【大家好,我是爱干饭的猿,本文重点介绍、SparkSQL的运行流程、 SparkSQL的自动优化、Catalyst优化器、SparkSQL的执行流程、Spark On Hive原理配置、分布式SQL执行引擎概念、代码JDBC连接。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【SparkSQL】SparkSQL函数定义(重点:定义UDF函数、使用窗口函数)》
5. SparkSQL的运行流程
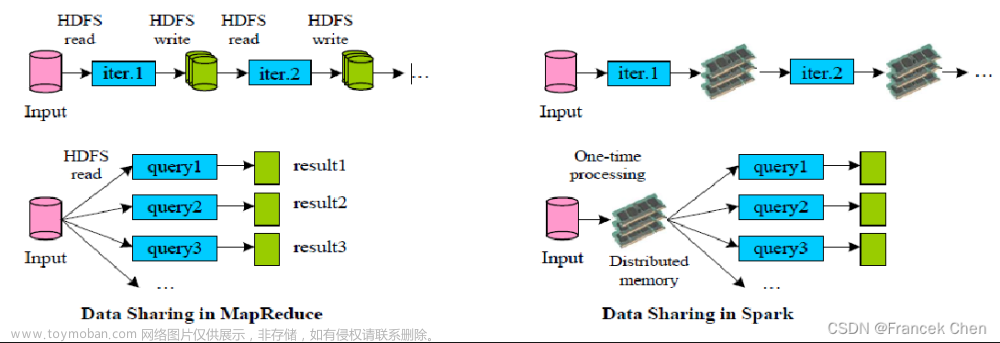
5.1 SparkRDD的执行流程回顾

代码->DAG调度器逻辑任务->Task调度器任务分配和管理监控-> Worker干活
5.2 SparkSQL的自动优化
RDD的运行会完全按照开发者的代码执行, 如果开发者水平有限,RDD的执行效率也会受到影响。
而SparkSQL会对写完的代码,执行“自动优化”, 以提升代码运行效率,避免开发者水平影响到代码执行效率。
问:为什么SparkSQL可以自动优化而RDD不可以?
RDD:内含数据类型不限格式和结构
DataFrame:100% 是二维表结构,可以被针对SparkSQL的自动优化,依赖于:Catalyst优化器
5.3 Catalyst优化器
为了解决过多依赖Hive 的问题, SparkSQL使用了一个新的SQL优化器替代 Hive 中的优化器,这个优化器就是Catalyst,整个SparkSQL的架构大致如下:
- API层简单的说就是Spark会通过一些API接受SQL语句
- 收到SQL语句以后,将其交给Catalyst, Catalyst负责解析SQL,生成执行计划等
- Catalyst的输出应该是RDD的执行计划
- 最终交由集群运行
具体流程:
step1:解析SQL,并且生成AST(抽象语法树)
Step 2:在AST中加入元数据信息做这一步主要是为了一些优化。例如 col = col这样的条件,下图是一个简略图,便于理解
- score.id →id#1#L为score.id生成id为1,类型是Long
- score.math_score → math_score#2#L为score.math_score 生成id为2,类型为Long
- people.id → id#3#L为people.id生成 id为3,类型为Long
- people.age →age#4#L为people.age 生成 id为4,类型为Long
Step 3:对已经加入元数据的AST,输入优化器,进行优化,从两种常见的优化开始,简单介绍:
- 断言下推 Predicate Pushdown,将Filter这种可以减小数据集的操作下推,放在Scan 的位置,这样可以减少操作时候的数据量。断言下推后,会先过滤age,然后在JOIN,减少JOIN的数据量提高性能.
- 列值裁剪Column Pruning,在断言下推后执行裁剪,由于people表之上的操作只用到了 id 列,所以可以把其它列裁剪掉,这样可以减少处理的数据量,从而优化处理速度
Step 4:上面的过程生成的AST其实最终还没办法直接运行,这个AST叫做逻辑计划,结束后,需要生成.物理计划,从而生成RDD来运行
- 在生成
物理计划的时候,会经过成本模型对整棵树再次执行优化,选择一个更好的计划 - 在生成
物理计划以后,因为考虑到性能,所以会使用代码生成,在机器中运行
可以使用queryExecution方法查看逻辑执行计划,使用explain方法查看物理执行计划:
小结:
catalyst的各种优化细节非常多,大方面的优化点有2个:
- 谓词下推(Predicate Pushdown)\断言下推:将逻辑判断提前到前面,以减少shuffle阶段的数据量
- 列值裁剪(Column Pruning):将加载的列进行裁剪,尽量减少被处理数据的|宽度
大白话:
- 行过滤,提前执行where
- 列过滤,提前规划select的字段数量
思考:列值裁剪,有一种非常合适的存储系统: parquet
5.4 SparkSQL的执行流程

