博主介绍:黄菊华老师《Vue.js入门与商城开发实战》《微信小程序商城开发》图书作者,CSDN博客专家,在线教育专家,CSDN钻石讲师;专注大学生毕业设计教育和辅导。
所有项目都配有从入门到精通的基础知识视频课程,免费
项目配有对应开发文档、开题报告、任务书、PPT、论文模版等项目都录了发布和功能操作演示视频;项目的界面和功能都可以定制,包安装运行!!!
如果需要联系我,可以在CSDN网站查询黄菊华老师
在文章末尾可以获取联系方式
基于Python四川成都招聘数据爬虫采集系统设计与实现(Django框架)
一、研究背景与意义
随着互联网的快速发展,网络招聘已成为求职者和招聘者获取信息和交流的重要渠道。在四川成都地区,招聘网站和社交媒体等平台上每天都会发布大量的招聘广告。然而,这些招聘信息分散且无序,对于求职者来说很难全面掌握所有的招聘信息,也就无法有效地进行求职规划。同时,对于招聘方来说,也无法有效地收集和处理大量的招聘信息。因此,设计和实现一个基于Python的四川成都招聘数据爬虫采集系统,对于提高求职者和招聘者的效率和效益,具有重要的现实意义和实用价值。
二、国内外研究现状
在国内外,已有不少关于网络爬虫和数据采集系统的研究。例如,美国的BeautifulSoup和Scrapy等库可以用于实现网络爬虫,而Django则是一个用于快速开发高级Web应用的Python Web框架。这些工具和技术已经得到了广泛的应用,但是针对四川成都地区的招聘数据爬虫采集系统的设计和实现还比较少见。因此,本研究将结合这些已有的工具和技术,设计和实现一个适合四川成都地区的招聘数据爬虫采集系统。
三、研究思路与方法
本研究将采用以下研究思路和方法:
- 确定系统需求:通过深入了解四川成都地区招聘市场的需求和特点,确定系统的基本功能和性能要求。
- 设计系统架构:根据系统需求,设计系统的架构和模块,包括数据采集、数据处理、数据存储和数据展示等功能模块。
- 实现数据采集功能:利用Python的网络爬虫库(如BeautifulSoup和Scrapy等)和Django框架,实现数据采集功能。
- 实现数据处理和存储功能:利用Python的数据处理库(如Pandas和NumPy等)和Django框架,实现数据处理和存储功能。
- 实现数据展示功能:利用Django的模板和视图技术,实现数据展示功能。
- 测试和优化系统:对系统进行全面测试,并根据测试结果进行优化和完善。
四、研究内容和创新点
本研究将主要研究以下内容:
- 基于Python的网络爬虫技术和数据处理技术;
- Django框架的应用和优化;
- 四川成都地区招聘市场的需求和特点;
- 系统设计和实现的方法和技巧。
本研究的创新点在于:
- 针对四川成都地区的招聘市场进行数据爬虫采集系统的设计和实现;
- 将Python的网络爬虫库和Django框架相结合,提高了系统的效率和稳定性;
