hive支持的文件类型:textfile、sequencefile(二进制序列化文件)、rcfile(行列式文件)、parquet、orcfile(优化的行列式文件)
一、orc文件
带有描述式的行列式存储文件。将数据分组切分,一组包含很多行,每一行再按例进行存储。
orc文件结合了行式和列式存储结构的优点,在有大数据量扫描读取时,可以按行进行数据读取。如果要读取某列的数据,可以在读取行组的基础上读取指定的列,而不需要读取行组内所有数据以及一行内的所有字段数据。
1.1 orc文件的结构:


条带(stripe)
orc文件存储数据的地方
文本脚注(file footer)
包含了stripe列表,每个stripe包含的行数,以及每个列的数据类型。包含每个列的最大值,最小值,行计数,求 和等信息。
postscript
压缩参数和压缩大小相关的信息
1.2 stripe结构
分为三部分:index data、rows data、stripe footer
index data:保存了所在条带的一些统计信息,以及数据在stripe中的位置索引信息
rows data:存储数据的地方,由多行组成,数据以stream(流)的形式存储
stripe footer:保存数据所在的目录
1.3 rows data数据结构
metadata stream :描述每个行组的元数据信息
data stream:存储数据的地方
1.4 orc文件中提供了三个级别的索引
文件级别:记录文件中所有script的位置信息,以及文件中存储的每列数据的统计信息
条带级别:记录每个stripe所存储的数据统计信息
行组级别:在script中,每10000行构成一个行组,该级别的索引信息就是记录这个行组中存储的数据统计信息
1.5 效率和数据类型
通过orc文件的索引,可以快速定位要查询的数据块,规避不满足查询条件的数据块和文件,相比读取传统的数据文件,进行查找时需要遍历全部数据,使用orc可以避免磁盘和网络的I/O浪费,从而提高查询效率。提升整个集群的工作负载。
hive以orc文件格式存储时,描述这些数据的字段信息,字段类型信息以及编码等信息都和orc中存储的数据放在一起。
orc文件都是自描述的,不依赖外部的数据,也不存储在hive元数据库中。
数据类型:boolean,tinyint、smallint、int、bigint、float、double、string、varchar、char、binary,timestamp和date、
复杂类型:struct、list、map、union
所有类型都可以接受null值。
1.6 acid事务的支持
0.14版本之前,hive表的数据只能新增或者整块删除分区表,而不能对表进行单个记录的修改。0.14版本以后,orc文件类型能够确保hive在工作时的原子性、一致性、隔离性、持久性的ACID事务能够被正确的使用。可以对单条数据进行更新。
hive 的事务适合对大批量的数据进行更新,不适合频繁的小批量数据。
下面是创建hive事务表的方法
--(1)开启配置
----开启并发支持,支持删除和更新事务
set hive.support.concurrentcy=true;
----支持acid事务的表必须为分桶表
set hive.enforce.bucketing=true;
-----动态分区,开启事务需要开启动态分区非严格模式
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
----所有的org.apache.hadoop.hive.sql.lockmgr.DummyTxnManager 不支持事务
set hive.txn.manager=org.apache.hadoop.hive.sql.lockmgr.DummyTxnManager
---开启在相同的一个meatore实例运行初始化和清理的线程
set hive.compactor.initiator.on=true;
--设置每个metastore实例运行的线程数
set hive.compactor.worker.threads=1
--(2)创建表
-- 必须支持分桶
create table student_txn
( id int,
name String
)cluster by (id) into 2 buckets
stored as orc
-- 表属性中添加支持事务
tblproperties('transactional' = 'true')
--(3) 插入数据,更新数据
insert into table student_txn values('1000','student_1001');
update student_txn set name='student_lzn' where id='1001';
1.7 orc相关的配置
orc.compress: 压缩类型,none,zlib,snappy
orc.compress.size: 压缩块的大小,默认值262114(256kb)
orc.stripe.size: 写stripe,可以使用的内存缓冲池大小,默认67108864(64mb)
orc.row.index.stride: 行组级别的索引数量大小,默认10000,必须设定为大于10000的数。
orc.create.index: 是否创还能行组级别索引,默认true
orc.bloom.filter.columns: 需要创建的布隆过滤器的组
