写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:zhuyc@vip.163.com。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
可视化仪表板 - Superset的安装和使用
本文关键字:superset、可视化、Ubuntu、安装
一、Superset简介
Apache Superset是一个现代化的、企业级的数据探索和可视化平台,旨在帮助数据工程师和科学家在Web界面上创建和共享各种类型的数据洞察。
1. 软件作用
Apache Superset 的底层是一个 Flask 应用程序,其核心功能包括数据可视化、仪表板制作、数据切片和切块、以及 SQL Lab。在 Superset 的应用结构中,Flask 应用程序处理路由、视图函数和模板渲染,而 SQLAlchemy 提供了对多种数据库的抽象访问。
Apache Superset 支持多种数据源,可以连接到任何 SQL-speaking 数据库或数据引擎(如 MySQL、Postgres、BigQuery、Redshift 等),同时也支持各种 大数据组件 如 Hive、Presto、Druid 等,只需要安装部分组件即可。
2. 软件特点
- 具有丰富的数据可视化组件库,提供了多种图表类型,可以满足各种数据展示需求
- 使用SQL Lab可以直接执行SQL查询,方便快捷
- 采用响应式设计,对移动设备友好
- 具有强大的数据权限管理功能,可以精细控制每个用户的数据访问权限
二、Superset安装
1. 前置环境
软件需要运行在Python 3.6及以上版本,推荐使用虚拟环境,官方给出的安装步骤:https://superset.apache.org/docs/installation/installing-superset-from-scratch/。
- virtualenv安装:pip install virtualenv
- 创建虚拟环境:python3 -m venv superset
- 激活虚拟环境:. superset/bin/activate
- 前置环境安装
开始安装前,需要确保系统环境以及python虚拟环境已经安装了以下内容:
sudo apt-get update
sudo apt-get install build-essential
sudo apt-get install python3-dev
pip install wheel
2. 安装配置
- 安装superset:pip install apache-superset

- 前置设定
# 推荐添加到环境变量配置文件中
export FLASK_APP=superset
