Kafka是一种高性能、可扩展的分布式消息系统,被广泛应用于大规模数据流处理的场景。在Kafka中,group_id是一个关键概念,用于实现消息的分组消费。本文将详细介绍group_id的作用和使用方法,并提供相应的源代码示例。
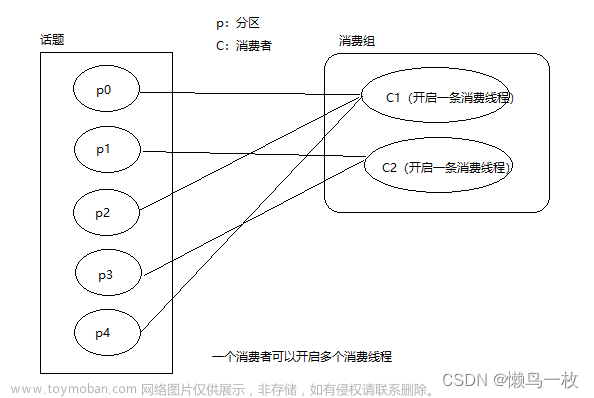
Kafka消息分组消费的概念是指多个消费者协同消费同一个主题的消息,并确保每条消息只被消费组中的一个消费者处理。这种模式在实际应用中非常常见,特别是在大规模数据处理和流式处理任务中。
在Kafka中,每个消费者都属于一个消费组,并且每个消费组可以订阅一个或多个主题。当消息被发送到Kafka集群时,每个消费组中的消费者都有机会消费这些消息。但是,同一个分区的消息只会被消费组中的一个消费者处理。这样可以确保同一条消息只被消费一次,同时还能实现消息的负载均衡。
在创建消费者时,需要为其指定一个唯一的group_id。这个group_id用于标识消费者所属的消费组。同一个消费组内的消费者会共享消息的处理负载,即每个分区的消息只会被消费组内的一个消费者处理。如果消费者在同一个消费组内,则它们将共享消费组的负载,并且每个分区只会被消费组内的一个消费者消费。文章来源:https://www.toymoban.com/news/detail-768469.html
下面是一个使用Java语言编写的Kafka消费者示例,演示了如何使用group_id进行消息分组消费:文章来源地址https://www.toymoban.com/news/detail-768469.html
import org.apache.kafka.clients到了这里,关于Kafka中的group_id:实现消息分组消费的关键的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!