设计说明 国内外数字音乐市场经过几百年的发展, 收录的音乐作品总数量已经达到了相当可观的程度, 面对数量如此庞大的音乐作品, 如何更加便捷、高效的让用户听到喜欢的音乐作品, 是音乐平台必须要考虑的事情, 也是科研人员非常感兴趣的研究课题。 本文首先对数据分析中涉及到了技术进行分析,通过爬取QQ音乐数据,然后使用Python中的pandas库对数据进行分析,最后通过flask进行可视化展示。具体功能包括使用Python进行音乐数据的爬取,并将音乐数据存储在MySQL数据库中,最后利用Flask框架在web页面中对音乐数据分析结果进行展示。 关键词:数据分析;Python;网络爬虫
DESIGN DESCRIPTION
After hundreds of years of development of digital music market at home and abroad, the total number of music works collected has reached a considerable degree. Faced with such a large number of music works, how to let users hear their favorite music works more conveniently and efficiently is a matter that music platforms must consider, and also a research topic that researchers are very interested in.
In this paper, data analysis involves techniques first. By climbing QQ music data, pandas library is used to analyze the data, and finally visual display is performed by flask. The specific functions include using Python to crawl music data, storing music data in MySQL database, and finally using Flask framework to display the analysis results of music data in a web page.
Key words: Data analysis; Python; Web crawler
目 录
1 选题背景分析
1.1研究的背景与目的意义
1.1.1 研究背景
1.1.2 研究目的及意义
1.2 国内外发展现状
1.3 研究方案
2 设计技术方案
2.1 网络爬虫技术
2.2 MySQL
2.3 Echarts
2.4 Flask
3 系统分析
3.1 可行性分析
3.1.1 技术可行性
3.1.2 经济可行性
3.2 业务需求分析
3.3 非功能性需求
4 系统设计
4.1 数据爬虫设计
4.2 数据分析设计
4.3 数据可视化流程
5 系统实现
5.1 界面实现
5.2 代码实现
参考文献
致 谢
1 选题背景分析
1.1研究的背景与目的意义
1.1.1 研究背景
随着互联网的发展,音乐已经成为人们日常生活中不可或缺的一部分。作为中国最大的在线音乐平台之一,QQ音乐拥有海量的音乐资源和庞大的用户群体。如何利用这些数据进行分析和可视化,探索音乐市场的趋势和用户的偏好,已经成为了一个热门的研究方向。Python作为一种高效、易学、功能强大的编程语言,已经成为了数据分析和可视化的首选工具之一。通过Python的数据分析和可视化库,我们可以轻松地对QQ音乐的数据进行处理和分析,从而得出有价值的结论和见解。通过以上分析,我们可以深入了解QQ音乐的市场情况和用户需求,为音乐产业的发展提供有价值的参考。
1.1.2 研究目的及意义
本文旨在利用Python对QQ音乐的数据进行可视化分析,探究QQ音乐的用户偏好和音乐市场趋势,为音乐从业者和音乐爱好者提供参考和启示。本研究的意义在于:
为音乐从业者提供市场分析和销售策略制定的参考和启示。
为音乐爱好者提供了解音乐市场趋势和用户偏好的途径,帮助他们更好地选择和欣赏音乐。
推广Python在数据分析和可视化领域的应用,为Python的普及和发展做出贡献。
1.2 国内外发展现状
随着互联网技术的不断发展,音乐数据分析已经成为了一个热门的研究领域。其中,QQ音乐作为国内最大的在线音乐平台之一,其数据分析也备受关注。基于Python的QQ音乐数据可视化分析已经成为了研究者们的热门选择。
在国内,基于Python的QQ音乐数据可视化分析已经得到了广泛的应用。例如,有研究者利用Python对QQ音乐的用户行为数据进行分析,发现用户的听歌偏好与地域、性别、年龄等因素有关。另外,还有研究者利用Python对QQ音乐的歌曲数据进行分析,发现不同类型的歌曲在不同的时间段内的播放量存在着显著的差异。
