- Neo4j 导入CSV数据
- 要求
- 必须有一个或多个 CSV 文件来表示将在图中创建的节点和关系。
- 必须有一个已启动的现有 Neo4j DBMS。
- Neo4j 中存储为属性的数据类型
- String:字符串
- Long (integer values):整数值
- Double (decimal values):双精度(十进制值)
- Boolean:布尔值
- Date/Datetime:时间
- Point (spatial):点空间
- StringArray (comma-separated list of strings):逗号分隔的字符串列表
- LongArray (comma-separated list of integer values):逗号分隔的整数值列表
- DoubleArray (comma-separated list of decimal values):逗号分隔的十进制值列表
- CSV 数据导入 Neo4j 的方法
- 使用 Neo4j 数据导入器。
- 编写 Cypher 代码来执行导入。
- LOAD CSV
- 数据导入 Neo4j 的步骤
- 了解源 CSV 文件中的数据
- CSV 的文件结构
- CSV 文件是否有标题信息,描述字段的名称。
- 每行中的字段的分隔符是什么。
- CSV 文件示例
- Cypher 使用的默认值,逗号 (,) 是字段终止符,如果源 CSV 文件使用不同的字段终止符,则必须FIELDTERMINATOR在 CypherLOAD CSV子句中指定。
- 数据
- 数据规范化
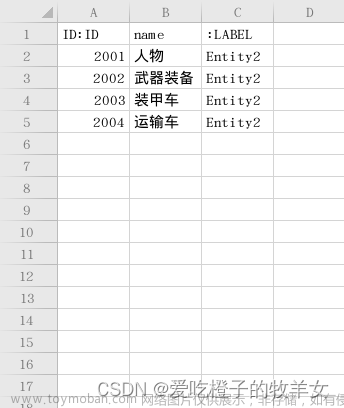
- 唯一的 ID,能够拥有与关系表相对应的 CSV 文件,其中使用 ID 来标识关系。
- 通常对应于单个 RDBMS 表
- 非规范化数据
- 数据由对应于同一实体的多行表示,将作为节点加载。
- 特点
- CSV 文件中存在重复数据。
- 非规范化数据通常代表 RDBMS 中多个表的数据。
- 表示将作为节点加载的实体的 ID 必须是唯一的。
- 数据规范化
- ID 必须是唯一
- 从 CSV 文件加载数据时,很大程度上依赖文件中指定的 ID。
- Neo4j 的最佳实践是使用 ID 作为每个节点的唯一属性值。
- CSV 的文件结构
- 检查并清理(如有必要)源数据文件的数据
- 在开始使用源 CSV 数据之前,您必须了解每行如何使用定界符、引号和特殊字符。
- 如果标头与表示字段的数据不对应,则无法加载数据。
- 还必须知道您是否可以假设使用默认分隔符“,”,否则,您将需要在使用 Cypher 导入数据时使用FIELDTERMINATOR关键字 along 。LOAD CSV
- 应该拥有 CSV 文件的本地副本,以便您可以检查其中的数据。
- 在使用 Neo4j 数据导入器时,将需要 CSV 文件的本地副本。
- 导入步骤
- 1、获取或下载 CSV
- 如果 CSV 文件是一个 URL,可以简单地在 Web 浏览器中下载它并将其保存在本地。
- 2、确定分隔符
- 查看文件的内容(至少是开头的行)以确定分隔符。
- 3、确定标头是否匹配字段
- 使用 CSV 文件,您可以在电子表格中打开它以更好地理解数据。
- 重点提示
- 默认情况下,每行中的所有这些字段都将作为字符串类型读入。
- 另请注意,对于此 CSV 文件,国家或语言等多值字段的值由“|”分隔 特点。
- 在电子表格中,检查数据可能更容易一些。
- 4、确定所有数据是否可读
- Cypher 代码,它将读取包含标头并指定为 URL 的 CSV 文件中的所有数据
- 5、数据是否干净?
- LOAD CSV WITH HEADERS FROM 'https://data.neo4j.com/importing/ratings.csv' AS row RETURN count(row)
- 引号使用正确吗?
- 如果元素没有值,是否会使用空字符串?
- 是否使用 UTF-8 前缀(例如 \uc)?
- 某些字段是否有尾随空格?
- 这些字段是否包含二进制零?
- 理解列表是如何形成的(默认是使用冒号(:)作为分隔符。
- 有没有明显的错别字?