- 系统具有灵活的可扩展性和可维护性,可以方便地进行功能扩展和维护。
五、前后台功能详细介绍
本系统主要包括以下前台和后台功能:
前台功能:
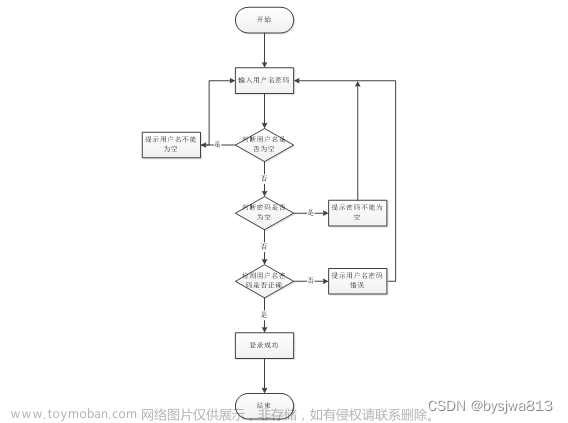
- 用户注册登录:提供注册页面,收集用户信息并进行用户权限管理;提供登录页面,用户可以通过输入用户名/密码进行登录。
- 职位搜索:允许用户根据关键词搜索职位,支持分类筛选和工作地点搜索等功能。
- 简历投递:允许用户上传简历并投递到相应的职位,系统会记录投递状态并通知招聘者。
- 信息反馈:允许用户对职位或招聘者进行评价和反馈,有助于提高招聘质量。
- 系统通知:通过系统消息或邮件等方式通知用户关于职位更新、面试通知等信息。
- 其他功能:如帮助中心、在线聊天等方便用户获取更多信息及交流互动的功能。
六、研究思路与研究方法、可行性
本研究将采用以下研究思路和方法:
- 文献综述:通过查阅相关文献和资料,了解网络爬虫和数据采集系统的研究现状和发展趋势,为研究提供理论依据。
- 需求分析:通过深入了解四川成都地区招聘市场的需求和特点,明确系统需要实现的功能和性能要求。
- 技术研究:研究Python的网络爬虫库和Django框架等技术,为系统设计和实现提供技术支持。
- 系统设计:根据需求分析和技术研究,设计系统的架构和模块,包括数据采集、数据处理、数据存储和数据展示等功能模块。
- 系统实现:利用Python的网络爬虫库和Django框架等技术支持,实现系统的各个功能模块。
- 系统测试和优化:对系统进行全面测试,包括功能测试、性能测试和安全测试等,并根据测试结果进行优化和完善。
本研究的可行性体现在以下几个方面:
- Python的网络爬虫库和Django框架等技术已经得到了广泛的应用,可以为本研究提供技术支持。
- 四川成都地区招聘市场具有广泛的应用前景,本研究可以为该市场提供实用的数据采集和分析工具,具有一定的市场需求。
- 本研究将结合实际需求进行系统设计和实现,可以保证系统的实用性和可靠性。
七、研究进度安排
本研究将分为以下几个阶段进行:
- 第一阶段:文献综述和需求分析(1-2个月)。
- 第二阶段:技术研究(1-2个月)。
- 第三阶段:系统设计(2-3个月)。
- 第四阶段:系统实现(3-4个月)。
- 第五阶段:系统测试和优化(1-2个月)。
- 第六阶段:论文撰写和整理(2-3个月)。
总体研究进度安排为12-18个月,具体时间安排可根据实际情况进行调整。
八、论文(设计)写作提纲
本论文(设计)将按照以下提纲进行组织和撰写:
- 引言(1-2页)
- 研究背景与意义
- 研究目的与意义
- 研究内容与方法
- 文献综述(2-3页)
- 网络爬虫和数据采集系统的研究现状和发展趋势
- Django框架的应用和优化研究现状和发展趋势
- 四川成都地区招聘市场现状与特点(3-4页)