在国外,基于Python的QQ音乐数据可视化分析也得到了广泛的应用。例如,有研究者利用Python对QQ音乐的歌曲数据进行分析,发现不同类型的歌曲在不同的地区的播放量存在着显著的差异。另外,还有研究者利用Python对QQ音乐的用户行为数据进行分析,发现用户的听歌偏好与其社交网络的密度有关。
综上所述,基于Python的QQ音乐数据可视化分析已经成为了国内外研究者们的热门选择。通过对QQ音乐的用户行为数据和歌曲数据进行分析,可以深入了解用户的听歌偏好和歌曲的流行趋势,为音乐产业的发展提供有价值的参考。
1.3 研究方案
其中系统实现的功能主要分为以下几个部分。
1、利用Python语言编写爬虫程序,爬取音乐的详细信息。
2、设计MySQL数据库,将爬取到的音乐信息存储在数据库中。
3、利用Python实现对数据的分析和可视化展示。
4、利用Flask搭建web框架。
2 设计技术方案
2.1 网络爬虫技术
网络爬虫就相当于蜘蛛网上面寻找食物的蜘蛛,我们所需要的数据资源就相当于蜘蛛的食物。在蛛网的每一个节点之上,蜘蛛经过一次,就代表网络爬虫成功在这个页面抓取到了需要的信息。说的简单一点,网络爬虫就是按照一定的规律获取网页并提取保存其中信息的工具。 Python网络爬虫技术是指利用Python编程语言来获取互联网上的数据的技术。它可以自动化地访问网站、抓取数据、解析HTML、XML等文档格式,并将数据存储到本地或者数据库中。
Python网络爬虫技术的主要应用场景包括搜索引擎、数据挖掘、商业情报、舆情监测、竞品分析、自动化测试等领域。下面我们来介绍一下Python网络爬虫技术的基本流程和常用工具,网络爬虫的基本流程:
Python网络爬虫的基本流程包括以下几个步骤:
(1)确定目标网站:首先需要确定要爬取的目标网站,包括网站的URL、网页的结构、数据的类型等。
(2)分析网页结构:通过分析目标网站的网页结构,确定需要抓取的数据所在的位置和格式。
(3)编写爬虫程序:使用Python编写爬虫程序,实现自动化访问网站、抓取数据、解析HTML等功能。
(4)存储数据:将抓取到的数据存储到本地或者数据库中,以便后续的分析和使用。
2.2 MySQL
MySQL的数据库引擎主要有两种:MyISAM和InnoDB。MyISAM是MySQL最早的数据库引擎,它是一种非事务性的引擎,适用于读取频繁的应用场景。MyISAM的优点是速度快,但是它不支持事务和行级锁,因此在高并发的情况下容易出现数据冲突和数据丢失的问题。InnoDB是MySQL的另一种数据库引擎,它是一种事务性的引擎,适用于写入频繁的应用场景。InnoDB的优点是支持事务和行级锁,能够保证数据的一致性和完整性,但是它的速度相对较慢。
2.3 Echarts
为了让数据更加直观,该系统采用Echarts图表方式。Echarts是在前端使用JavaScript代码实现的,用来在前端显示数据可视化图表,可以兼容大多数主流的浏览器。Echarts可以支持的图像、图形、图表多种多样,比如饼状图、折线点图、K线图、柱形图等10多种图表,并且支持多种用于交互的组件。除此之外,Echarts图表还有其他很多功能,比如支持多组件和多图表混合联动和展示,给招聘信息分析带来很好的效果,给用户带来比较好的体验。
2.4 Flask
Flask框架是Python中的一个非常重要的WEB开发框架,与另一个重量级Python Web框架Django齐名。但与Django的重和全不同,Flask强调灵活和简单。所以我们也会称Flask为微框架。Flask有两个主要依赖,WSGI工具集:Werkzeug和模板引擎:Jinja2,Flask 只保留了 Web 开发的核心功能,其他的功能都由外部扩展来实现,比如集成数据库、表单认证、文件上传、各种各样的开放认证技术等功能。正是因为 Flask 支持用户灵活选择扩展功能,使得Flask越来越受到开发者的喜爱。Flask也不会替你做出许多决定,比如选用何种数据库、使用何种模板引擎,在flask中这些都是非常容易改变的。
3 系统分析
3.1 可行性分析
随着互联网的发展,音乐已经成为人们生活中不可或缺的一部分。而QQ音乐作为国内最大的在线音乐平台之一,其拥有的海量音乐数据也成为了研究音乐市场和用户行为的重要资源。因此,基于Python的QQ音乐数据可视化分析具有很大的可行性。
3.1.1 技术可行性
逻辑结构较简单的系统是容易实现的,本系统便是如此。涉及到的信息小,因此,开发者的需求并不需要很高即可完成;个人机、Win10系统、开发软件、论文编写程序再加上所学的语言和指导老师的点播,专业基本功底,就能完成本次任务,因此从技术角度出发是能够行得通的。
3.1.2 经济可行性
