Storm与Spark、Hadoop三种框架对比
Storm与Spark、Hadoop这三种框架,各有各的优点,每个框架都有自己的最佳应用场景。所以,在不同的应用场景下,应该选择不同的框架。
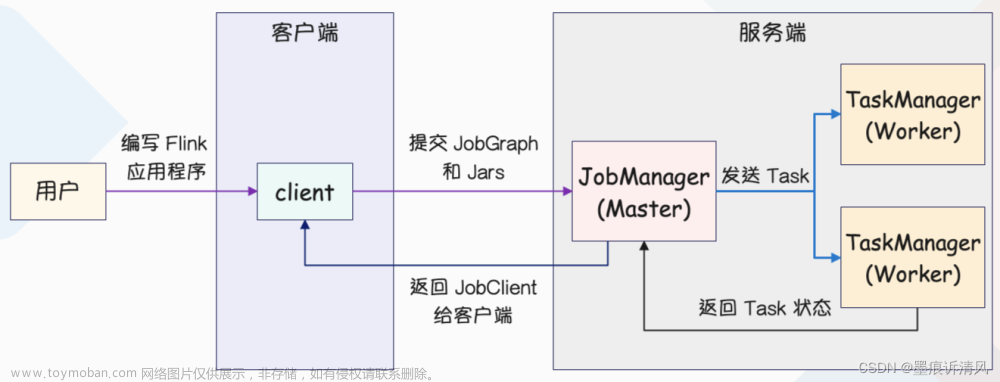
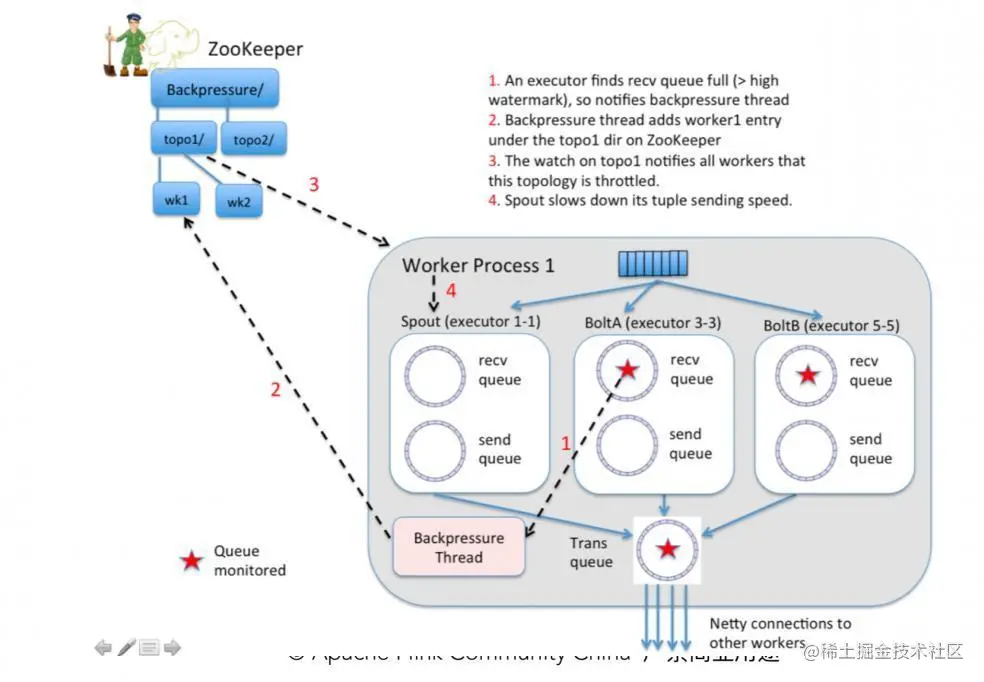
1.Storm是最佳的流式计算框架,Storm由Java和Clojure写成,Storm的优点是全内存计算,所以它的定位是分布式实时计算系统,按照Storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。
Storm的适用场景:
1)流数据处理
Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去。
2)分布式RPC。由于Storm的处理组件是分布式的,而且处理延迟极低,所以可以作为一个通用的分布式RPC框架来使用。
2.Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析。Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发,类似于Hadoop MapReduce的通用并行计算框架,Spark基于Map Reduce算法实现的分布式计算, 拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的Map Reduce的算法。
Spark的适用场景:
1)多次操作特定数据集的应用场合
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小。
2)粗粒度更新状态的应用
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如Web服务的存储或者是增量的Web爬虫和索引。就是对于那种增量修改的应用模型不适合。
总的来说Spark的适用面比较广泛且比较通用。
3.Hadoop是实现了MapReduce的思想,将数据切片计算来处理大量的离线数据。Hadoop处理的数据必须是已经存放在HDFS上或者类似HBase的数据库中,所以Hadoop实现的时候是通过移动计算到这些存放数据的机器上来提高效率。
Hadoop的适用场景:
1)海量数据的离线分析处理
2)大规模Web信息搜索
3)数据密集型并行计算
简单来说:
Hadoop适合于离线的批量数据处理适用于对实时性要求极低的场景
Storm适合于实时流数据处理,实时性方面做得极好
Spark是内存分布式计算框架,试图吞并Hadoop的Map-Reduce批处理框架和Storm的流处理框架,但是Spark已经做得很不错了,批处理方面性能优于Map-Reduce,但是流处理目前还是弱于Storm,产品仍在改进之中


