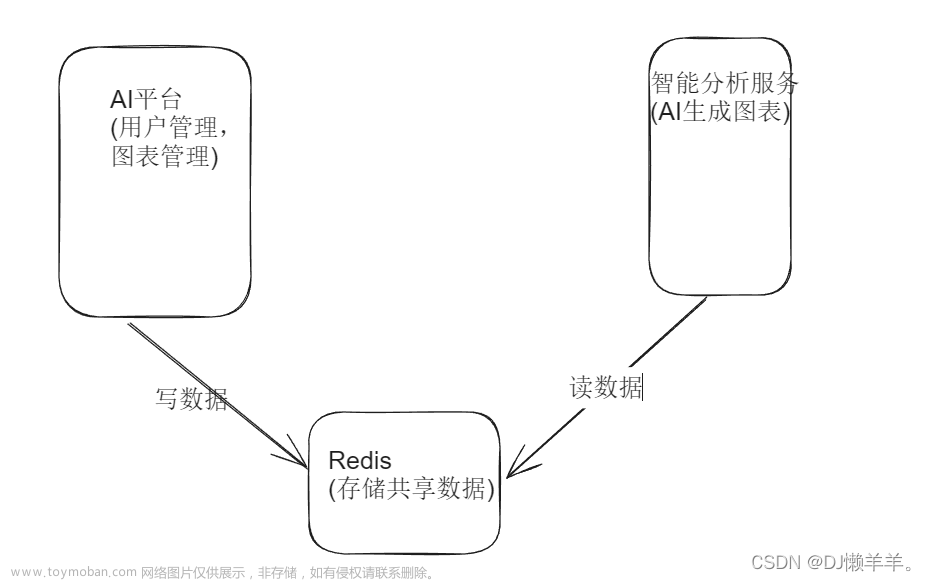
比如我们执行一个很长的任务的时候,执行结束ack确认发现确认失败,mq都断了。
只要是使用pyhon的pika都会出现这个问题,因为pika本身是没有主动发送心跳机制的(你用java的话是没问题的)
解决方式:
在链接中heartbeat=0
credentials = pika.PlainCredentials('xxx','xxx')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host = "xxxx",port = 5672, credentials = credentials , heartbeat=0
))
解决方式2:
我亲自试过,确实有用
改写代码(引用:Python RabbitMQ/Pika 长连接断开报错Connection reset by peer和pop from an empty deque_pika.exceptions.streamlosterror: stream connection-CSDN博客)
"""
@author: Zhigang Jiang
@date: 2022/1/16
@description:
"""
import functools
import pika
import threading
import time
def ack_message(channel, delivery_tag):
print(f'ack_message thread id: {threading.get_ident()}')
if channel.is_open:
channel.basic_ack(delivery_tag)
else:
# Channel is already closed, so we can't ACK this message;
# log and/or do something that makes sense for your app in this case.
pass
def do_work(channel, delivery_tag, body):
print(f'do_work thread id: {threading.get_ident()}')
print(body, "start")
for i in range(10):
print(i)
time.sleep(20)
print(body, "end")
cb = functools.partial(ack_message, channel, delivery_tag)
channel.connection.add_callback_threadsafe(cb)
def on_message(channel, method_frame, header_frame, body):
print(f'on_message thread id: {threading.get_ident()}')
delivery_tag = method_frame.delivery_tag
t = threading.Thread(target=do_work, args=(channel, delivery_tag, body))
t.start()
credentials = pika.PlainCredentials('username', 'password')
parameters = pika.ConnectionParameters('test.webapi.username.com', credentials=credentials, heartbeat=5)
connection = pika.BlockingConnection(parameters)
channel = connection.channel()
channel.queue_declare(queue="standard", durable=True)
channel.basic_qos(prefetch_count=1)
channel.basic_consume('standard', on_message)
print(f'main thread id: {threading.get_ident()}')
try:
channel.start_consuming()
except KeyboardInterrupt:
channel.stop_consuming()
connection.close()
长时间的话,家里的网抖动可能出现,我们家有时候就会断网个10几秒,有时候打游戏就会掉线:文章来源:https://www.toymoban.com/news/detail-769136.html
pika.exceptions.AMQPHeartbeatTimeout: No activity or too many missed heartbeats in the last xx seconds
这种情况,把他拉起就行了,加一个文章来源地址https://www.toymoban.com/news/detail-769136.html
while True:
try:
# 用户名密码,没有设置的可以省略这一步
credentials = pika.PlainCredentials('xx', 'xx')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host="xxxx", port=5672, credentials=credentials, heartbeat=10
))
channel = connection.channel()
channel.queue_declare(queue="xxx", durable=True) # 如果是持久化队列就是True
channel.basic_qos(prefetch_count=1)
channel.basic_consume("xxx", on_message)
print(f'main thread id: {threading.get_ident()}')
print("开始消费")
channel.start_consuming()
except KeyboardInterrupt:
# channel.stop_consuming()
print("出现异常,可能是网络原因,重新启动"+e)
time.sleep(30)到了这里,关于使用python的pika链接rabbitMq断裂的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!