CFG
AIGC神功_SD采样方法与CFG_大猫404-站酷ZCOOLAIGC神功_SD采样方法与CFG,成都设计爱好者,站酷网,中国设计师互动平台.爱卿们好!本喵又出现了~熟悉的封面有没有把你吸引进来呢?这次让我们继续来讲AIGC的内容哟,这是篇硬核科普~https://www.zcool.com.cn/article/ZMTU0OTI0MA==.html
马尔可夫链
马尔可夫链 ▏小白都能看懂的马尔可夫链详解点击蓝字关注我们1.什么是马尔可夫链 在机器学习算法中,马尔可夫链(Markov chain)是个很重要的概https://mp.weixin.qq.com/s?__biz=MzU0MDQ1NjAzNg==&mid=2247568069&idx=1&sn=8d0d44b4a4f939ff37cbda62bef9d26a&chksm=fb3b6fcecc4ce6d88a38e767c20ec9afdbc6901188489e80f2f2e4fa96fcd0043ee380224777&scene=27简述马尔可夫链【通俗易懂】 - 知乎马尔可夫链前言马尔可夫链(Markov Chain)可以说是机器学习和人工智能的基石,在强化学习、自然语言处理、金融领域、天气预测、语音识别方面都有着极其广泛的应用 The future is independent of the past given t…https://zhuanlan.zhihu.com/p/448575579
stable diffusion的前传:
轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型 - 知乎近两年,有许多图像生成类任务的前沿工作都使用了一种叫做"codebook"的机制。追溯起来,codebook机制最早是在VQ-VAE论文中提出的。相比于普通的VAE,VQ-VAE能利用codebook机制把图像编码成离散向量,为图…https://zhuanlan.zhihu.com/p/633744455
VQGAN是一个改进版的VQVAE,它将感知误差和GAN引入了图像压缩模型,把压缩图像生成模型替换成了更强大的Transformer。相比纯种的GAN(如StyleGAN),VQGAN的强大之处在于它支持带约束的高清图像生成。VQGAN借助NLP中"decoder-only"策略实现了带约束图像生成,并使用滑动窗口机制实现了高清图像生成。虽然在某些特定任务上VQGAN还是落后于其他GAN,但VQGAN的泛化性和灵活性都要比纯种GAN要强。它的这些潜力直接促成了Stable Diffusion的诞生。
如果你是读完了VQVAE再来读的VQGAN,为了完全理解VQGAN,你只需要掌握本文提到的4个知识点:VQVAE到VQGAN的改进方法、使用Transformer做图像生成的方法、使用"decoder-only"策略做带约束图像生成的方法、用滑动滑动窗口生成任意尺寸的图片的思想。
VQGAN 论文与源码解读:前Diffusion时代的高清图像生成模型 - 知乎2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVA…https://zhuanlan.zhihu.com/p/637705399?utm_id=0
改进版的vqgen:maskgit
[CVPR2022]MaskGIT: Masked Generative Image Transformer阅读笔记 - 知乎arxiv: MaskGIT: Masked Generative Image Transformergithub: google-research/maskgit: Official Jax Implementation of MaskGIT (github.com)笔记链接: https://occipital-aphid-dee.notion.site/MaskGIT-Ma…https://zhuanlan.zhihu.com/p/618235198
stable diffusion:
stable diffusion原理解读通俗易懂,史诗级万字爆肝长文,喂到你嘴里 - 知乎个人网站一、前言(可跳过)hello,大家好我是 Tian-Feng,今天介绍一些stable diffusion的原理,内容通俗易懂,因为我平时也玩Ai绘画嘛,所以就像写一篇文章说明它的原理,这篇文章写了真滴挺久的,如果对你有用…https://zhuanlan.zhihu.com/p/634573765
文生图相关的一些原理:
https://zhuanlan.zhihu.com/p/645939505前言传送门: stable diffusion:Git|论文 stable-diffusion-webui:Git Google Colab Notebook部署stable-diffusion-webui:Git kaggle Notebook部署stable-diffusion-webui:Git今年AIGC实在是太火了,让人大呼…https://zhuanlan.zhihu.com/p/645939505
stable diffusion的相关介绍与代码展示:CLIP text encoder、UNet、文生图、文生视频、inpainting
https://zhuanlan.zhihu.com/p/617134893通向AGI之路码字真心不易,求点赞! https://zhuanlan.zhihu.com/p/6424968622022年可谓是 AIGC(AI Generated Content)元年,上半年有文生图大模型DALL-E2和Stable Diffusion,下半年有OpenAI的文本对话大模型Ch…https://zhuanlan.zhihu.com/p/617134893
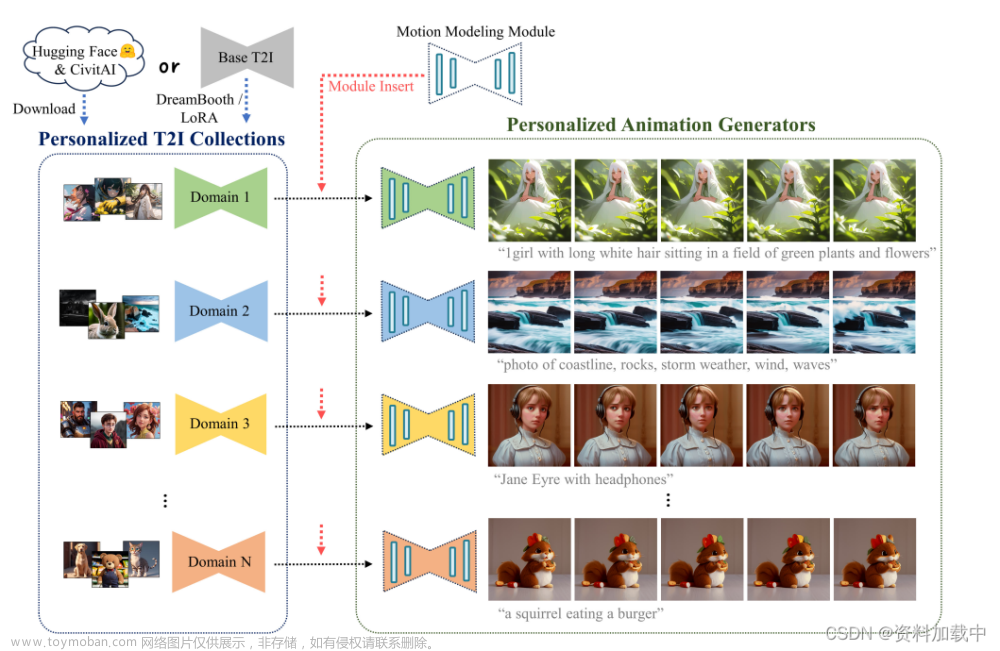
AnimateDiff:
https://blog.csdn.net/qq_41994006/article/details/132011849
https://blog.csdn.net/shadowcz007/article/details/131757666
https://www.zhihu.com/pin/1685665464804700161
部署:https://blog.csdn.net/weixin_51330846/article/details/133795764
https://huggingface.co/guoyww/animatediff/discussions/5
Dreambooth
https://zhuanlan.zhihu.com/p/620577688这个系列会分享下stable diffusion中比较常用的几种训练方式,分别是Dreambooth、textual inversion、LORA和Hypernetworks。在 https://civitai.com/选择模型时也能看到它们的身影。本文该系列的第一篇Dreambooth1…https://zhuanlan.zhihu.com/p/620577688
Reuse-And-Diffuse
ReuseAndDiffuse笔记-CSDN博客文章浏览阅读111次。Long video classification datasets:一些较长的视频,如VideoLT数据集,用MiniGPT-4等大模型,来先分类出哪些帧是可以剪出来用的,然后再理解这些帧。平常的stable-diffusion,是图片的解码器,这样的话帧间还是有差别的,文章在解码器中间也加入了Temp-Conv,以提高帧间的连贯性。对于Unet,每层都加入两个可训练的,包含时间维度的层,Temp-Conv是针对视频数据的三维卷积,Temp-Attn是时间维度上的注意力机制。https://blog.csdn.net/pc9803/article/details/134131805?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22134131805%22%2C%22source%22%3A%22pc9803%22%7D
phenaki
GitHub - lucidrains/phenaki-pytorch: Implementation of Phenaki Video, which uses Mask GIT to produce text guided videos of up to 2 minutes in length, in PytorchImplementation of Phenaki Video, which uses Mask GIT to produce text guided videos of up to 2 minutes in length, in Pytorch - GitHub - lucidrains/phenaki-pytorch: Implementation of Phenaki Video, which uses Mask GIT to produce text guided videos of up to 2 minutes in length, in Pytorchhttps://github.com/lucidrains/phenaki-pytorchhttps://huggingface.co/obvious-research/phenaki-cvivit/tree/mainhttps://huggingface.co/obvious-research/phenaki-cvivit/tree/main
