9月25日,阿里云开源通义千问140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat,免费可商用。
 立马就到了GitHub去fork。
立马就到了GitHub去fork。
GitHub:
GitHub - QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large language model proposed by Alibaba Cloud.
官方的技术资料也下载了,看这里==>https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf
这个模型的表现怎么样?
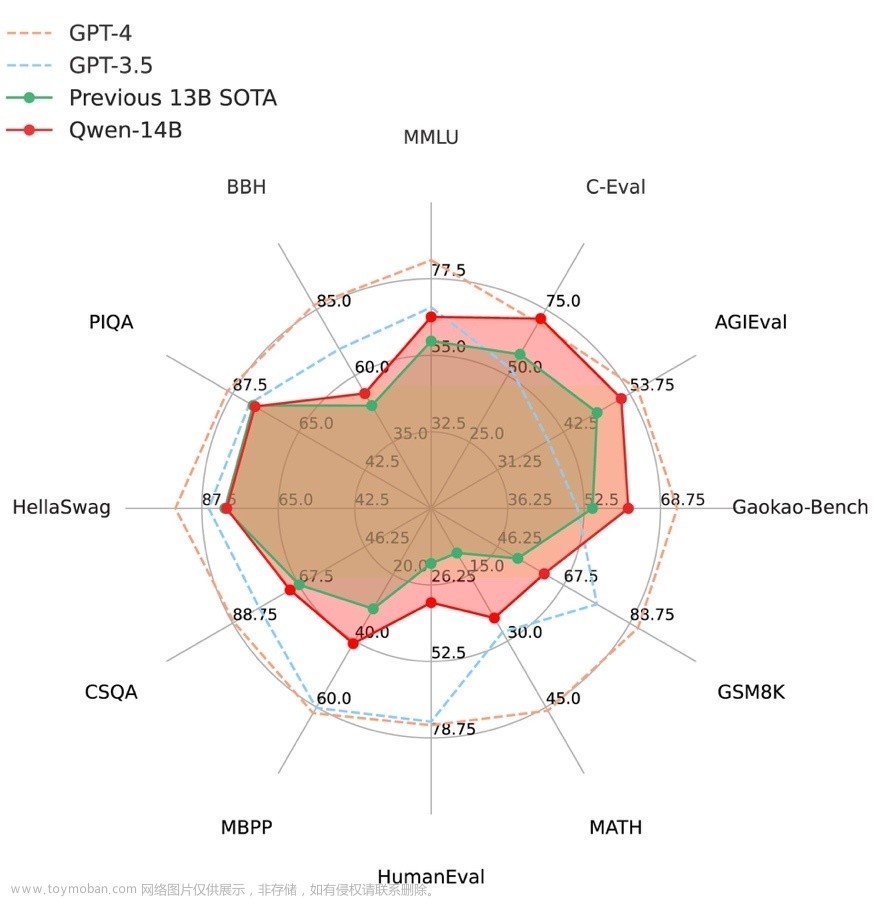
Qwen-14B和Qwen-7B模型相比同规模模型表现更好,其能力包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。虽然Qwen-14B仍与GPT-3.5和GPT-4有差距,但表现不俗。实验结果见表格,更多细节请查看技术备忘录:https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf。


学习或调试大模型需要【安装哪些软件】?
- python 3.8及以上版本
- pytorch 1.12及以上版本,推荐2.0及以上版本
- 建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
【安装pytorch】 传送门==>pytorch 下载安装全流程详细教程_pytorch官网下载教程_Deep Learning小舟的博客-CSDN博客
该装的都装好了?好的,上车吧!
快!快告诉我【如何使用】大模型!
提供简单的示例来说明如何利用🤖 ModelScope和🤗 Transformers快速使用Qwen-7B和Qwen-7B-Chat。
ModelScope是一个开源平台,允许用户在生产中可视化、监视和分析机器学习模型。
看这里==>https://github.com/modelscope/modelscope
依赖库的安装
看看都需要安装哪些依赖库。在工程中有一个文件叫做requirements.txt,打开