superset fab create-admin
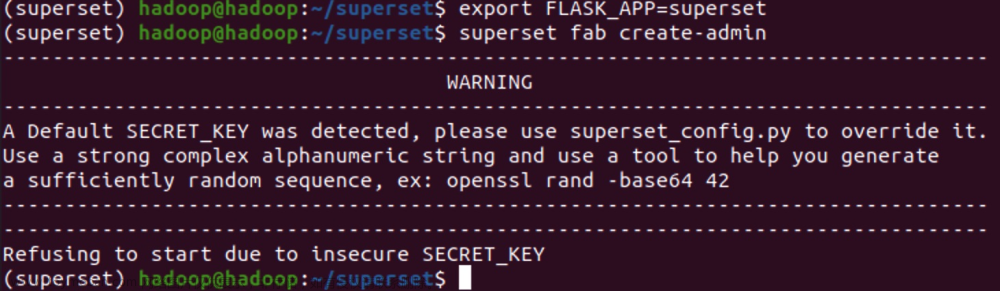
此时会遇到一个警告,我可以可以按照如下步骤来解决:
touch superset_config.py

# 推荐添加到环境变量配置文件中
export SUPERSET_CONFIG_PATH=/home/hadoop/superset/superset_config.py
superset fab create-admin
配置SUPERSET_CONFIG_PATH的路径,指向刚刚创建的config文件,完成后再次进行启动。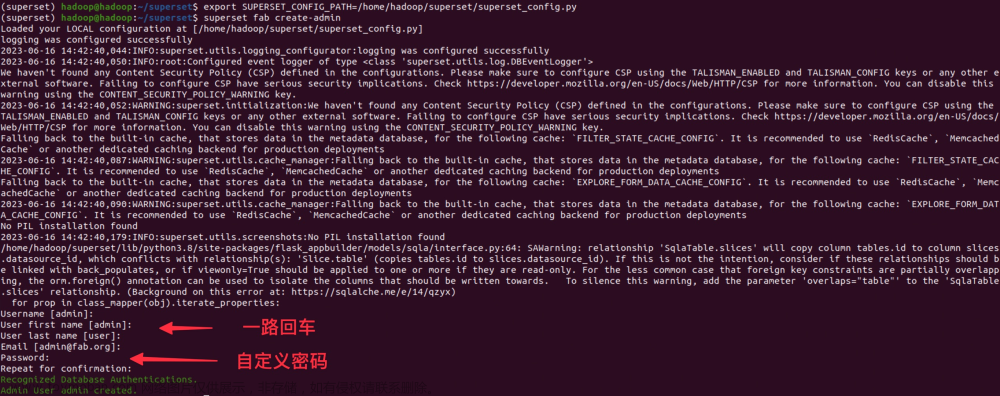
- 报错解决
笔者在执行命令的过程中出现如下报错: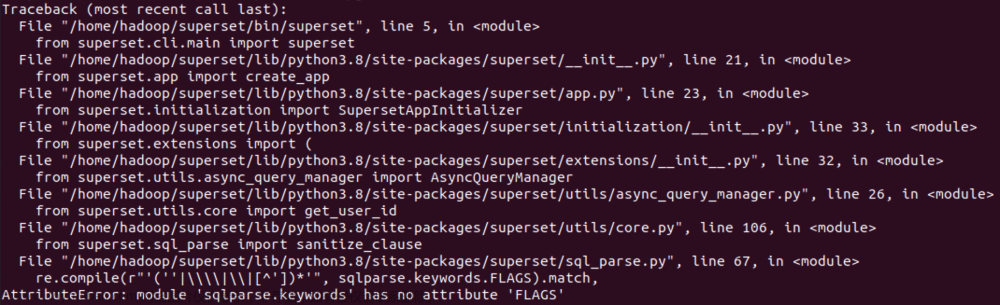
这是由于 sqlparse 不兼容导致的,默认安装了0.4.4,可以通过以下命令确认版本:
pip show sqlparse
此时需要降级到0.4.3,这是由于我目前安装的superset限制版本区间最低为0.4.3,如果大家选择了其它的版本请根据实际情况处理:
pip uninstall sqlparse
pip install sqlparse==0.4.3
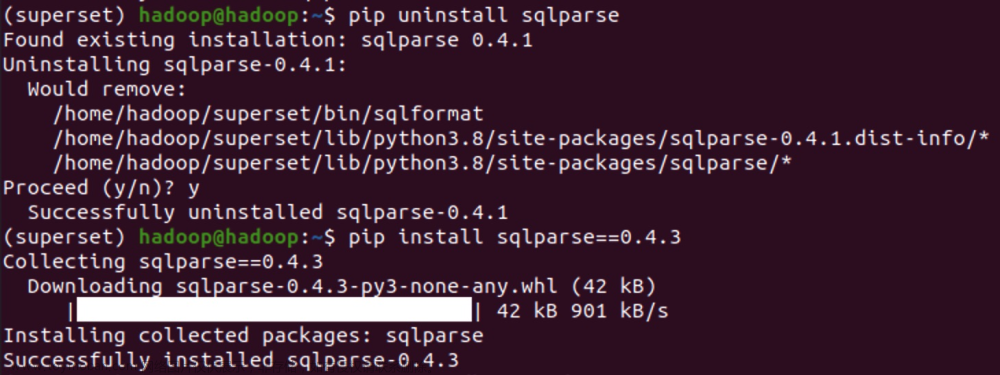