orc.bloom.filter.fpp: 使用布隆过滤器的假正(false positive)概率,默认为0.05
hive中使用布隆过滤器可以用较少的空间判定数据是否存在表中(如果不存在,那么100%就是不存在,存在的话再去查找确认存在)。
hive表配置属性:
hive.stats.gather.num.threads: 收集统计信息的线程数,默认10。只适用于orc这类已经实现StatsProvidingReader接口的文件格式。
hive.exec.core.memory.pool: 写orc文件,可以使用的已分配堆内存的最大比例。
hive.exec.orc.default.stripe.size: 每个stripe文件,可以会用的缓冲池大小,默认64MB。
hive.exec.orc.default.block.size: 每个stripe存储文件块大小,默认256MB。
hive.exec.orc.dictionary.key.size.threshold: 阈值,默认0.8。如果字典中的键数大于所有非空数据行数的这一阈值,则关闭字典编码。
hive.exec.orc.default.row.index.stride: hive表行组级索引数量大小,默认10000。
hive.exec.orc.default.block.padding: 写orc文件时,是否填充已有的hdfs文件块,默认false。
hive.exec.orc.block.padding.tolerance: 阈值,默认0.05,允许填充到hdfs文件块的最小文件。
hive.exec.orc.default.compress: 定义orc文件压缩编码、解码器。默认为zlib。
hive.merge.orcfile.stripe.level: 默认true。这时如果hive.merge.mapfile、hive.merge.mapredfiles或者hive.merge.tezfiles也开启,在写入数据到orc文件时,将会一strip级别合并小文件。
hive.exec.orc.zerocopy: 默认false,使用零拷贝方式读取orc文件。
hive.exec.orc.skip.corrupt.data: 默认false,处理数据时,遇到异常抛出,为true,则跳过异常。
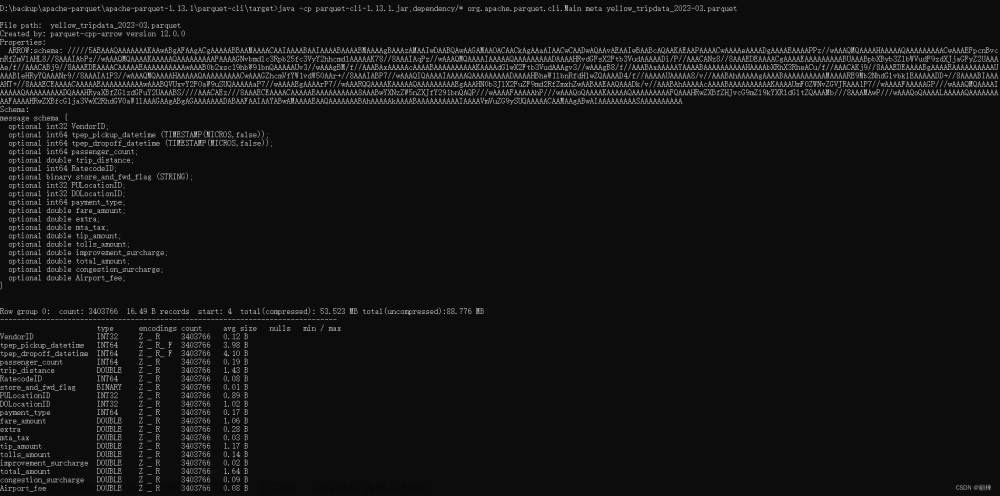
二、parquet文件
2.1 parquet的基本结构

表被分为多个行组,每个列块又被拆分成若干的页。
parquet存储时,会记录数据的元数据,文件级别的元数据,列块级别的元数据,页级别的元数据。
文件级别的元数据:表结构,文件记录数,文件拥有的行组数,以及行组的总量记录数,每个行组下,列块文件偏移量。
列块级别的元数据:列块压缩前后的数据大小,以及压缩编码,数据页偏移量,索引页偏移量,列块数据记录数。
页级别的元数据(页头):页的编码信息,数据记录数
parquet文件结构同样在查询时可以过滤大量的记录,但是orc对过滤做了额外的优化,相比之下,查时,orc文件会消耗更少的资源。
2.2 parquet文件配置
parquet.block.size: 默认134217728byte,128MB,表示在内存中的块大小。可以设置更大,可以提高读效率,但是写时耗费更多的内存。
parquet.page.size: 1048576byte,1MB,每个页的大小,特指压缩后的页大小,读取时先将页进行解压。页是parquet操作的最小单位,每次读取时,必须读完一整页数据才能访问数据。设置过小会导致压缩出现性能问题。
parquet.compression: 默认uncompressed、表示页的压缩方式。
parquet.enable.dictionary: 默认true,是否启用字典编码
parquet.dictionary.page.size: 默认1048576byte(1MB),使用字典码,会在每一行,每一列中创建一个字典页。使用字典编码,如果在存储的数据页中重复数据较多,能够起到很好的压缩效果,也能减少每页的内存使用。
2.3 数据归档
对于hdfs中有大量小文件的表,可以通过hadoop归档(hadoop archive)的方式将文件归并成为较大的文件。
归并后的分区会先创建data.har目录,包含:索引和数据。索引记录归并前的文件在归并后的位置
数据归档:数据归档后不会对数据进行压缩
—启用数据归档
set hive.archive.enabled=true;
set hive.archive.har.parentdir.settable=true;
—归档后的最大文件大小
set har.partfile.size=1099511627776
—对分区执行归档
set table table_name archive partition(partition_col=partition_val)
–将归档的分区还原为原来的普通分区文章来源:https://www.toymoban.com/news/detail-768723.html
alter table table_name unarchive partition (partition_col=partition_val)文章来源地址https://www.toymoban.com/news/detail-768723.html
到了这里,关于hive文件存储格式orc和parquet详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!