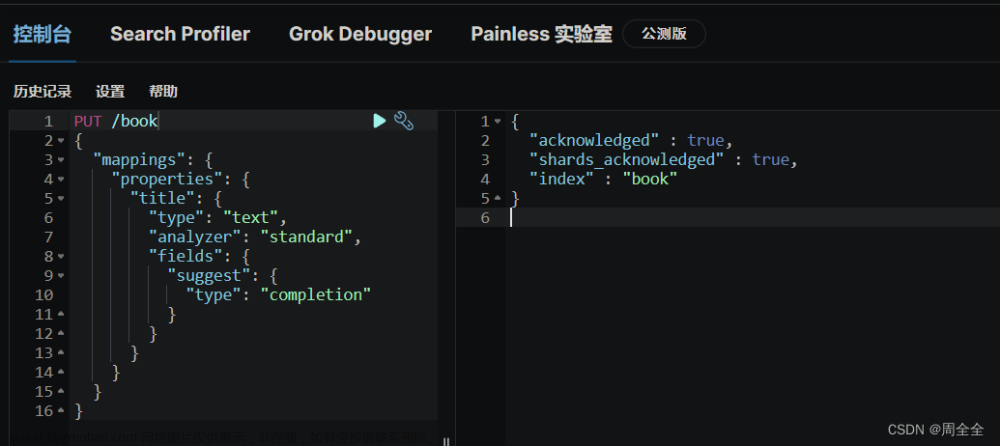
3.索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
4.给HotelDoc类添加suggestion字段,内容包含brand、business
5.重新导入数据到hotel库
1.修改hotel索引库结构,设置自定义拼音分词器
2.修改索引库的name、all字段,使用自定义分词器
3.索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器


4.给HotelDoc类添加suggestion字段,内容包含brand、business


再次运行之前的批量从数据库中将数据插入es中的方法

再次查询索引库,发现suggestion字段已经由品牌和商圈填充,是数组格式,但是有的商圈是两个,需要将这两个也分开

故修改hotelDoc类中有参构造器中的代码

重新运行该方法后,再次查询,发现该商圈信息也已经分开

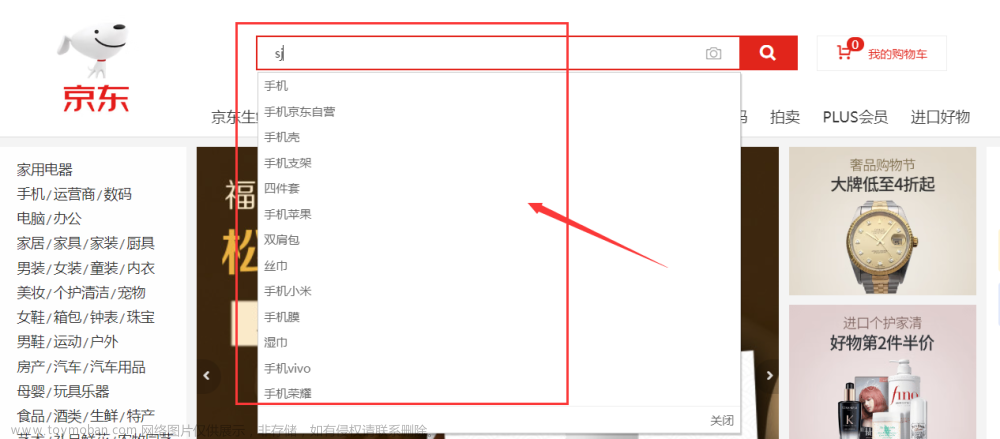
然后用Completion Suggester查询语法来实现自动补全功能,查“sd”,查出了suggestion中含有“上地产业园”的文档

RestAPI实现自动补全
先看请求参数构造的API

编写测试类


再来看结果解析

增加测试类中的解析结果


案例:实现酒店搜索页面输入框的自动补全
查看前端页面,可以发现当我们在输入框键入时,前端会发起ajax请求

在服务端编写接口,接收该请求,返回补全结果的集合,类型为List<String>

服务层生成对应方法

业务层具体代码


try catch 一下

实现功能

数据同步
数据同步问题分析
elasticsearch中的酒店数据来自于mysql数据库,因此mysq[数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步
在微服务中,负责酒店管理(操作mysql)的业务与负责酒店搜索(操作elasticsearch )的业务可能在两个不同的微服务上数据同步该如何实现呢?
方案一:同步调用
优点:实现简单,粗暴
缺点:业务耦合度高

方案二:异步通知
优点:低耦合,实现难度一般
缺点:依赖mq的可靠性

方案三:监听binlog
优点:完全解除服务间耦合
缺点:开启binlog增加数据库负担、实现复杂度高

案例:利用MQ实现mysql与elasticsearch数据同步
利用课前资料提供的hotel-admin项目作为酒店管理的微服务。当酒店数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作
步骤:
导入课前资料提供的hotel-admin项目,启动并测试酒店数据的CRUD
声明exchange、queue、RoutingKey
在hotel-admin中的增、删、改业务中完成消息发送
在hotel-demo中完成消息监听,并更新elasticsearch中数据
启动并测试数据同步功能

启动hotel-admin项目

在es的微服务hotel-demo中引入rabbitmq依赖

yaml配置文件配置mq相关配置

定义一个常量类,设置队列名字,交换机名字,包括key

创建一个配置类,声明交换机、队列,以及绑定关系


在hotel-admin项目中引入mq的依赖

在其项目的yaml文件中配置mq的配置

在对酒店信息进行crud操作的controller中引入对mq发消息的类rabbitTemplate

在新增酒店信息和更新酒店信息的方法中,插入和更新信息到数据库中后,要对队列发送一个消息,并且key是酒店插入的key,代表消息发送至插入酒店信息的队列中,将这个插入酒店的id传上去

在删除酒店信息的方法中,信息从数据库中删除后,要对队列发送一个消息,并且key是酒店删除的key,代表消息发送至删除酒店信息的队列中,将这个删除酒店的id传上去

在对es操作的hotel-demo项目中编写队列监听类,分别监听两个队列,并执行相关的业务操作

服务层增加这两个业务操作,在es中增加酒店信息方法和删除酒店信息方法

增加酒店信息具体的业务方法

删除酒店具体的业务方法文章来源:https://www.toymoban.com/news/detail-767179.html
 文章来源地址https://www.toymoban.com/news/detail-767179.html
文章来源地址https://www.toymoban.com/news/detail-767179.html
到了这里,关于微服务学习|elasticsearch:数据聚合、自动补全、数据同步的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!