音乐数据可视化分析系统的经济可行性是指落地系统和将来收入是否成比,是否对称合理,同时还要看此系统能否真正管理人员提供便利,成功实现想要达到的效益。本系统的开发所使用的硬件都是已经存在的,所使用的软件和语言都是开源的,无需花费额外的费用,因此在开发成本上可以满足,以此看来,系统拥有经济上的可行性。
3.2 业务需求分析
1、信息采集功能
系统可以爬取互联网上的音乐数据,爬取音乐相关的名字、歌手、专辑、时长的信息。
2、信息分析功能
将采集到的信息经过Python技术的筛选和预处理,分析之后将分析过后的数据存储到数据库中。
3、数据可视化功能
通过echarts框架将分析过后的数据通过图标的形式展示到web端。
3.3 非功能性需求
性能是系统稳定运行的保障也是评价一个系统的重要指标,对系统性能进行优化可以提高系统的效率。系统会存在多人同时访问的高并发情况,为了让系统在此种情况下不发崩溃闪退的Bug,我们在初期设计数据库结构的时候,就对数据库建立的索引的技术并且还对数据库的读取进行了性能优化。使用固定长度的字段,通过限制字段长度来提高数据库处理速度,在sql语句方面对语句进行优化,减少比较次数,如:通过limit限制返回条目数。硬件的性能也需要进行优化,如:扩大虚拟内存,并保证有足够可以扩充的空间,同时增加服务器的吞吐量。通过对这几方面的优化,提高用户使用的体验感,降低系统在高并发情况下发生延迟的可能性。
由于本系统是属于服务类型的项目,向用户提供参考数据,操作不易过多,过于繁琐的流程只会消耗用户的耐心,因此优化流程也是优化系统的重要一步。尽量做到一切从简,让顾客以最少的步骤得到最优的结果,将简洁高效提现在系统中,给顾客带来更好的体验。系统中所有需要用户操作的的位置都有相关文字说明,尽量保障用户在使用系统的过程中不存在疑问,或含糊不清的情况。
4 系统设计
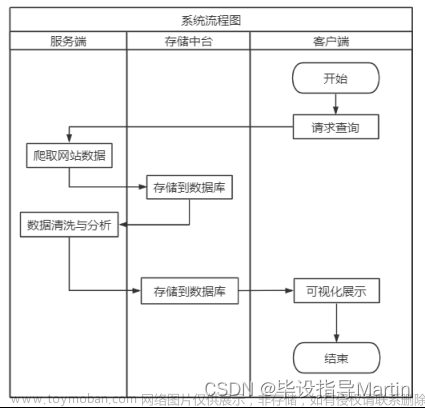
4.1 数据爬虫设计
爬虫具体的流程如下所示:

图4.1 爬虫流程图
本案例中,首先通过pip install beautifulsoup4下载安装beautifulsoup库;通过pip install lxml下载安装lxml。
其次,通过from bs4 import BeautifulSoup语句导入beautifulsoup4库。
本课题数据提取程序中,执行一段js代码后,得到整个HTML源代码,再通过BeautifulSoup库使用soup = BeautifulSoup(data,'lxml'),创建BeautifulSoup对象,使用lxml解析库解析得到页面标签类数据soup,完成网站该页面的分析与解析功能。
再者,通过import re语句导入re模块,根据需获取的慕课实战网站特定数据,编译正则表达式,通过results = re.findall(pattern, soup)语句,将爬虫程序所采集的该HTML页面数据与特定的正则表达式对象进行匹配,筛选数据,匹配成功的数据以列表的形式返回,即获取到需要提取的数据。数据提取模块流程图
如4-2所示。

图4.2 数据爬取流程图
4.2 数据分析设计
在数据处理部分,主要是对爬取下来的数据进行处理,让数据能够符合数据分析的要求,对于本次音乐数据的爬取来说,主要是对空值的替换、异常值的删除和数据格式的转换,主要流程如下。
图4.3 数据处理流程
4.3 数据可视化流程
在本次选题中可视化模块的研究主要是在Python基

础上进行。数据分析可视化主要是利用Echarts相关组件和技术。这一项技术的功能可以实现最直观、形象、生动的可视化图画和表格,而且该Echarts相关组件和技术具有可交互以及高度个性化定制的特点。它的创新的拖拽重计算、值域漫游以及数据试图等功能的使用非常大的提高了用户使用体验,并且可以让用户具有数据挖掘和整合的能力。通过在官网上下载对应的Echarts.min.js文件,并将其加入到项目中,也可以通过直接调用官网链接来导入Echarts,官网链接为https://assets.pyEcharts.org/assets/Echarts.min.js。
导入文件之后在网页主要部分添加div标签预留空间,将官网上的框架添加到对应页面中的js部分,当flask传入数据时,即可实现图表的展示。在对数据的可视化部分,主要流程如下。

图4.4 系统可视化流程图
5 系统实现
5.1 界面实现
系统启动完成后,在浏览器中输入地址,具体的实现界面如图5.1所示:

图 5-1 系统实现界面
如图5-1所示,系统主要实现了最受欢迎歌单类型TOP7、最受欢迎的歌单TOP5、歌单收藏量变化、男女创建歌单数量对比、歌单歌曲数量范围等。
5.2 代码实现
实现的代码如下所示:
from flask import Flask, render_template, url_for
import json
import pandas as pd
import pymysql
import re
app = Flask(__name__)