3. 启动访问
前面的初始化步骤完成后可以导入一些样例数据,然后进行启动,在执行所有操作前需要先进行初始化。
- 导入样例数据
# 初始化命令
superset db upgrade
# 加载数据,耗时较长
superset load_examples
- superset构建
首先需要下载前端项目的源代码,然后确保系统已经安装了Node环境。小编当前使用的版本要求node 16.9.1以上,npm 7.5.4 || 8.1.2 以上,这里以安装node 16.x为例。
git clone https://github.com/apache/superset.git
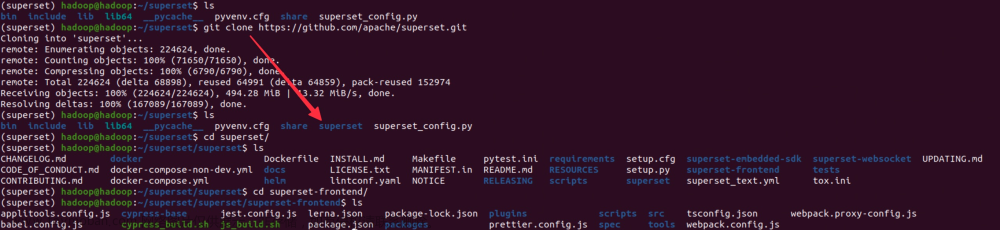
强烈提醒:请保证NodeJS的大版本一致,否则需要自己想办法解决各种构建问题。如果遇到RpcIpcMessagePortClosedError错误,一般为内存不足导致,请尝试增加内存。
# 安装构建所需环境
sudo apt install curl
curl -fsSL https://deb.nodesource.com/setup_16.x | sudo -E bash -
sudo apt-get install -y nodejs
sudo npm install -g npm@latest