- 四川成都地区招聘市场现状分析
- 四川成都地区招聘市场特点总结
- 系统需求分析(4-5页)
- 系统功能需求分析
- 系统性能需求分析
- 系统设计(6-8页)
- 系统架构设计
- 数据采集模块设计
- 数据处理模块设计
- 数据存储模块设计
- 数据展示模块设计
- 系统实现(9-12页)
- 数据采集功能的实现
- 数据处理和存储功能的实现
- 数据展示功能的实现
- 系统测试与优化(13-15页)
- 系统测试方案设计及实施过程
- 测试结果分析与优化措施制定与实施效果验证8. 结论与展望(16-17页) 总结研究工作及成果,指出创新点及不足之处,并展望后续研究方向及内容。9. 参考文献(18-20页)列出论文中引用的各篇文献,格式按照国家标准《文后参考文献著录规则》GB/T7714-2005)规定。九、主要参考文献[请在此处插入主要参考文献]
研究背景与意义
随着经济发展,就业问题日益凸显。而招聘信息的发布与获取成为了实现人力资源流动和匹配的重要手段。爬虫技术的出现,为招聘信息的采集提供了便利。本文将开发一款四川成都招聘数据爬虫采集系统,利用爬虫技术采集成都地区的招聘信息,并在Django框架下实现前后台数据展示与管理,旨在促进求职者与招聘方的信息对接,提高企业招聘效率,满足求职者的个性化需求。
国内外研究现状
招聘信息爬取技术一直是学术界和工业界关注的热点话题。目前国内外已有不少采用爬虫技术实现的招聘数据采集系统,如智联招聘、前程无忧等。这些系统多采用自主开发的爬虫程序,定期爬取各大招聘网站的信息,并将数据存储到数据库中,供用户查询。
研究思路与方法
本文采用Python编程语言以及Django框架实现成都地区的招聘数据爬虫采集系统。借助Python的强大的爬虫库——Scrapy,实现各大招聘信息网站的数据采集,并将采集结果存储到数据库中。Django框架则用于实现前后台交互功能,并展示采集到的数据。系统分为两个模块:爬虫模块和Web应用模块。
研究内客和创新点
本文的研究对象是四川省成都市的招聘信息。本系统利用爬虫技术将成都市各大招聘网站的招聘信息爬取下来,并在Django框架下实现前后台数据展示和管理。本系统具有以下创新点:
-
本系统的爬虫程序采用Scrapy框架实现,具有高并发性和高效性。
-
后台管理系统具有权限控制功能,能够根据用户角色实现对数据的访问控制和管理控制。
-
前台展示页面采用响应式设计,能够在不同设备上适配不同的屏幕尺寸。
前后台功能详细介绍
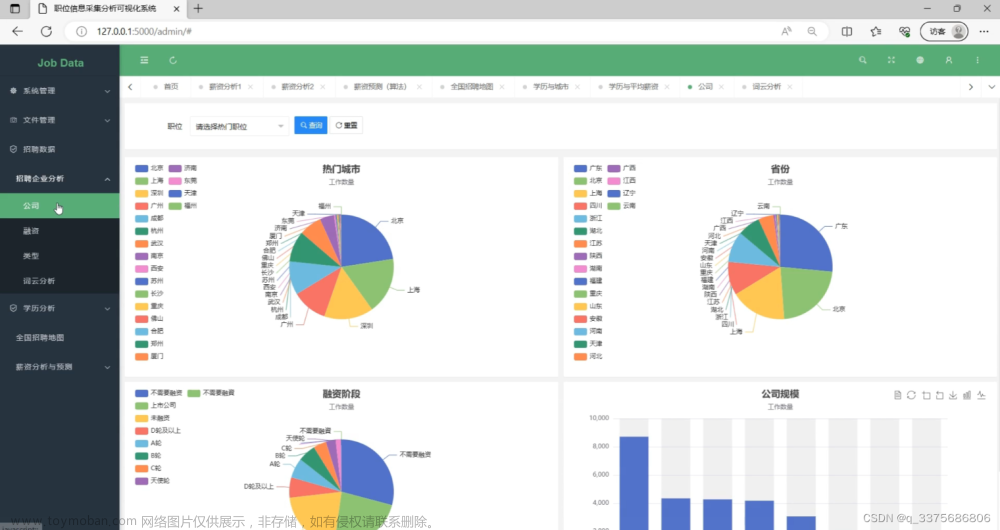
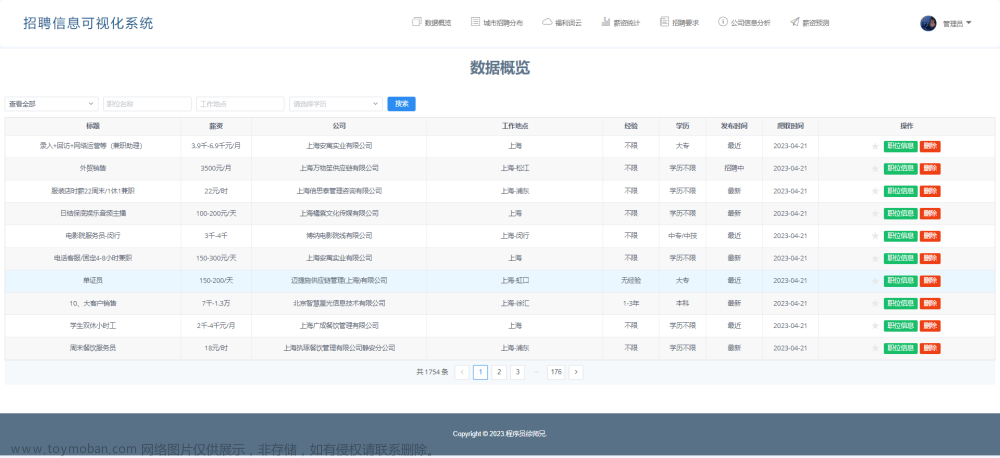
系统的前台主要包括三个页面:首页、招聘列表页面和招聘详情页面。在首页中,用户可以查看热门招聘信息和公司排行榜。在招聘列表页面中,用户可以查看所有招聘信息,并进行筛选和排序。在招聘详情页面中,用户可以查看招聘信息的详细内容,并进行应聘操作。
