
1、方案设计
1.采用舵机作为魔方机器人的驱动电机,从舵机的驱动原理可知:舵机运行的速度和控制器的主频没有关系,所以采用单片机和采用更高主频的嵌入式处理器相比在控制效果上没有什么差别。单片机编程过程简单,非常容易上手,而且不需要进行操作系统的移植,非常适合对魔方机器人的舵机进行控制。
2.复原时间是魔方机器人的一个非常重要,可以说是最为重要的一个参数,本文的软件设计中涉及到了大量的算法,如 Kocemba 复原算法和 KNN 分类算法等,而控制器主频对于算法运行时间的长短起着决定性的作用。
所以在本文的方案设计中,我们把核心算法全部交给 Allwinner A20 运行的 APP。
Kociemba算法,又称为二阶段算法,是一个使用较短时间和较少次数还原魔方的算法。按照以前网上的说法,详细的原理可以在网页http://kociemba.org/cube上面找到。然而现在这一个网页也是已经不存在了,其他网站所介绍的也是非常的简略。幸好,在我的努力之下,还是找到一些零星的资料,主要是一些外文的论文和一些github项目。通过几天的加班阅读,我总算是理解了大部分的内容。我把自己所理解的只是写在这篇论文上面,希望能给和我一样的魔方爱好者一些启发,同时也算是一个抛砖引玉,希望能够获得读者们更好的建议。