sudo npm install -g node-gyp
# ARM架构需要手动安装chromium-browser
sudo apt install chromium-browser
# 构建前端项目
npm ci
# 预先解决一些构建中遇到的问题
npx update-browserslist-db@latest
# 该步骤耗时较长 - 需要保证可用内存在4GB以上
npm run build
- superset启动
# 切换到superset-frontend的上一级目录
cd ..
superset run -p 8088 --with-threads --reload --debugger
- superset访问
启动后,在浏览器访问8088端口即可,使用此前初始化是设定的密码进行登录:
可以查看到,已经显示了此前导入过的样例:
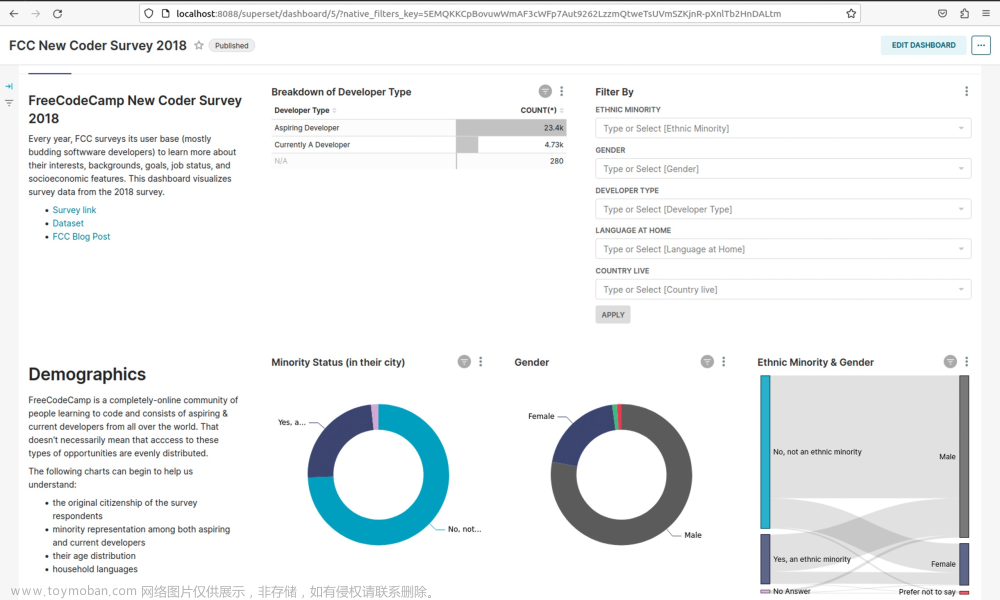
三、数据源配置
在操作界面右上角,支持多种数据源添加方式,本文将介绍数据库连接方式。
1. PostgreSQL
- 依赖安装
在连接PostgreSQL时,需要在项目启动之前,先安装相关依赖。激活superset虚拟环境后执行如下命令:
pip install psycopg2-binary
- 连接配置
在配置界面,默认支持PostgreSQL和SQLite两种直接导入方式: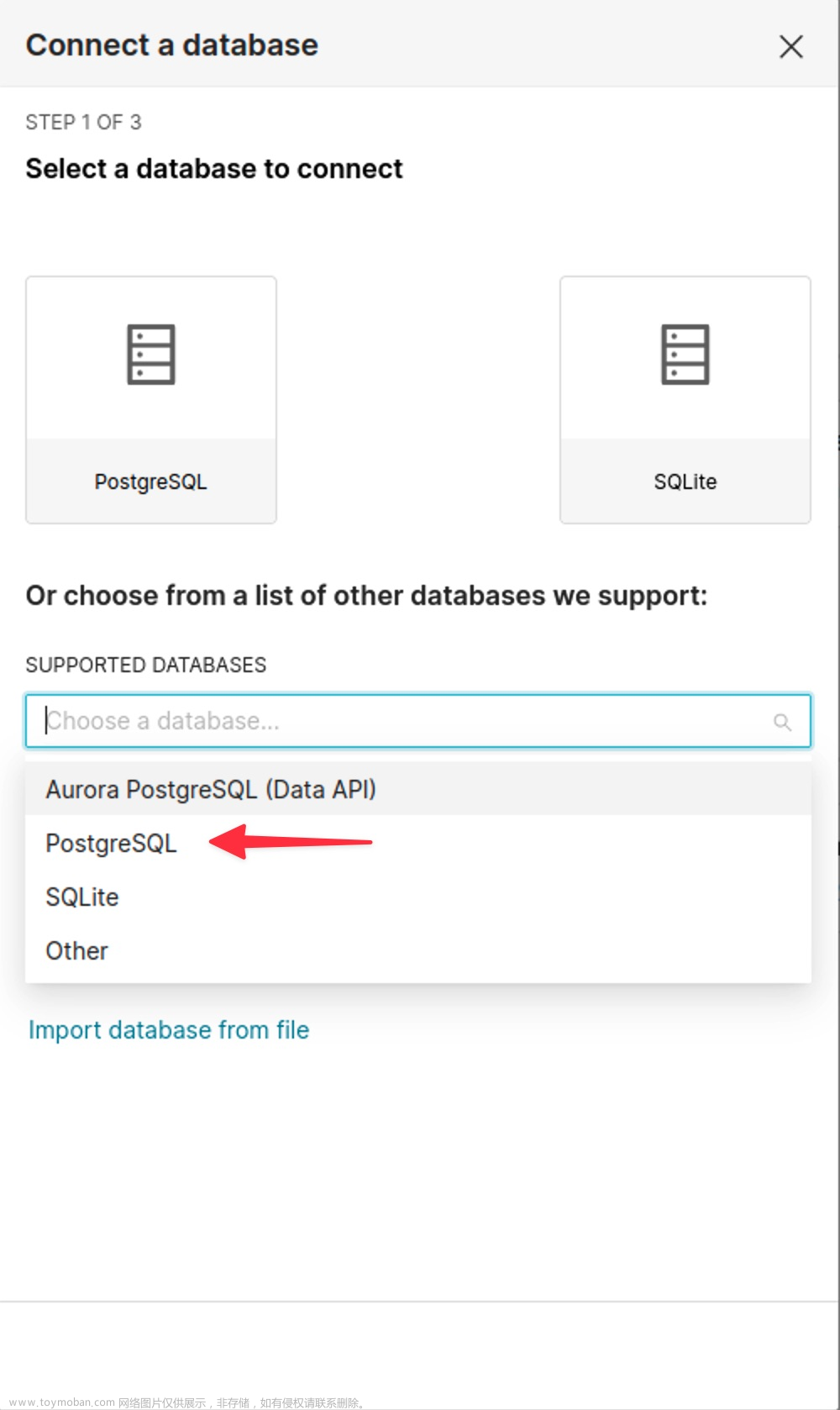