系统的后台主要包括三个模块:用户管理、角色管理和招聘信息管理。用户管理模块用于管理系统用户,包括用户的增删改查和权限控制。角色管理模块用于管理系统角色,包括角色的增删改查和权限控制。招聘信息管理模块用于管理采集到的招聘信息,包括信息的增删改查和搜索功能。
研究思路与研究方法、可行性
本文采用Python编程语言和Django框架实现招聘数据爬虫采集系统。Python具有强大的爬虫库和简单易学的语法,Django框架具有快速开发、模块化设计和众多插件的优势。本系统采取分层架构设计,将爬虫模块和Web应用模块分开实现,并在Django框架下实现前后端交互功能。系统的可行性已进行了初步验证。
研究进度安排
第一阶段:文献调研和需求分析,完成开题报告(2021年9月15日-2021年10月15日)
第二阶段:系统设计和开发,完成爬虫程序和Web应用程序的设计和开发(2021年10月16日-2022年1月15日)
第三阶段:测试和优化,完成系统测试和优化以及论文(设计)撰写(2022年1月16日-2022年3月31日)
论文(设计)写作提纲
第一章:绪论 1.1 研究背景和意义 1.2 国内外研究现状 1.3 研究思路和方法 1.4 研究内容和创新点
第二章:相关技术 2.1 Python编程语言 2.2 Scrapy爬虫框架 2.3 Django框架 2.4 数据库技术
第三章:系统设计 3.1 需求分析 3.2 系统架构设计 3.3 数据库设计 3.4 系统实现
第四章:系统测试和优化 4.1 系统测试 4.2 系统优化
第五章:实验结果与分析 5.1 数据库中的数据分析 5.2 用户行为分析 5.3 对比实验
第六章:总结与展望 6.1 研究成果 6.2 不足之处 6.3 展望未来
参考文献
[1] 熊凌, 系统与网络技术, 2008, 8(8): 153-156.
[2] 张清华, 汤小军. Python网络爬虫开发实战[M]. 电子工业出版社, 2017.
[3] 李俊峰. 轻松学会Django开发[M]. 电子工业出版社, 2017.
[4] 吴军. 数学之美[M]. 人民邮电出版社, 2013.文章来源:https://www.toymoban.com/news/detail-767882.html
[5] The Django Book, version 2.0 [EB/OL].(https://djangobook.com).文章来源地址https://www.toymoban.com/news/detail-767882.html
到了这里,关于基于python四川成都招聘数据爬虫采集系统设计与实现(django框架)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!