cols = ['id','name','type','tags','create_time','update_time','tracks_num','play_count','subscribed_count','share_count','comment_count','nickname','gender','user_type','vip_type','province','city']
df = pd.read_csv('wymusic.csv',sep='\t',names=cols)
"""最受欢迎的歌单类型"""
@app.route('/get_hot_type')
def get_hot_type():
hot_type_df = df[['type', 'play_count']].groupby(df['type']).sum().sort_values('play_count', ascending=False).reset_index()
hot_type_top7 = hot_type_df.head(7)
playlist_type = hot_type_top7['type'].tolist()
play_count = hot_type_top7['play_count'].tolist()
return json.dumps({'playlist_type': playlist_type, 'play_count': play_count}, ensure_ascii=False)
"""歌单数据随月份变化"""
@app.route('/get_month_data')
def get_month_data():
yearList = []
for year in ['2018', '2019']:
yearList.append({
"year": year,
"data": [
df[df['create_time'].str[:4]==year].groupby(df['create_time'].str[5:7]).sum().reset_index()['share_count'].tolist(),
df[df['create_time'].str[:4]==year].groupby(df['create_time'].str[5:7]).sum().reset_index()['comment_count'].tolist()
]
})
month = df[df['create_time'].str[:4]==year].groupby(df['create_time'].str[5:7]).sum().reset_index()['create_time'].tolist()
yearData = {
"yearData": yearList,
"monthList": [str(int(x))+'月' for x in month]
}
return json.dumps(yearData, ensure_ascii=False)
"""歌单数据随天数变化"""
@app.route('/get_day_data')
def get_day_data():
non_vip_df = df[df['vip_type']==0].groupby(df['create_time'].str[8:10]).sum().reset_index()[['create_time', 'subscribed_count']]
vip_df = df[(df['vip_type']==10) | (df['vip_type']==11)].groupby(df['create_time'].str[8:10]).sum().reset_index()[['create_time', 'subscribed_count']]
vip_type_df = pd.merge(non_vip_df, vip_df, left_on='create_time', right_on='create_time', how='inner')
sub_data = {
"day": [str(int(x)) for x in vip_type_df["create_time"].tolist()],
"vip": vip_type_df["subscribed_count_y"].tolist(),
"nonvip": vip_type_df["subscribed_count_x"].tolist(),
}
print(sub_data)
return json.dumps(sub_data, ensure_ascii=False)
"""歌单歌曲数量分布"""
@app.route('/get_track_data')
def get_track_data():
bins = [0, 50, 150, 500, 100000]