选择PostgreSQL进入配置界面: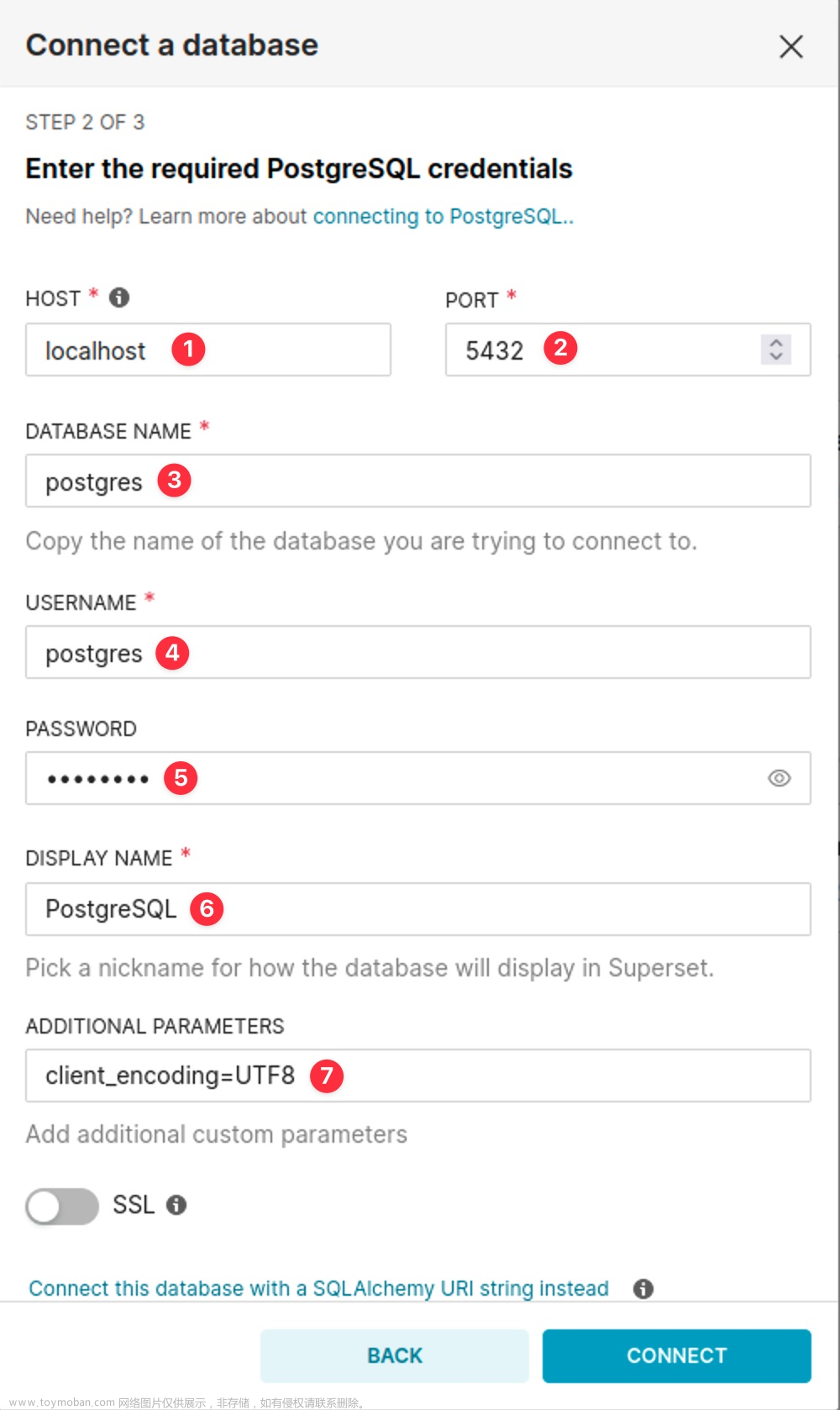
连接成功后,可以开始创建DATASET,或者也可以使用: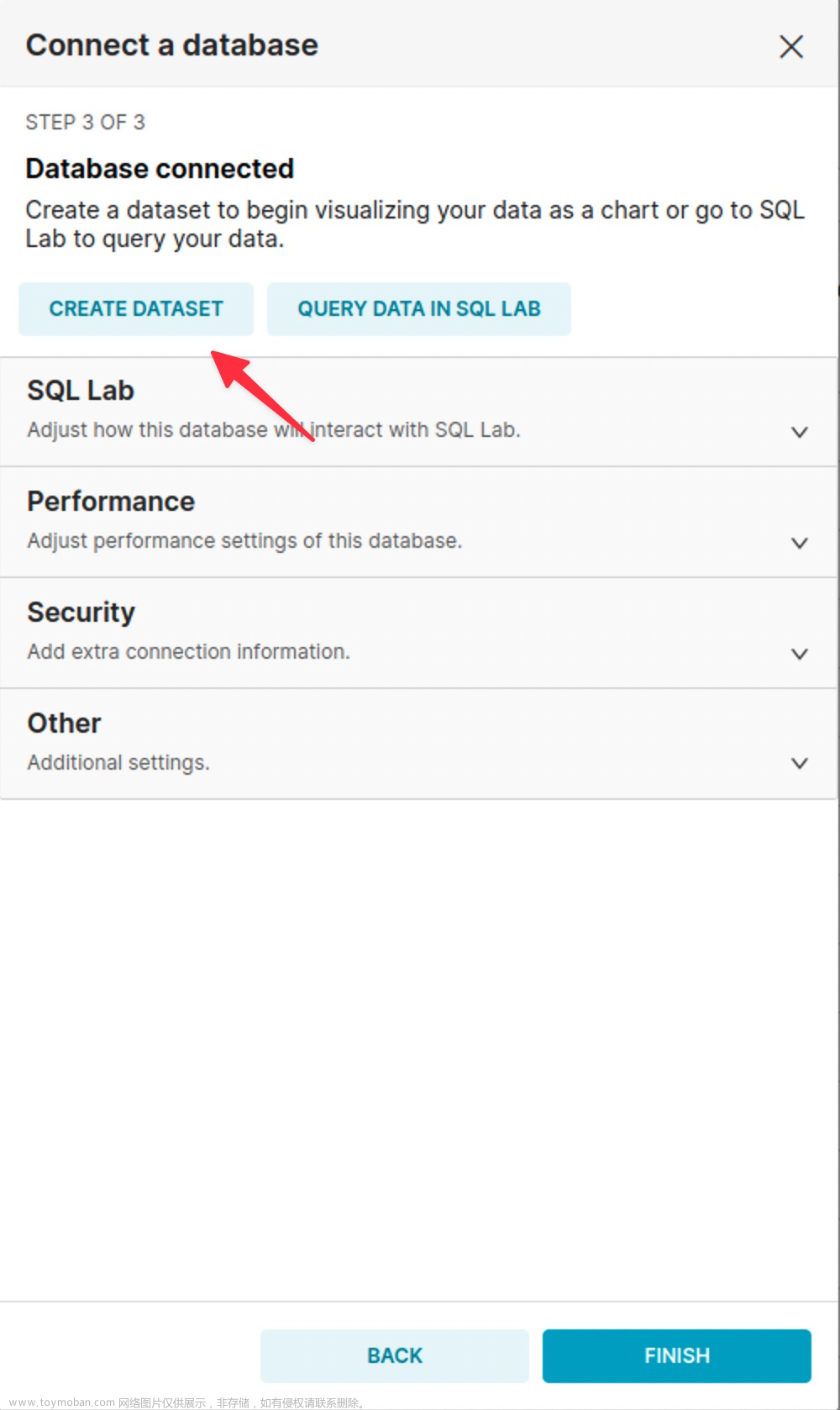
点击FINISH后,再次点击右上角的➕,此时Data选单下出现Create dataset。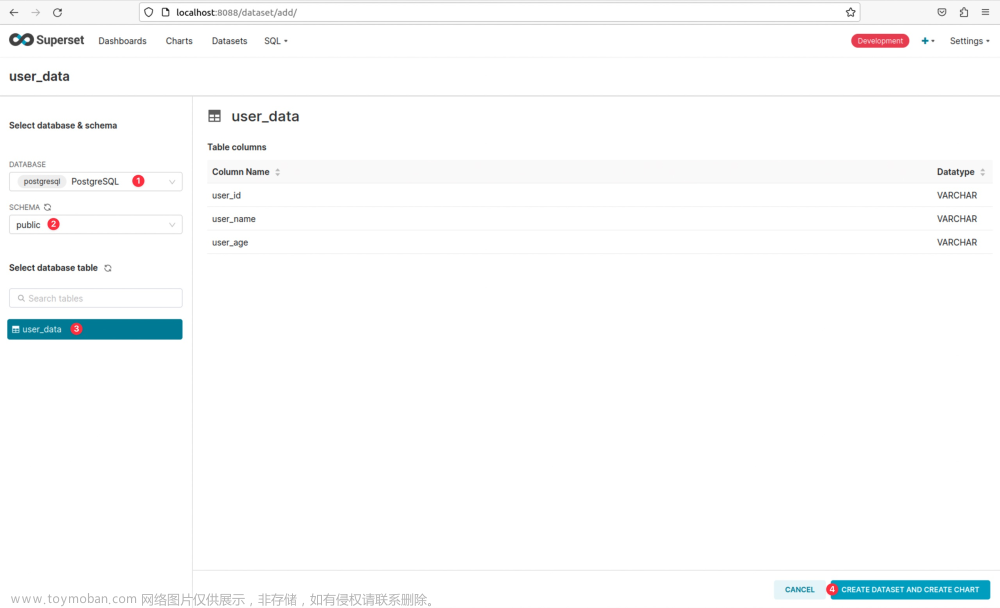
2. MySQL
当已经添加了一个数据库连接后,想要再次添加另外的数据源,可以按照如下步骤操作: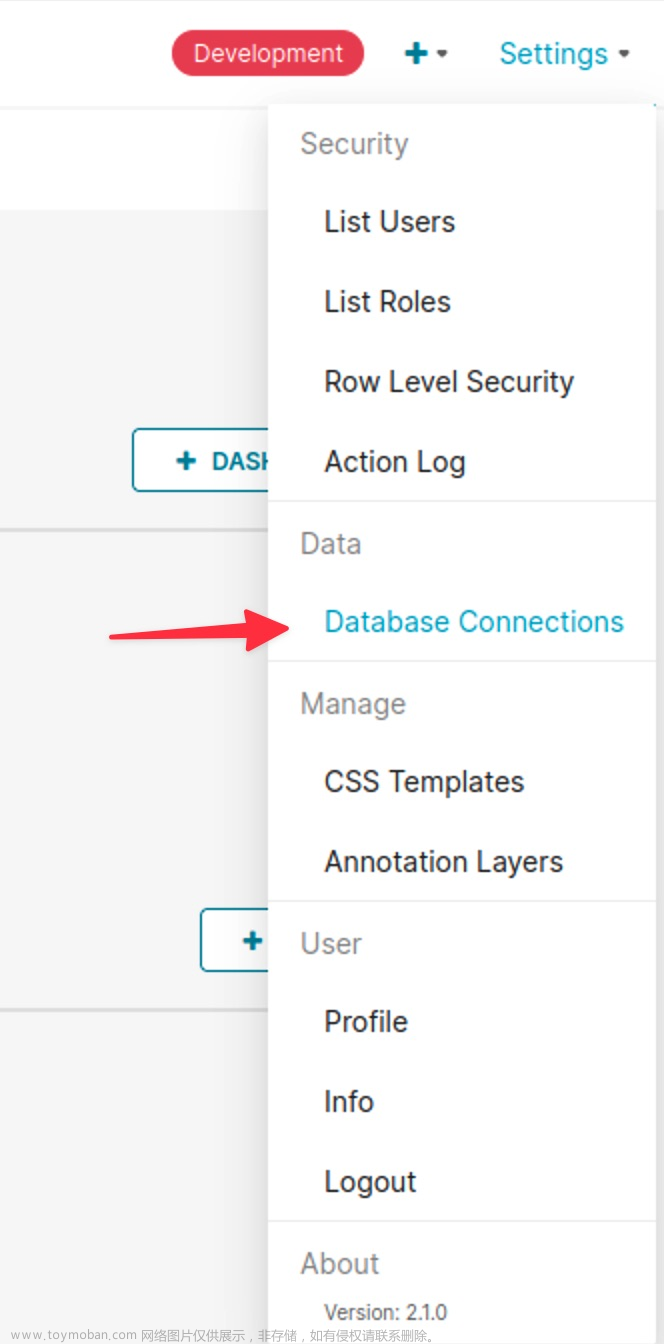
然后在操作界面中可以再次看到添加DATABASE的按钮,如图: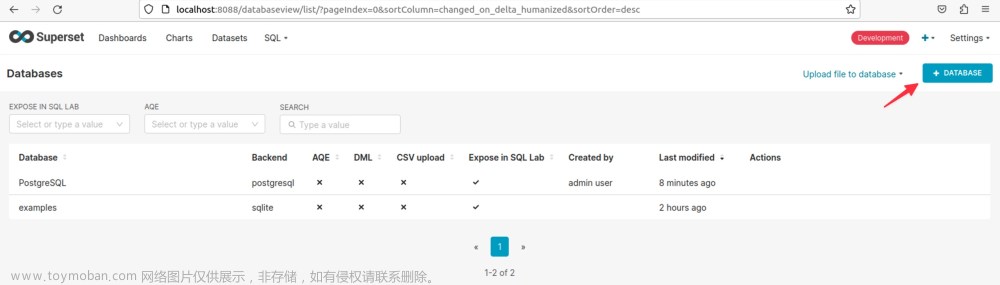
- 依赖安装
在连接MySQL时,需要在项目启动之前,先安装相关依赖。激活superset虚拟环境后执行如下命令:
sudo apt-get install libmysqlclient-dev
pip install mysqlclient
- 连接配置
在配置界面,选择Other,通过连接字符串来直接配置: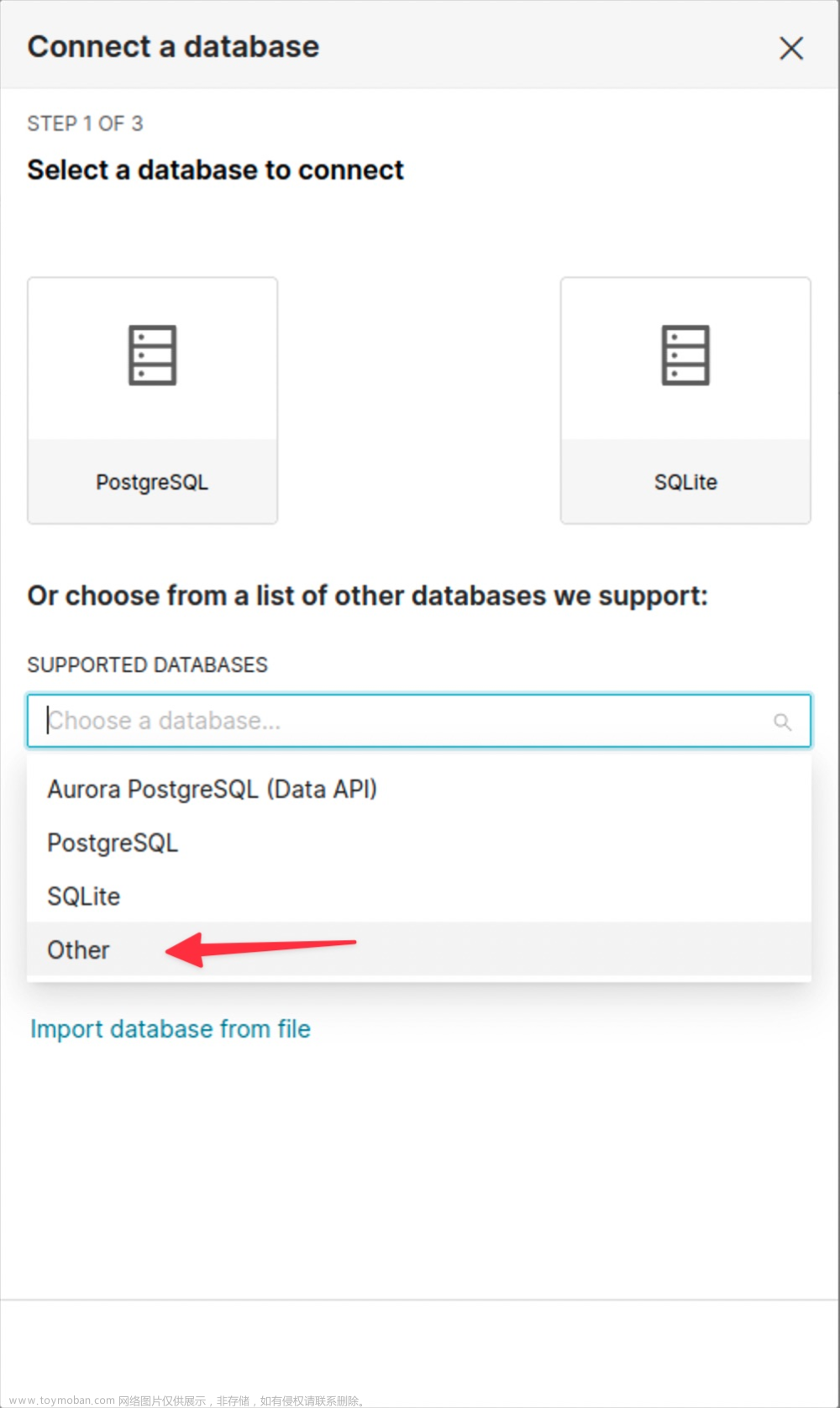
