1、网页端打开酷狗,获取下载音乐列表
- 在音乐列表页面右击鼠标,点击检查,然后依次执行下述步骤


#音乐列表
url='https://complexsearch.kugou.com/v2/search/song?callback=callback123&srcappid=2919&clientver=1000&clienttime=1696859482699&mid=3ed93a0e05225d9e6a0955741b95b6f5&uuid=3ed93a0e05225d9e6a0955741b95b6f5&dfid=2UHyd42Uv4z41usxK348jSHS&keyword=%E5%A4%A7%E9%B1%BC&page=1&pagesize=30&bitrate=0&isfuzzy=0&inputtype=0&platform=WebFilter&userid=0&iscorrection=1&privilege_filter=0&filter=10&token=&appid=1014&signature=75ec3f2e17b9ef335fb8effc389eb642'2、获取每一首音乐的下载地址

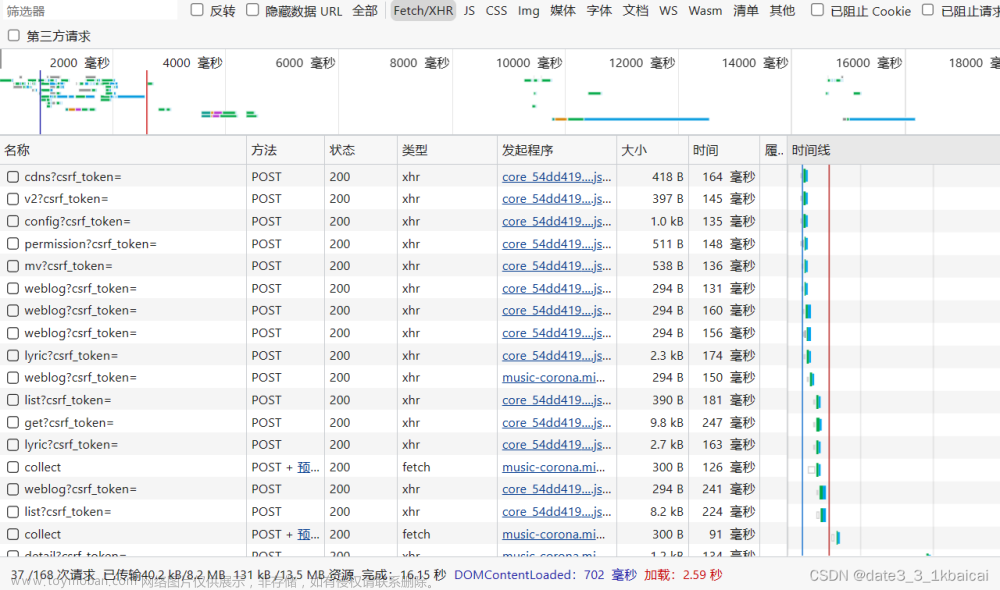
得到这一坨东西

Ctrl+F,查找MP3

在整个网页链接中,后缀用&连接的都是相关级的内容,逐一一段一段的删去&........的内容,直至MP3格式的文件不存在,获得最简的链接

注意,由于酷狗的反爬能力升级,所获得的链接与以前的链接有所不同,不在是&hash
#每一首歌的下载地址
info_url='https://wwwapi.kugou.com/yy/index.phpr=play/getdata&encode_album_audio_id=1genmk88'3、代码行解释
son_list = json.loads(respond.text[12:-2])['data']['lists'] #[12:-2]切片,去除前缀'callback123'和后缀')'其中[12:-2]为切片操作,目的是为了去除下图所示的内容,获得完整的字典


['data'][''lists]为列表中歌曲的信息在'data'列表中‘lists’内

#每一首音乐的下载地址
info_url=f'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&encode_album_audio_id={son_list[num-1].get("EMixSongID")}'由上述可知,每一首歌的下载地址为:
info_url='https://wwwapi.kugou.com/yy/index.phpr=play/getdata&encode_album_audio_id=1genmk88'
encode_album_audio_id:是每首歌特有的音频编码id,通过切换不同的id可以实现各个歌曲的下载
EMixSongID可以通过以下方法找到,此值相当于以前的Filehash值

4、完整代码以及运行结果
""""""
import requests
import json
"""
json.dumps():对数据进行编码,形成json格式的数据。
json.loads():和dumps相反,loads函数则是将json格式的数据解码,转换为Python字典
服务器响应的数据结果 .text代表访问的数据是文字 .content代表访问的数据是多媒体文件(图片,音乐,视频,文件)
.json()代表访问的文字是json类型
"""
#1、音乐的地址
Music_url='https://webfs.hw.kugou.com/202310082002/57c3cce096270de35ea2c764e4e1fd80/part/0/960111/KGTX/CLTX001/clip_bfbdd3df47727b701d4480ea36a8f73b.mp3'
hearders={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47'
}
#音乐列表
url='https://complexsearch.kugou.com/v2/search/song?callback=callback123&srcappid=2919&clientver=1000&clienttime=1696859482699&mid=3ed93a0e05225d9e6a0955741b95b6f5&uuid=3ed93a0e05225d9e6a0955741b95b6f5&dfid=2UHyd42Uv4z41usxK348jSHS&keyword=%E5%A4%A7%E9%B1%BC&page=1&pagesize=30&bitrate=0&isfuzzy=0&inputtype=0&platform=WebFilter&userid=0&iscorrection=1&privilege_filter=0&filter=10&token=&appid=1014&signature=75ec3f2e17b9ef335fb8effc389eb642'
respond=requests.get(url,headers=hearders)
#callback123({"error_msg": "",})
son_list = json.loads(respond.text[12:-2])['data']['lists'] #[12:-2]切片,去除前缀'callback123'和后缀')'
for i,s in enumerate(son_list):
print(f'{i+1}------{s.get("SongName")}-------{s.get("EMixSongID")}') #数据的抽取
num=eval(input('请输入要下载的第几首音乐:'))
#每一首音乐的下载地址
info_url=f'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&encode_album_audio_id={son_list[num-1].get("EMixSongID")}'
hearders2={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47',
'Cookie':'kg_mid=3ed93a0e05225d9e6a0955741b95b6f5; kg_dfid=2UHyd42Uv4z41usxK348jSHS; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1696045928,1696766574; kg_mid_temp=3ed93a0e05225d9e6a0955741b95b6f5; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1696781850'
}
info_resp = requests.get(info_url,headers=hearders2)
m_url=info_resp.json()['data']['play_url']
#2、发送请求到服务器,获取音乐资源
music_respond=requests.get(m_url,headers=hearders)
#3、服务器回应数据--保存数据
with open('1.mp3','wb') as file:
file.write(music_respond.content)

 文章来源:https://www.toymoban.com/news/detail-768902.html
文章来源:https://www.toymoban.com/news/detail-768902.html
 文章来源地址https://www.toymoban.com/news/detail-768902.html
文章来源地址https://www.toymoban.com/news/detail-768902.html
到了这里,关于Python自动爬取酷狗音乐工具的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!