- 1、获取或下载 CSV
- 创建或理解将在导入过程中实施的图形数据模型
- 了解源 CSV 文件中的数据
- Neo4j 数据模型
- 要用于导入的数据
- 检查数据以确保它是干净的
- 使用 Neo4j 数据导入器
- 概述
- Neo4j 数据导入器(Neo4j Data Importer)是一个图形应用程序,允许将 CSV 文件从本地系统导入到图形中。
- 使用此图形应用程序,检查 CSV 文件标头,并将它们映射到 Neo4j 图形中的节点和关系。
- 连接到正在运行的 Neo4j DBMS 以执行导入。
- Data Importer 的好处是无需了解 Cypher 即可加载数据。无需使用 Cypher 执行导入。
- 导入到图形中的数据可以解释为字符串、整数、浮点数、日期时间或布尔数据。
- 用于启动最新版本 Neo4j Data Importer 的URL
- 用于连接到远程 DBMS:https://data-importer.neo4j.io/ ?acceptTerms=true
- 用于连接到远程 DBMS:https://data-importer.graphapp.io/?acceptTerms =true
- 用于连接到本地 DBMS:http://data-importer.graphapp.io/?acceptTerms= true
- 要求
- 必须使用 CSV 文件进行导入。
- CSV 文件必须驻留在本地系统上,以便可以将它们加载到图形应用程序中。
- CSV 数据必须是干净的(在之前的课程中学到了这一点)。
- 要创建的所有节点的 ID 必须是唯一的。
- CSV 文件必须有标题。
- 必须启动 DBMS。
- 步骤
- 1、将 CSV 文件放在本地系统上,并确保它们有标题并且是干净的。
- 2、打开 Neo4j 数据导入器
- 使用URL 从任何 Web 浏览器打开 Data Importer 应用程序: https: //data-importer.neo4j.io/versions/0.7.0/ ?acceptTerms=true
- 3、将本地系统上的 CSV 文件加载到图形应用程序中
- 4、检查 CSV 文件中使用的 CSV 标头名称
- 检查第一行确定
- 用于创建节点的文件。
- 用于创建关系的文件。
- 如何使用 ID 来唯一标识数据。
- 检查第一行确定
- 5、添加节点
- a、通过单击“添加节点”图标在 UI 中添加节点。
- b、在“映射详细信息”窗格中为节点指定标签。
- c、选择要在“映射详细信息”窗格中使用的 CSV 文件。
- 6、定义节点的映射详细信息
- a、指定节点的属性(从我们选择所有字段的文件中选择添加)。
- b、如果您希望属性使用不同的名称或类型,请编辑该属性。
- c、指定节点的唯一 ID 属性。映射属性后,它们将在左侧面板中标记为绿色
- 7、创建节点之间的关系
- a、通过将节点的边缘拖动到自身或另一个节点来在 UI 中添加关系。
- b、在“映射详细信息”窗格中指定关系的类型。
- c、选择要在“映射详细信息”窗格中使用的 CSV 文件。
- 8、定义关系的映射详细信息
- a、在 Mapping Details 窗格中,指定要使用的 from 和 to 唯一属性 ID。
- b、如果适用,为文件中的关系添加属性(可选)。
- c、修改属性的名称或类型(如果您的数据模型需要)。
- d、确认左侧面板中的 CSV 已全部设置为可以导入。
- 9、执行导入
- 导入数据。
- 查看导入结果。
- 10、在 Neo4j 浏览器中查看导入的数据
- 数据导入后查看结果
- 必须了解的数据导入器最重要的行为是属性值被写为字符串、长整型(整数值)、双精度(小数值)、日期时间或布尔值。
- Data Importer 根据您为每个节点指定的唯一 ID 在所有节点上创建唯一性约束。
- 其他功能
- 映射导入或导出到 JSON 文件或 ZIP 文件。
- 概述
- 重构导入的数据
- 查看存储在图中的属性类型
- 查看节点的属性名称和类型
- CALL apoc.meta.nodeTypeProperties() YIELD nodeType, propertyName, propertyTypes
- 查看关系的属性名称和类型
- CALL apoc.meta.relTypeProperties() YIELD relType, propertyName, propertyTypes
- 查看节点的属性名称和类型
- 将多值属性转换为列表属性。
- 转换字符串属性
- MATCH (p:Person) SET p.born = CASE p.born WHEN "" THEN null ELSE date(p.born) END WITH p SET p.died = CASE p.died WHEN "" THEN null ELSE date(p.died) END
- 查看节点的属性名称和类型
- CALL apoc.meta.nodeTypeProperties() YIELD nodeType, propertyName, propertyTypes
- 转换多值属性