连接字符串为SQLAlchemy URI格式 -> mysql://username:password@hostname:port/database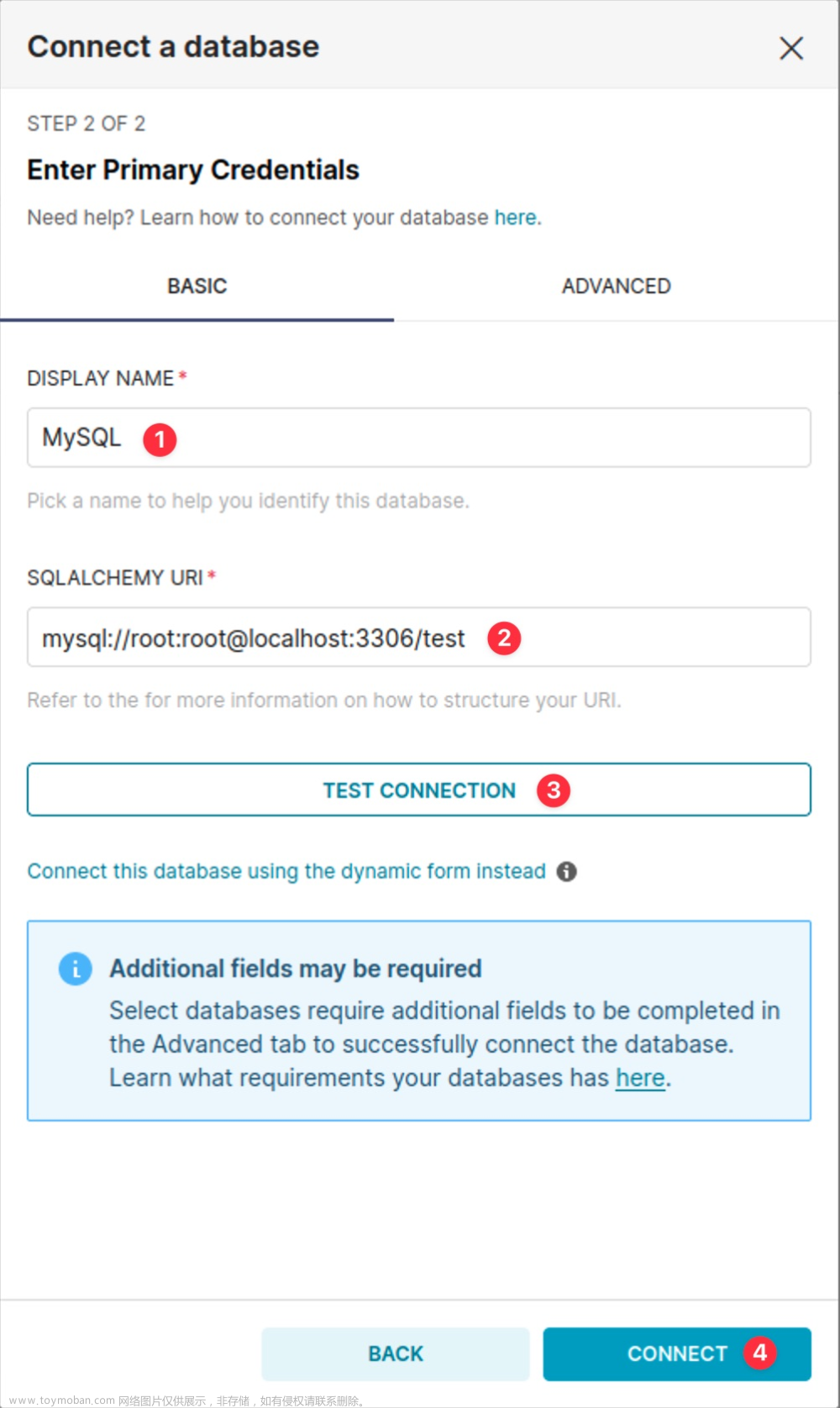
3. Hive
- 依赖安装
在连接Hive时,需要在项目启动之前,先安装相关依赖。激活superset虚拟环境后执行如下命令:
pip install PyMySQL
pip install pyhive
pip install thrift
sudo apt-get install python-dev libsasl2-dev
pip install sasl
pip install thrift_sasl
连接前确保Hive相关服务已经启动,具体步骤可以参考:Hive 3.x的安装部署 - Ubuntu
- 连接配置
在配置界面,选择Other,通过连接字符串来直接配置:
连接字符串为SQLAlchemy URI格式 -> hive://username:password@hostname:port/database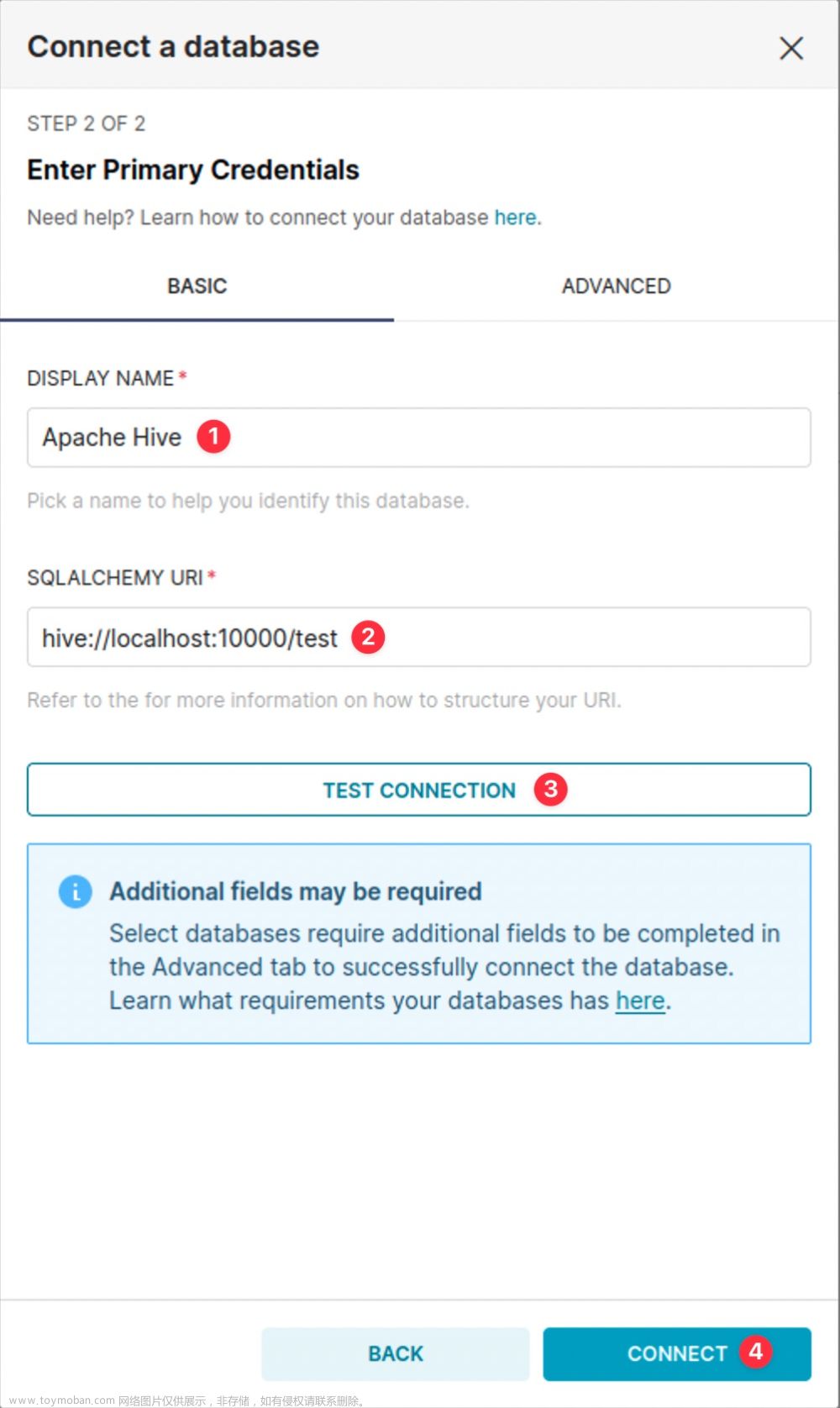