cuts = pd.cut(df['tracks_num'], bins=bins, right=False, include_lowest=True)
data_count = cuts.value_counts()
data = dict(zip([str(x) for x in data_count.index.tolist()], data_count.tolist()))
map_data = [{'name': name, 'value': value} for name, value in data.items()]
track_value = {'t_v': map_data}
return json.dumps(track_value, ensure_ascii=False)
"""语种类型歌单播放量"""
@app.route('/get_type_data')
def get_type_data():
gender_df = df[['gender']].groupby(df['gender']).count()
gender_data = [{'name': '男', 'value': int(gender_df.loc['男', 'gender'])},{'name': '女', 'value':int( gender_df.loc['女', 'gender'])}]
type_sum = {'t_s': gender_data}
return json.dumps(type_sum, ensure_ascii=False)
def replace_str(x):
rep_list = ['省', '市', '维吾尔','自治区', '壮族', '回族', '维吾尔族', '特别行政区']
for rep in rep_list:
x = re.sub(rep, '', x)
return x
def add_province(df_data, province):
# 所有年份
years = df_data['create_time'].drop_duplicates().tolist()
for year in years:
# 每年的省份
new_province = df_data.loc[df_data['create_time']==year,:]['province'].drop_duplicates().tolist()
# 缺失的省份 = 所有省份 - 每年的省份
rest_province = [x for x in province if x not in new_province]
# 对缺失的省份生成一个DataFrame,填充0值,并与原DataFrame合并
if len(rest_province):
rest_df = pd.DataFrame([[year,x,0,0] for x in rest_province], columns=df_data.columns)
df_data = pd.concat([df_data, rest_df], ignore_index=True)
return df_data
"""动态地图"""
@app.route('/get_map_data')
def get_map_data():
time_df = df.groupby([df['create_time'].str[:4], df['province'].apply(replace_str)])[['play_count', 'share_count']].count().reset_index()
re_time_df = time_df[time_df['province'] != '海外']
province = re_time_df['province'].drop_duplicates().tolist()
re_time_df2 = add_province(re_time_df, province)
final_time_df = re_time_df2.sort_values(by=['create_time', 'province']).reset_index(drop=True)
final_province = final_time_df['province'].drop_duplicates().tolist()
final_year = final_time_df['create_time'].drop_duplicates().tolist()
playlist_num = []
for year in final_year:
playlist_num.append(final_time_df.loc[final_time_df['create_time']==year, 'play_count'].tolist())