相信看到这里,大家应该对Hadoop、Storm和Spark的学习内容及路线有了一定认识,那现在是不是需要一份学习Storm和Spark的宝典了呢?
有需要此份文档进行学习的朋友,麻烦三连支持一下,然后点击文末下方传送门,即可获得免费领取方式!无套路的真诚分享!文章来源地址https://www.toymoban.com/news/detail-767626.html
主要结构
本篇结合真实的大数据用例,为读者提供了快速设计、实施和部署实时分析所需的技巧,主要涉及以下内容:
- 探讨大数据技术和框架。
- 比照实时分析与批量分析的应用情景,应对大数据实践所面临的挑战。
- 采用Apache Storm的编程范式开发处理、分析实时数据的现实应用。
- 接受处理实时事务性数据。
- 针对不同任务和产品部署情况,优化Apache Storm实现。
- 使用Amazon Kinesis和Elastic MapReduce进行数据的处理和流传递。
- 使用Spark SQL进行交互式、探索式的数据分析。
- 应用Spark Streaming进行实时分析。
- 为实时和批量分析开发通用型的企业架构和应用。
整体预览
本篇根据业务应用需求选用恰当的技术平台,既涵盖了不同实时数据处理框架和技术的基础知识,又论述了大数据批量及实时处理的差异化细节,还深入探讨了使用Storm、Spark 进行大数据处理的技术和程序设计概念。
以丰富的应用场景及范例说明如何利用Storm 进行实时大数据分析,既涉及了Storm的组件及关键概念内部实现的基础,又整合了Kafka来处理实时事务性数据,还探讨了Storm微小批处理抽象延伸的Trident框架和性能优化。此外,包括了使用Kinesis服务在亚马逊云上处理流数据的内容。本篇后半部分着重介绍了如何利用Spark为实时和批量分析开发通用型的企业架构和应用,既可通过RDD编程轻松实现数据转换和保存操作,亦介绍了Spark SQL访问数据库的实践案例,还扩展了Spark Streaming 来分析流数据,最后利用Spark Streaming和Spark批处理等实现了实时批处理兼顾的Lambda架构。
第1章:大数据技术前景及分析平台

本章探讨了大数据技术领域的各个方面。已经讨论过大数据环境中所使用的主要术语、定义、缩略语、组件和基础设施,还描述了大数据分析平台的架构。此外,还从顺序处理到批处理,到分布式,再到实时处理探讨了大数据的各种进深计算方法。在本章结尾,相信大家者现在已经熟悉了大数据及其特点。
第2章:熟悉Storm

本章涉及不少Storm及其历史沿革等方面内容,介绍了Storm的组件以及Storm某些关键概念的内部实现。其中浏览分析了实际的代码,现在希望大家可以搭建Storm(本地版和集群版)并运行Storm,编程部分基本范例。
第3章:用Storm处理数据

本章重点在于让读者熟悉Kafka及其基础知识。此外,还整合了Kafka和Storm,探索了Storm的文件和套接字等其他数据源,然后介绍了可靠性和锚定等概念,还对Storm的联结和批处理模式建立了理解。最后,通过Storm与数据库的集成,了解并实现了Storm中的持久性。本章介绍了一些动手练习示例,建议大家自行尝试实现。
第4章:Trident概述和Storm性能优化

本章重点在于让大家熟悉Trident框架,以其作为Storm微小批处理抽象的延伸。我们已经看到了Trident 的各种关键概念和操作,然后还探索了Storm 内部与LMAX、ZeroMQ和Netty的联系。最后总结了Storm 性能优化方面的内容。
第5章:熟悉Kinesis

在本章中,讨论了Kinesis用于处理实时数据馈送的架构。使用AWSAPI探索了Kinesis流生产者和消费者的开发。最后,还提到诸如KPL和KCL此类更高级的API以及它们的示例,来作为创建Kinesis生产者和消费者的推荐机制。
第6章:熟悉Spark

在本章中,讨论了Spark及其各种组件的架构,还谈到了Spark框架的一些核心组件,如RDD。此外,讨论了Spark 及其各种核心API的包装结构,还配置了Spark 集群,并用Scala和Java编写并执行了第一个Spark作业。
第7章:使用RDD编程

在本章中,讨论了SparkRDDAPI提供的各种转换及操作,还讨论了各种现实问题,并通过使用Spark转换及操作来解决它们。最后,还讨论了Spark提供的用于性能优化的持久性/高速缓存。
第8章:Spark的SQL查询引擎一Spark SQL

本章涵盖了Spark SQL架构和各种组件在内的多个方面,还讨论了在Scala中编写Spark SQL作业的完整过程,同时讨论了将Spark RDD转换为DataFrame的各种方法。在本章的中间部分,执行了Spark SQL的各种示例,包括使用如Hive/Parquet这些不同数据格式以及如模式演化和模式合并等重要方面,最后讨论了Spark SQL代码/查询的性能调优的各个方面。
第9章:用Spark Streaming分析流数据

在本章中,讨论了Spark Streaming的各个方面。讨论了Spark Streaming的架构、组件和封装结构,还编码和执行了第一个Spark Streaming应用程序,也使用Spark Streaming和SparkSQL对芝加哥犯罪数据进行了实时分析。
第10章:介绍Lambda架构

在本章中讨论了Lambda架构的各个方面。讨论了Lambda架构的各个层/组件所执行的角色,还利用Spark和Cassandra来设计、开发和执行了Lambda架构的所有层。文章来源:https://www.toymoban.com/news/detail-767626.html
有需要此份文档进行学习的朋友,麻烦三连支持一下,然后点击文末下方传送门,即可获得免费领取方式!无套路的真诚分享!
到了这里,关于大数据技术学习之Storm、Spark学习手册,这还不码住学起来的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!