在连接测试通过后,点击CONNECT按钮可能会出现一个无法连接的异常,但是小编实际测试后发现并没有任何影响。此时连接已经成功创建,我们只要将弹窗关闭,然后刷新页面即可,后续的使用也一切正常。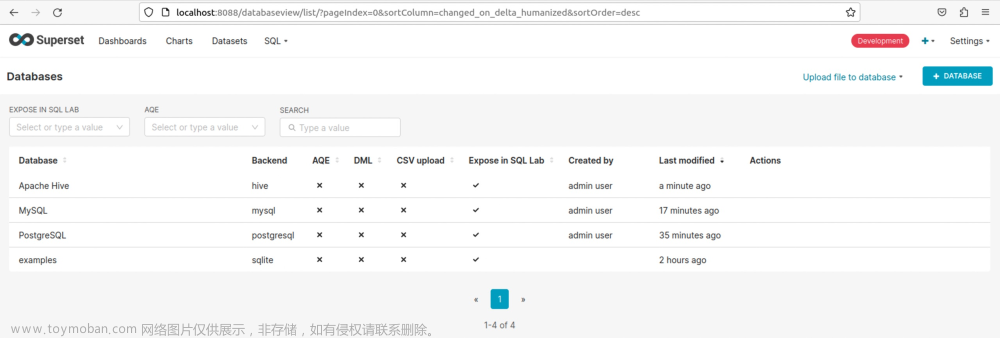
4. 其它说明
当我们不断的向superset的虚拟环境添加各种连接所需的依赖,并且创建相应类型的连接后,操作界面就会变得越来越丰富: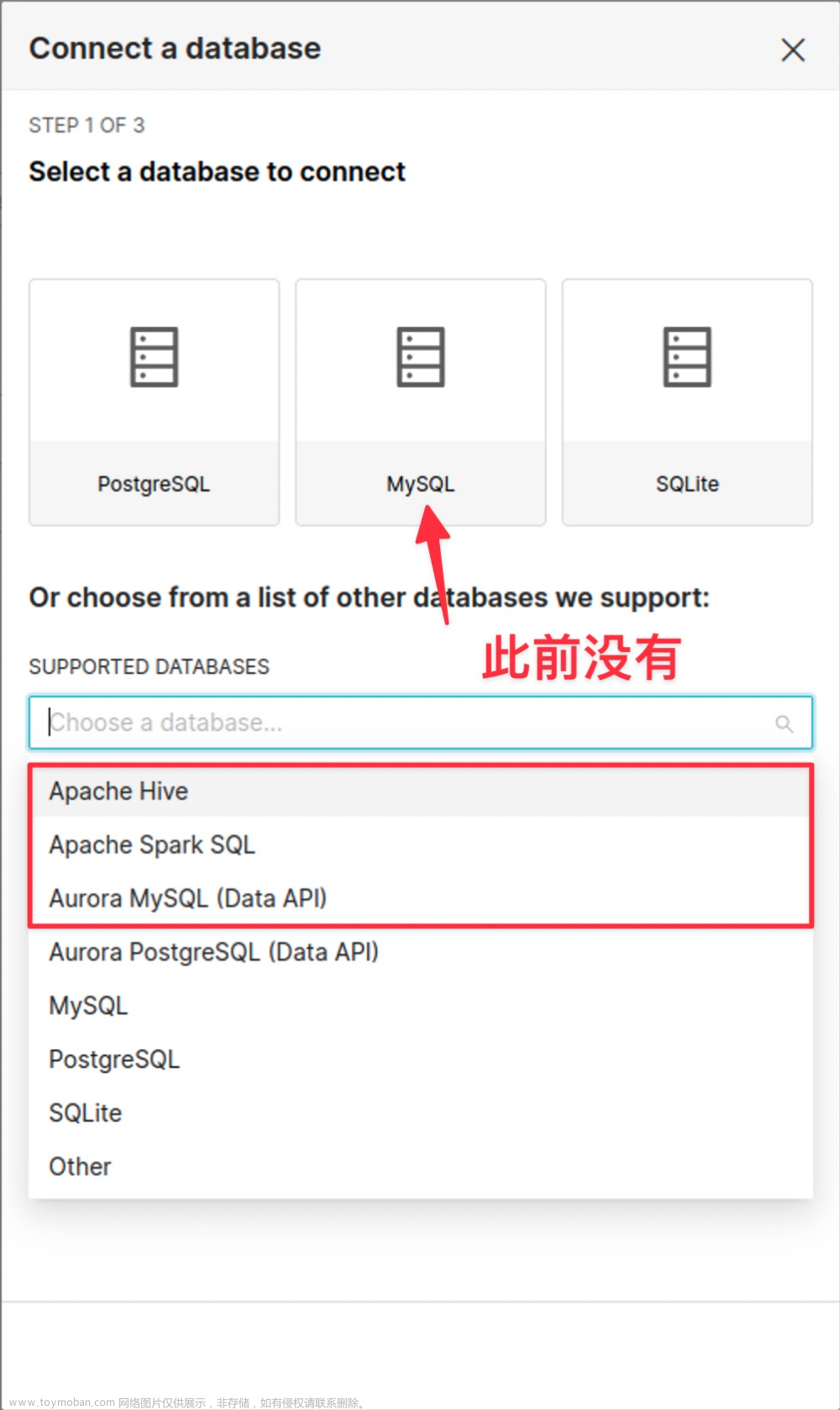
当我们需要的数据源类型基本稳定后,就可以将superset进程挂在后台运行了,这样我们可以专注于可视化的工作:文章来源:https://www.toymoban.com/news/detail-768801.html
# 进入到对应目录后执行
nohup superset run -p 8088 --with-threads --reload --debugger &
扫描下方二维码,加入CSDN官方粉丝微信群,可以与我直接交流,还有更多福利哦~ 文章来源地址https://www.toymoban.com/news/detail-768801.html
文章来源地址https://www.toymoban.com/news/detail-768801.html
到了这里,关于【大数据】可视化仪表板 - Superset的安装和使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!