【项目部署调试】 AnimateDiff-CSDN博客文章浏览阅读674次。717行,原来是直接改为路径本来,一切到这就结束了,可是726行却总是报错原本是百思不得其解,知道在 github 的 issue 里的某个问题的某个评论看到了改为OK ,结束,跑起来了~p.s. 按照默认的16帧跑要12G显存。https://blog.csdn.net/weixin_51330846/article/details/133795764
maskgit
自回归解码加速64倍,谷歌提出图像合成新模型MaskGIThttps://m.thepaper.cn/baijiahao_17087787
[CVPR2022]MaskGIT: Masked Generative Image Transformer阅读笔记 - 知乎arxiv: MaskGIT: Masked Generative Image Transformergithub: google-research/maskgit: Official Jax Implementation of MaskGIT (github.com)笔记链接: https://occipital-aphid-dee.notion.site/MaskGIT-Ma…https://zhuanlan.zhihu.com/p/618235198
ViViT
ViViT: A Video Vision Transformer阅读和代码 - 知乎文章地址: https://arxiv.org/pdf/2103.15691.pdf文章代码: https://github.com/google-research/scenic/tree/main/scenic/projects/vivit依旧是Google的作品,Google算法上确实是领跑世界。在视频理解上使用了T…https://zhuanlan.zhihu.com/p/506607332(动作分类篇)ViViT: A Video Vision Transformer - 知乎在阅读完VT综述后的第一篇正式的视频理解论文阅读笔记,ViViT作为纯transformer结构,在动作分类方向提出了四个模型,以及不同的embedding和参数初始化方式等等,并且做了丰富的实验。接下来直接从模型介绍开始总…https://zhuanlan.zhihu.com/p/505287712【ViViT】A Video Vision Transformer 用于视频数据特征提取的ViT详解_vit 视频_萝卜社长的博客-CSDN博客文章浏览阅读2.5k次,点赞5次,收藏36次。VIVIT详解_vit 视频https://blog.csdn.net/lym823556031/article/details/127939000文章来源:https://www.toymoban.com/news/detail-769141.html
IQA--VQA
不同的图像质量评价指标(IQA)_LanceHang的博客-CSDN博客文章浏览阅读800次。NRQM(Non-Reference Quality Metric)是一种非参考图像质量评价指标,用于自动评估图像的质量,而不需要参考图像(即原始或真实图像)。总的来说,NIMA 是一种基于深度学习的图像质量评价方法,它利用深度CNN模型从图像中提取特征,并能够输出图像的质量分数,使其成为自动化图像质量评估的有力工具。LPIPS 在计算机视觉和图像处理领域中被广泛应用,特别是在图像生成、超分辨率、图像风格迁移等任务中,用于评估生成的图像与原始图像之间的相似性和质量。https://blog.csdn.net/LanceHang/article/details/132802874文章来源地址https://www.toymoban.com/news/detail-769141.html
到了这里,关于AIGC-文生视频的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!