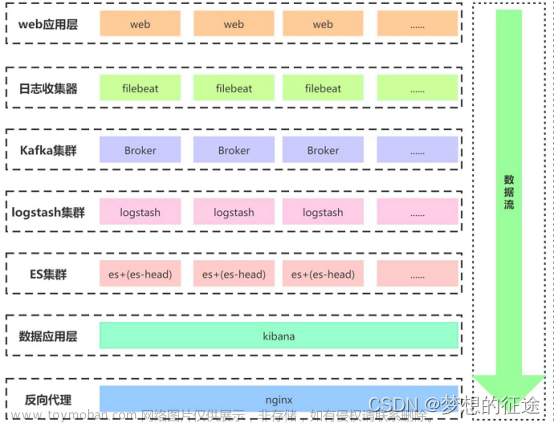
一、背景
首先,要说明一点,elk日志中心,是可以缺少kafka组件的。
其次,如果是研发环境下,机器资源紧张的情况下,也是可不部署kafka。
最后,因为kafka的部署是可以独立的,所以本文将另行部署,不和elk一起。
二、目标
1、数据的可视化
2、数据的治理
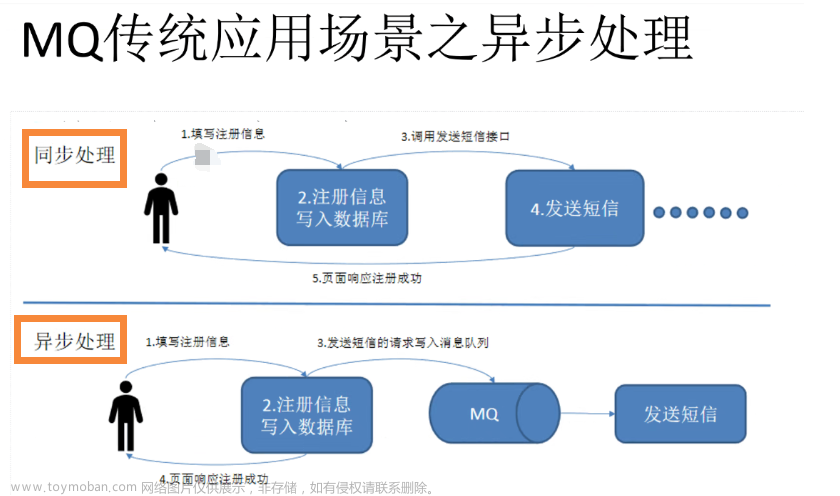
3、对采集数据进行削峰填谷
三、部署
1、三节点的kafka集群
本机的IP地址是192.168.8.29,请你修改为自己的IP
version: "3"
services:
# kafka集群
kafka1:
image: bitnami/kafka:3.3.1
container_name: kafka1
user: root
ports:
- 9192:9092
- 9193:9093
environment:
### 通用配置
# 允许使用kraft,即Kafka替代Zookeeper
- KAFKA_ENABLE_KRAFT=yes
# kafka角色,做broker,也要做controller
- KAFKA_CFG_PROCESS_ROLES=broker,controller
# 指定供外部使用的控制类请求信息
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# 定义kafka服务端socket监听端口
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
# 定义安全协议
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
# 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
- KAFKA_KRAFT_CLUSTER_ID=LelM2dIFQkiUFvXCEcqRWA
# 集群地址
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
# 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
- ALLOW_PLAINTEXT_LISTENER=yes
# 设置broker最大内存,和初始内存
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
# 允许自动创建主题
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
# 消息保留时长(毫秒),保留7天
- KAFKA_LOG_RETENTION_MS=604800000
### broker配置
# 定义外网访问地址(宿主机ip地址和端口)
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.8.29:9192
# broker.id,必须唯一
- KAFKA_BROKER_ID=1
volumes:
- ./data/kafka1:/bitnami/kafka
kafka2:
image: bitnami/kafka:3.3.1
container_name: kafka2
user: root
ports:
- 9292:9092
- 9293:9093
environment:
### 通用配置
# 允许使用kraft,即Kafka替代Zookeeper
- KAFKA_ENABLE_KRAFT=yes
# kafka角色,做broker,也要做controller
- KAFKA_CFG_PROCESS_ROLES=broker,controller
# 指定供外部使用的控制类请求信息
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# 定义kafka服务端socket监听端口
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
# 定义安全协议
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
# 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
- KAFKA_KRAFT_CLUSTER_ID=LelM2dIFQkiUFvXCEcqRWA
# 集群地址
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
# 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
- ALLOW_PLAINTEXT_LISTENER=yes
# 设置broker最大内存,和初始内存
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
# 允许自动创建主题
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
# 消息保留时长(毫秒),保留7天
- KAFKA_LOG_RETENTION_MS=604800000
### broker配置
# 定义外网访问地址(宿主机ip地址和端口)
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.8.29:9292
# broker.id,必须唯一
- KAFKA_BROKER_ID=2
volumes:
- ./data/kafka2:/bitnami/kafka
kafka3:
image: bitnami/kafka:3.3.1
container_name: kafka3
user: root
ports:
- 9392:9092
- 9393:9093
environment:
### 通用配置
# 允许使用kraft,即Kafka替代Zookeeper
- KAFKA_ENABLE_KRAFT=yes
# kafka角色,做broker,也要做controller
- KAFKA_CFG_PROCESS_ROLES=broker,controller
# 指定供外部使用的控制类请求信息
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# 定义kafka服务端socket监听端口
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
# 定义安全协议
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
# 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
- KAFKA_KRAFT_CLUSTER_ID=LelM2dIFQkiUFvXCEcqRWA
# 集群地址
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
# 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
- ALLOW_PLAINTEXT_LISTENER=yes
# 设置broker最大内存,和初始内存
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
# 允许自动创建主题
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
# 消息保留时长(毫秒),保留7天
- KAFKA_LOG_RETENTION_MS=604800000
### broker配置
# 定义外网访问地址(宿主机ip地址和端口)
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.8.29:9392
# broker.id,必须唯一
- KAFKA_BROKER_ID=3
volumes:
- ./data/kafka3:/bitnami/kafka
2、kafka ui
本机的IP地址是192.168.8.29,请你修改为自己的IP
如果你要安装,请追加以下容器。
#kafka可视化工具
kafka-ui:
container_name: kafka-ui
image: provectuslabs/kafka-ui:latest
ports:
- 8989:8080
depends_on:
- kafka1
- kafka2
- kafka3
environment:
- KAFKA_CLUSTERS_0_NAME=kafkaCluster
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=192.168.8.29:9192,192.168.8.29:9292,192.168.8.29:9392
- DYNAMIC_CONFIG_ENABLED=true
四、配置说明
1、开启使用kraft,即kafka替代Zookeeper。
2、data数据持久化到相对路径下。
3、允许自动创建kafka主题
# 允许自动创建主题
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
4、设置kafka消息的保留有效期
# 消息保留时长(毫秒),保留7天
- KAFKA_LOG_RETENTION_MS=604800000
5、broker的jvm配置
# 设置broker最大内存,和初始内存
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
6、注意版本兼容,镜像使用bitnami/kafka:3.3.1文章来源:https://www.toymoban.com/news/detail-767292.html
五、修改filebeat.yml的output
#output.logstash:
# enabled: true
# hosts: ["logstash:5044"]
output.kafka:
enabled: true
hosts: ["192.168.8.29:9192","192.168.8.29:9292","192.168.8.29:9392"]
topic: jvmlog
partition.round_robin:
reachable_only: true
required_acks: 1 # 本地写入完成
compression: gzip # 开启压缩
max_message_bytes: 1000000 # 消息最大值
六、修改logstash的input
input {
#beats {
# port => 5044
#}
kafka {
codec => plain{charset => "UTF-8"}
bootstrap_servers => "192.168.8.29:9192"
consumer_threads => 5
auto_offset_reset => "latest"
decorate_events => true
topics => "jvmlog"
}
}
七、kafka ui
访问地址:http://192.168.8.29:8989/ui
由于是自动创建kafka的topic,不用手动创建。
点击topic主题“jvmlog”,查看消息列表Messages: 文章来源地址https://www.toymoban.com/news/detail-767292.html
文章来源地址https://www.toymoban.com/news/detail-767292.html
到了这里,关于私有部署ELK,搭建自己的日志中心(六)-- 引入kafka对采集日志进行削峰填谷的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!