playlist_data = {"year": final_year, "province": final_province, "playlist_num": playlist_num}
return json.dumps(playlist_data, ensure_ascii=False)
app.route('/')
def index():
gender_df = df[['gender']].groupby(df['gender']).count()
gender_data = {'男': gender_df.loc['男', 'gender'], '女': gender_df.loc['女', 'gender']}
df1 = pd.read_csv('song.csv')
songlist = list(df1.values)[:5]
return render_template('index.html', gender_data=gender_data,songlist=songlist)
if __name__ == "__main__":
app.run()
结 语
随着互联网平台的兴起,越来越多的人开始在音乐分析进行听歌、看视频、发布评论。随着网民人数的增加,人们对于音乐的需求也越来越大。当前现有的音乐分析还不够完善,还存在诸多不足之处。本次设计就是基于这样的背景开发的,通过研究国内外研究现状和应用前景,分析了系统使用到的相关技术,随后对音乐分析系统的需求进行分析、总体和数据库进行设计,分析了音乐分析的功能性需求和性能需求,对系统的总体设计从功能模块和流程分析进行,同时对数据库概念结构和逻辑结构进行设计。接着就是系统的开发与实现,从用户功能实现和后台管理实现出发对系统的开发与实现过程进行介绍。
本次设计课程的整个过程被完整记录下来,但是系统开发的学习工作,还有待持续。通过这次机会,让自己对相关知识的学习及应用能力得到了提升,特别是遇到问题时候,知道该如何去思考,如何选择方法、工具,这些经验确实非常重要。对于知识层面的学习,我不会停止,将会一如既往的深入钻研,并抓住每一个能够提高实际锻炼的机会,使得自己再这一技术领域有更大的突破。
参考文献
[1]汪邦博,胡必波,李满,刘丝雨,刘晓莉.基于Scrapy的大数据学情分析系统就业岗位数据爬取,2021-11-18
[2]刘影.基于Python的房价数据爬取及可视化分析[J].信息与电脑(理论版),2021-09-25
[3]张敏,卿粼波,王巧,才虹丽,陈杨.基于混合时空感知网络的城市区域人流量预测[J].智能计算机与应用,2021-08-01
[4]孙文杰,张素莉,许骏,郑国勋,张维轩.长白山旅游数据爬取及可视化分析[J].吉林大学学报(信息科学版),2021-07-15
[5]施元磊. 景区交通流量预测与游客行程规划技术研究[D].西北大学,2021-06-01
[6]Agafonov A. A.. Short-Term Traffic Data Forecasting: A Deep Learning Approach[J]. Optical Memory and Neural Networks,2021-03-15
[7]戴瑗,郑传行.基于Python的南京二手房数据爬取及分析[J].计算机代,2021-01-15
[8]简悦,汪心瀛,杨明昕.基于Python的豆瓣网站数据爬取与分析[J].电脑知识与技术,2020-11-15
[9]刘晓知.基于Python的招聘网站信息爬取与数据分析[J].电子测试,2020-06-05
[10]刘鑫. 基于SVM和LSTM的火车站入口人流量预测[D].山西大学,2020-06-01
[11]欧阳元东.基于Python的网站数据爬取与分析的技术实现策略[J].电脑知识与技术,2020-05-05
[12]高艳.基于Selenium框架的大数据岗位数据爬取与分析[J].工业控制计算机,2020-02-25
[13]成文莹,李秀敏.基于Python的电影数据爬取与数据可视化分析研究[J].电脑知识与技术,2019-11-15文章来源:https://www.toymoban.com/news/detail-768494.html
[14]Ben Sassi Imen,Ben Yahia Sadok,Liiv Innar. MORec: At the crossroads of context-aware and multi-criteria decision making for online music recommendation[J]. Expert Systems With Applications,2021,183:文章来源地址https://www.toymoban.com/news/detail-768494.html
到了这里,关于python-大数据分析-基于大数据的QQ音乐数据分析系统设计与实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!