【transformers】
Transformers提供API和工具,方便下载和训练最先进的预训练模型。使用预训练模型可以降低计算成本、碳足迹,并节省训练模型所需的时间和资源。这些模型支持不同类型的常见任务,例如:
📝 自然语言处理:文本分类、命名实体识别、问答、语言建模、摘要、翻译、多项选择和文本生成。
🖼️ 计算机视觉:图像分类、目标检测和分割。
🗣️ 音频:自动语音识别和音频分类。
🐙 多模态:表格问答、光学字符识别、从扫描文档中提取信息、视频分类和视觉问答。
传送门==>https://huggingface.co/docs/transformers/index
【accelerate】
Accelerate是一个库,通过添加仅四行代码,使得相同的PyTorch代码可以在任何分布式配置下运行!简而言之,实现规模化的训练和推理变得简单、高效和适应性强。
传送门==>https://huggingface.co/docs/accelerate/index
【tiktoken 】
tiktoken是一个快速的BPE分词器,可与OpenAI的模型配合使用。
传送门==>https://github.com/openai/tiktoken
【einops 】
灵活强大的张量操作,使代码易读且可靠。支持numpy、pytorch、tensorflow、jax等多种框架。
传送门==>einops · PyPI
【transformers-stream-generator】
这是一种基于Huggingface/Transformers的文本生成方法,它返回一个生成器,在推理期间实时流出每个标记。
传送门==>transformers-stream-generator · PyPI
【scipy】
SciPy提供了用于优化、积分、插值、特征值问题、代数方程、微分方程、统计学和许多其他类别问题的算法。
传送门==>SciPy
【安装以上依赖库】,打开cmd,cd到工程目录路径下,输入如下命令行代码
pip install -r requirements.txt安装flash-attention(可选)
什么是flash-attention?
我们看看论文的摘要==>https://arxiv.org/abs/2205.14135
在处理长序列时,Transformer模型既慢又占用大量内存,因为自注意力机制的时间和内存复杂度都与序列长度呈二次关系。近似注意力方法试图通过牺牲模型质量来降低计算复杂度以解决这个问题,但通常并不能实现实际的速度提升。我们认为,缺少的原则是使注意力算法具有IO意识--考虑到GPU内存各级之间的读写。我们提出了FlashAttention,这是一种IO意识的精确注意力算法,它使用切块技术来减少GPU高带宽内存(HBM)和GPU片上SRAM之间的内存读写次数。我们分析了FlashAttention的IO复杂性,结果显示,它比标准注意力机制需要更少的HBM访问,并且对于一定范围的SRAM大小是最优的。我们还将FlashAttention扩展到了块稀疏注意力,从而得到了一种比现有任何近似注意力方法都更快的近似注意力算法。FlashAttention比现有基线训练Transformer更快:与MLPerf 1.1训练速度记录相比,在BERT-large(序列长度512)上实现了15%的端到端实际速度提升,在GPT-2(序列长度1K)上实现了3倍的速度提升,在长距离竞技场(序列长度1K-4K)上实现了2.4倍的速度提升。FlashAttention和块稀疏FlashAttention使Transformer能够处理更长的上下文,从而产生更高质量的模型(在GPT-2上提高了0.7的困惑度,在长文档分类上提高了6.4个百分点)并且具有全新的能力:它是首个在Path-X挑战(序列长度16K,准确率61.4%)和Path-256(序列长度64K,准确率63.1%)上实现超过偶然性表现的Transformer。
什么是注意力算法?
自注意机制:一种允许神经网络根据它们相互关联的重要性来权衡输入序列的不同部分的机制,而不依赖于固定的窗口大小或卷积操作。
那么注意力算法就是...
近似注意力方法:旨在通过近似注意力权重来减少Transformer模型中自注意力机制的计算和内存需求的方法。
(姑且认为自己懂了吧 )

如果你的显卡支持fp16或bf16精度,我们还推荐安装flash-attention来提高你的运行效率以及降低显存占用。(flash-attention只是可选项,不安装也可正常运行该项目)
显卡支持 fp16 或 bf16 精度
其中 fp16 是指半精度浮点数,它的存储空间只有单精度浮点数的一半,但表示的数值范围和精度较小;bf16 是指bfloat16,它是一种浮点数格式,它可以在减少数据大小的同时保留可用于深度学习等任务的有效位数。这些精度通常用于深度学习等应用,可以提高计算效率和降低内存占用。
安装指令如下
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# 下方安装可选,安装可能比较缓慢。
# pip install csrc/layer_norm
# pip install csrc/rotary安装问题:在使用pip install . 进行安装时,提示“RuntimeError: flash_attn was requested, but nvcc was not found. Are you sure your environment has nvcc available? If you're installing within a container from https://hub.docker.com/r/pytorch/pytorch, only images whose names contain 'devel' will provide nvcc.”
nvcc是什么东东?
`nvcc` 是 NVIDIA CUDA 编译器的命令行工具。CUDA 是一种由 NVIDIA 开发的并行计算平台和应用程序编程接口,用于利用 NVIDIA GPU(图形处理单元)的计算能力来加速各种计算任务,特别是科学计算和深度学习等高性能计算任务。
`nvcc` 允许开发者编译和构建使用 CUDA 编写的程序。它可以处理包含 CUDA C/C++ 代码的源文件,并将其编译成可以在 NVIDIA GPU 上运行的可执行文件。CUDA C/C++ 是一种扩展了标准 C/C++ 语言的编程语言,允许开发者编写能够在 GPU 上并行执行的代码。
使用 `nvcc`,开发者可以指定编译器选项、链接库和其他配置来构建 CUDA 程序。这使得开发者能够充分利用 GPU 的并行性能,加速各种计算任务,包括图形处理、科学计算、深度学习神经网络训练等。
通常,开发者会在命令行中使用 `nvcc` 来编译和构建他们的 CUDA 项目,类似于以下方式:
```
nvcc my_cuda_program.cu -o my_cuda_executable
```这将把名为 `my_cuda_program.cu` 的 CUDA 源文件编译成一个名为 `my_cuda_executable` 的可执行文件,该文件可以在支持 CUDA 的 NVIDIA GPU 上运行。
难道我没有正确安装cuda?
打开命令行,输入''nvidia-smi''

明明显示我的CUDA版本12.1啊(其实,这是系统支持的CUDA版本,不代表你已经安装了CUDA Toolkit)
再在命令行中输入“nvcc --v”,回车!

提示“nvcc”不是内部或外部命令也不是可运行的程序或批处理文件
那就是没有安装CUDA Toolkit
【如何安装CUDA】传送门==>CUDA安装教程(超详细)_Billie使劲学的博客-CSDN博客
安装完成!

然后,接着在flash-attention路径下通过“pip install .”来安装
完成后通过“pip list”产看是否安装成功!(列表中有【flash-attn】,版本为【1.0.8】,表示安装成功了)

至此,我们安装了所有使用模型所需的依赖库和软件,接下来,可以正式上车了么?(to be continued)文章来源:https://www.toymoban.com/news/detail-768261.html
 文章来源地址https://www.toymoban.com/news/detail-768261.html
文章来源地址https://www.toymoban.com/news/detail-768261.html
到了这里,关于【通义千问】大模型Qwen GitHub开源工程学习笔记(1)-- 使用指南、依赖库和软件的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!