- 多值属性是可以包含一个或多个值的属性。
- 属性的多值由 “|” 字符被指定为分隔符
- 将多值字段转换为列表,用两个 Cypher 内置函数
- MATCH (m:Movie) SET m.countries = split(coalesce(m.countries,""), "|"),m.languages = split(coalesce(m.languages,""), "|"), m.genres = split(coalesce(m.genres,""), "|")
- coalesce() 如果 m.countries 中的条目为空,则返回空字符串。 split()标识多值字段中的每个元素,其中“|” 字符是分隔符并创建每个元素的列表。
- 转换为 StringArray 类型
- 转换字符串属性
- 向图表添加标签。
- 添加标签
- 将Actor标签添加到具有ACTED_IN关系的所有节点
- MATCH (p:Person)-[:ACTED_IN]->() WITH DISTINCT p SET p:Actor
- 添加标签
- 从属性值创建节点。
- 查看图中约束
- SHOW CONSTRAINTS
- 创建节点之前向图中添加唯一性约束
- 最佳做法是为图中给定类型的节点设置唯一 ID。
- 当您在图中创建节点时,它可以防止重复节点。
- 它加快了MERGE性能。
- 为Genre节点的名称属性创建此唯一性约束
- CREATE CONSTRAINT Genre_name IF NOT EXISTS FOR (x:Genre) REQUIRE x.name IS UNIQUE
- 从Movie节点的genres属性创建Genre节点
- MATCH (m:Movie) UNWIND m.genres AS genre WITH m, genre MERGE (g:Genre {name:genre}) MERGE (m)-[:IN_GENRE]->(g)
- UNWIND子句将节点的流派列表中的元素扩展为行
- MERGE,它仅在节点尚不存在时才创建该节点。
- 从图中删除genres属性
- MATCH (m:Movie) SET m.genres = null
- 查看架构
- CALL db.schema.visualization
- 查看图中约束
- 查看存储在图中的属性类型
- 使用 Cypher 导入大型数据集
- 导入的内存要求
- Data Importer 是一个通用应用程序,它将图表中的所有属性创建为字符串、整数、小数、日期时间或布尔值,您可能需要在导入后对图表进行后处理或重构。数据导入器可用于包含少于 100 万行的中小型数据集。
- 使用 Cypher 语句导入时,可以控制用于导入的内存量。在 Cypher 中,默认情况下,代码的执行是单个事务。为了处理大型 CSV 导入,需要将 Cypher 的执行分解为多个事务。
- 使用:USING PERIODIC COMMIT,使用此代码结构导入大型数据集
- USING PERIODIC COMMIT LOAD CSV WITH HEADERSFROM 'url-for-CSV-file'AS row
- 此类导入的默认事务大小为 500 行。从 CSV 文件中读取 500 行后,数据将提交到图形并继续导入。能够将非常大的 CSV 文件加载到图形中,而不会耗尽内存。
- 在 Neo4j 浏览器中,您必须在这个 Cypher 前加上:auto,即:auto USING PERIODIC COMMIT LOAD CSV…这告诉 Neo4j 使用事务的自动检测。
- 减少导入所需的内存量。
- 优势
- 可以在导入期间执行类型转换和一些“重构”。也就是说,可以自定义属性类型的管理方式,因此无需在加载后进行任何后处理。
- 在导入数据之前,必须检查并可能清理数据。将使用的大型 CSV 数据文件已被清理。
- 首先确定每个文件中的行数
- LOAD CSV WITH HEADERS FROM '文件' AS ROW RETURN COUNT(ROW)
- 改用Cypher导入步骤
- 删除图中的所有节点和关系。
- match (u:实体) detach delete u; match (n) detach delete n
- 确保图中存在所有约束。
- 导入电影 和流派数据。
- 导入人员数据。
- 导入 ACTED_IN 关系。
- 导入 DIRECTED 关系。
- 导入用户数据。
- 删除图中的所有节点和关系。
- 导入的内存要求
- 要求
文章来源地址https://www.toymoban.com/news/detail-768753.html
文章来源:https://www.toymoban.com/news/detail-768753.html
到了这里,关于Neo4j 导入CSV数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![Neo4J入门笔记[2]---导出数据为CSV](https://imgs.yssmx.com/Uploads/2024/02/515917-1.png)