- 提交SparkSQL代码
- catalyst优化
a. 生成原始AST语法数
b.标记AST元数据
c.进行断言下推和列值裁剪以及其它方面的优化作用在AST上
d.将最终AST得到,生成执行计划
e.将执行计划翻译为RDD代码 - Driver执行环境入口构建(SparkSession)
- DAG调度器规划逻辑任务
- TASK调度区分配逻辑任务到具体Executor上工作并监控管理任务
- Worker干活.
5.5 总结
- DataFrame因为存储的是二维表数据结构,可以被针对,所以可以
自动优化执行流程。 - 自动优化依赖Catalyst优化器
- 自动优化2个大的优化项是:1. 断言(谓词)下推(行过滤) 2. 列
值裁剪(列过滤) - DataFrame代码在被优化有,最终还是被转换成RDD去执行
6 Spark On Hive
6.1 原理
- 回顾Hive的组件
对于Hive来说,就2东西:
- SQL优化翻译器(执行引擎),翻译SQL到MapReduce并提交到YARN执行
- MetaStore元数据管理中心
- Spark On Hive
对于Spark来说,自身是一个执行引擎,但是 Spark自己没有元数据管理功能,当我们执行:
SELECT * FROM person WHERE age > 10的时候,Spark完全有能力将SQL变成RDD提交
但是问题是, Person的数据在哪? Person有哪些字段?字段啥类型? Spark完全不知道了
不知道这些东西,如何翻译RDD运行
在SparkSQL代码中可以写SQL那是因为,表是来自DataFrame注册的,DataFrame中有数据,有字段,有类型,足够Spark用来翻译RDD用
如果以不写代码的角度来看,SELECT * FROM person WHERE age > 10 spark无法翻译,因为没有元数据
- 解决方案
Spark提供执行引擎能力
Hive的MetaStore 提供元数据管理功能.
让Spark和Metastore连接起来,那么:
Spark On Hive 就有了:
- 引擎: spark
- 元数据管理: metastore
总结:
Spark On Hive 就是把Hive的MetaStore服务拿过来给Spark做元数据管理用而已.
市面上元数据管理的框架很多,为什么非要用Hive内置的MetaStore
6.2 配置
根据原理,就是Spark能够连接上Hive的MetaStore就可以了.
所以:
- MetaStore需要存在并开机
- Spark知道MetaStore在哪里( IP端口号)
步骤1:
在spark的conf目录中,创建hive-site.xml
步骤2:
将mysql的驱动jar包放入spark的jars目录
因为要连接元数据,会有部分功能连接到mysql库,需要mysql驱动包
步骤3:
确保Hive 配置了MetaStore相关的服务
检查hive配置文件目录内的: hive-site.xml
确保有如下配置:
步骤4:
启动hive的MetaStore服务:
nohup :后台启动程序的命令,使用
nohup xxx命令&将命令后台执行,日志输出到当前目录的nohup.out中
nohup xxx命令 2>&1>>某路径下的日志文件&,将命令后台执行,将日志输出到你指定的路径中
测试:
bin/pyspark:在里面直接写spark.sql(“sql语句”).show()即可
或者:
bin/spark-sql:可以直接写sql语句
6.3 在代码中集成
# coding:utf8
import string
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse").\
config("hive.metastore.uris", "thrift://node3:9083").\
enableHiveSupport().\
getOrCreate()
sc = spark.sparkContext
spark.sql("SELECT * FROM student").show()
6.4 总结
Spark On Hive 就是因为Spark自身没有元数据管理功能, 所以使用
Hive的Metastore服务作为元数据管理服务。计算由Spark执行。
7. 分布式SQL执行引擎
7.1 概念
Spark中有一个服务叫做: ThriftServer服务,可以启动并监听在10000端口
这个服务对外提供功能,我们可以用数据库工具或者代码连接上来直接写SQL即可操作spark
当使用ThriftServer后,相当于是一个持续性的Spark On Hive集成模式.它提供10000端口,持续对外提供服务,外部可以通过这个端口连接上来, 写SQL, 让Spark运行
7.2 客户端工具连接
1.确保已经配置好了Spark On Hive
2.启动ThriftServer即可
7.3 代码JDBC连接

# coding:utf8
from pyhive import hive
if __name__ == '__main__':
# 获取到Hive(Spark ThriftServer的链接)
conn = hive.Connection(host="node1", port=10000, username="hadoop")
# 获取一个游标对象
cursor = conn.cursor()
# 执行SQL
cursor.execute("SELECT * FROM student")
# 通过fetchall API 获得返回值
result = cursor.fetchall()
print(result)
7.4 总结
分布式SQL执行引擎就是使用Spark提供的ThriftServer服务,以“后台进程”的模式持续运行,对外提供端口。
可以通过客户端工具或者代码,以JDBC协议连接使用。文章来源:https://www.toymoban.com/news/detail-767278.html
SQL提交后,底层运行的就是Spark任务。相当于构建了一个以MetaStore服务为元数据,Spark为执行引擎的数据库服务,像操作数据库那样方便的操作SparkSQL进行分布式的SQL
计算。文章来源地址https://www.toymoban.com/news/detail-767278.html
到了这里,关于【SparkSQL】SparkSQL的运行流程 & Spark On Hive & 分布式SQL执行引擎的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!