2、设计原理
1、Kociemba算法Kociemba算法,又称为二阶段算法,是一个使用较短时间和较少次数还原魔方的算法。按照以前网上的说法,详细的原理可以在网页http://kociemba.org/cube上面找到。然而现在这一个网页也是已经不存在了,其他网站所介绍的也是非常的简略。幸好,在我的努力之下,还是找到一些零星的资料,主要是一些外文的论文和一些github项目。通过几天的加班阅读,我总算是理解了大部分的内容。我把自己所理解的只是写在这篇论文上面,希望能给和我一样的魔方爱好者一些启发,同时也算是一个抛砖引玉,希望能够获得读者们更好的建议。
2、从魔方的状态数说起
这篇文章讨论的对象是三阶魔方,原则上Kociemba算法可以变形为四阶魔方的,但是这并不是本文要讨论的内容。首先我们先对魔方的元素进行命名上面的约定,魔方由26个方块组成,每个方块由1到3个面是露在外面的,有1个面的我们称为中心方块,两个面为边,三个面的为角。通过旋转,每个角有8中位置、3个方向,每个边有12种位置、2个方向。我们假定魔方的中心方块是不会移动的,也就是说,只有非中间层的面可以旋转,以后也是不考虑中间面的旋转。所以会产生变化的只有边和角的位置和方向,不考虑组合的合法性,魔方的总组合为:
8!12!(38)*(212)种
但是魔方会包括非法的情况,这里要考虑到魔方的状态集的问题。我们约定魔方的所有边和角的位置和方向为魔方的一个状态。魔方从一个状态通过若干次的旋转后,魔方的新状态一定和原状态在一个状态集里面。可以证明,魔方的状态集分成12个,每一个的总数是一样的,所以,实际上魔方的状态数为:
8!12!(38)*(212)/12种
这个数大概是4.3万亿亿,具体大小不必细究,反正非常大。如果使用最暴力的算法,例如DFS、BFS等,绝对会耗尽计算机的资源,更高阶的魔方就不用说了。所以,我们要对这些状态进行裁剪,Kociemba使用的就是因式分解的算法。打个比方,如果m=a*b,且a、b>2,那么令n=a+b,必有n<m。同理,将上面的式子分解为:8!、12!、(38)、(212),至少可以将空间缩小为一亿分之一。当然,实际上算法对其做出了更多的工作。
同理,将上面的式子分解为:8!、12!、(38)、(212),至少可以将空间缩小为一亿分之一。当然,实际上算法对其做出了更多的工作。<>
最后,我们将将魔方的面分为6个:T(上)、D(下)、F(前)、B(后)、L(左)、R(右)。面向X面,顺时针旋转X面90度表示为X、旋转半周为X2、逆时针旋转90度为X’。
3、魔方的特殊性质
人们发现,魔方具有一些优良的性质,这些性质可以帮助将状态数分解:
1.指定角的方向后,对于所有的面,旋转两次并不会改变角的方向,会有相对的两个面(例如前和后),旋转一次不会改变角的方向。其他面旋转一次,会按照特定的规律变换方向,如果我们把方向编码为0、1、
2,假如某一个面的四个角原始方向按照顺时针是co0、co1、co2、co3,那么如果这个面的一次旋转会改变四个角的方向的话,对角的两个角会变成co0+1、co2+1另外两个对角会变成co1-1、co3-1。
2.指定边的方向后,只有两个相对的面的旋转会改变边的方向,其余面的旋转不会改变。
下面,我们假定一次旋转上下面不会改变魔方的角的方向,一次旋转左右面会改变魔方边的方向。至于具体如何编码,我会在下下面详细阐述。
通过这两种性质,我们将魔方的状态分成两个状态集G1、G2。其中G1状态为魔方的原始状态经过若干步规定以内的旋转所组成的状态集,这规定的旋转包括:T、T’、D、D’、T2、D2、F2、B2、L2、R2。根据上面的假定,这些旋转不会改变魔方8个角的方向,也不会改变12条边的方向,而且原始状态下中间的四条边,在这个集合里面依然在中间层内。根据这一个结论,我们可以将魔方的总数减少为:
4!*8!*8!/12
第一个4!表示中间四条边的位置排列,第二个8!表示上下四条边的位置排列,第三个8!表示8个角的位置排列。在使用因式分解,总数就变为:4!+8!+8!,这个数少于10万,并且在下面会看到,使用这一种裁剪方法会获得较高的精度。
G2表示以G1的所有状态为原始状态,经过若干次任意旋转后的状态集,在这个状态集里面内有什么优良的的性质可以利用,所以实际上使用了单纯的裁剪手段。也是分成三组,第一组为编号为0到3的所有边的方向和位置,第二组为编号为4到11的所有边位置上面边的方向,第三组为所有角的方向,所以总数为A(12,4)*(26)+28+3^8种。
4、搜索算法
Kociemba算法使用了搜索算法还原魔方。具体来说,就是先使用搜索算法转换为G1状态,在使用另一种搜索方式转换为原始状态。使用何种搜索算法对于还原魔方至关重要,搜索算法选得不好,例如使用BFS解决问题,会耗尽计算机的资源。经过前辈的不断探索,最终改良出IDA*。所谓IDA*,就是A*算法加上迭代加深的升级版。迭代加深就是可以保证搜索树上面的任一个节点都可以获得精确的启发函数值,要实现迭代加深就必须先对搜索树上的各个节点进行预先的计算,也就是初始化。
具体到这里,就是在A*的启发函数初始化的时候,制作一个映射表,然后通过魔方从原始状态为起点进行若干次操作,组成一个根节点为魔方的原始状态的、具有一定深度的操作树。遍历操作树上面的所有节点,也就是每一个状态,从表上可以映射为一个启发函数值,其值的的大小就为节点的深度。因为此时的魔方的状态就是魔方在原始状态通过等于其深度的次数的操作结果,经过相反的操作当然可以还原魔方。同时,可以知道,操作数上面必然会有状态相同的不同节点,因为启发函数的值应该为最小值才可以保证精度,因此,我们在遍历操作树的时候,使用广度优先搜索,保证浅层的节点先被记录,而深层的同状态节点因为映射已经存在就会被忽略。
有了映射表,在调用启发函数的时候,根据当前的魔方状态,经过查表可以获得启发函数的值,使用A*算法判断魔方的下一个判断即可,同时因为迭代加深的缘故,节点的判断函数都是准确的,不需要记录对未搜索的可达节点。
那么,问题推到了映射表上面,如何设计高效的映射表?
5、映射表的设计
映射表只是一个概念,它代表从魔方的特定状态向最小还原步数的映射。具体需要选择什么实现,还需要看实际情况。实际需求可以总结为一下几点:
1.映射表初始化后不会发生改动,也就是说不需要动态的改动映射的内容和规模。
2.映射需要一个比较高的效率。
3.映射的规模是已知的。
4.映射表应该覆盖所有的状态编码组合。
第2条决定了不应该使用像std::map之类的树型映射表,最佳方案应该是数组。因为数组查询速度快,规模是固定的。只要我们找到一个哈希函数,将当前魔方的状态转换为一个整数,就可以完成映射表了。
6、方块编码
我认为,这一部分是算法的核心之一,之前的各种设计各种规律都是建立在这种编码方案之上的。这说明一个好的建模方案可以大大地减少问题的难度。
首先,我要介绍角的编码,容易知道,魔方有八个角,分别编码为0至7,编码与位置的对应关系与问题的解决没有关系。同理,魔方的12条边编码为0值11。
真正的问题在于边和方块的方向问题。我们知道,边和角的方向没有固定的参照物,因此,我们在编码的时候,通过规定某一些方向的方法规定方块的方向。对于边的方向,这比较简单,只要是0或者1即可。
对于角,情况就有点复杂,我在这里举个例子,说明一下编码的过程:
我们将T、F、R面交界处的角方块,暂称为方块1,方块1的原始位置为位置1。我们要求在位置1上面的各种角方块面,都要按照T、F、R方向的顺序表示,如果1号方块在1号位置的顺序刚好就是T、F、R,那么我们认为此时1号方块的方向就是0,除此之外,还有的可能的顺序就是F、R、T和R、T、F,我们分别标号为1和2。
由于T和D旋转是不会改变方块的方向,所以我们可以来一个T’旋转,是的T、F、L面交界处的角方块,我们暂称为方块2,到达位置1。此时从T、F、R面上面读取方块2,可以读到T、L、F。也就是所,方块2在顺序为T、L、F的时候是0号方向,我们模仿1号方块,认为顺序L、F、T为1号方向,F、T、L为2号。同理可以知道T面的其他角。
由于F2旋转是不活改变角的方向,所以我们进行F2旋转,此时方块2旋转至F、D、R的交接面处,暂称为位置3。此时T、L、F面的方向为D、R、F,所以我们认为方块3的0号方向顺序为D、R、F。同理可以知道D面的其他角。
通过这种建模方式,可以模仿上面说道的魔方的这些优良性质,保证搜索算法和映射表的成立。
3、硬件设计框图

4、软件设计框架

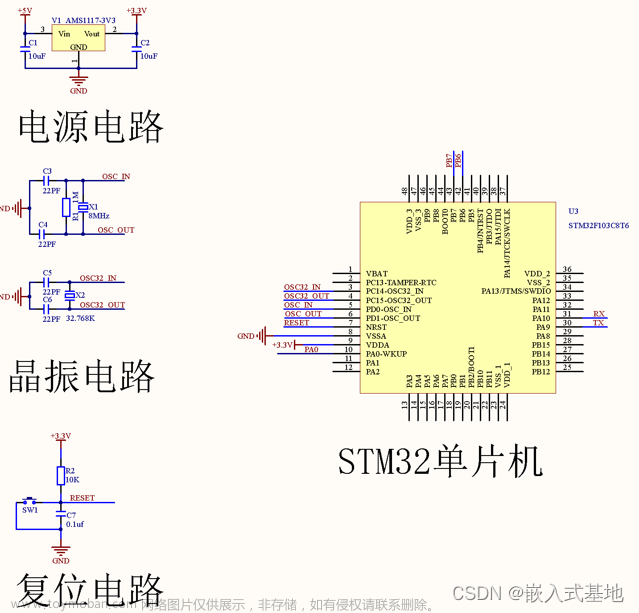
5、原理图


6、工程设计图纸

8、全部资料

9、资料获取文章来源:https://www.toymoban.com/news/detail-767254.html
关注我后,在后台回复关键字。
文章来源地址https://www.toymoban.com/news/detail-767254.html
到了这里,关于【毕业设计】基于STM32的解魔方机器人的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[毕业设计] 基于单片机的智能快递柜设计与实现 - stm32 物联网](https://imgs.yssmx.com/Uploads/2024/02/794821-1.png)





