流处理API的衍变
Storm:TopologyBuilder构建图的工具,然后往图中添加节点,指定节点与节点之间的有向边是什么。构建完成后就可以将这个图提交到远程的集群或者本地的集群运行。Flink:不同之处是面向数据本身的,会把DataStream抽象成一个本地集合,通过面向集合流的编程方式进行代码编写。两者没有好坏之分,Storm比较灵活自由。更好的控制。在工业界Flink会更好点。开发起来比较简单、高效。经过一些列优化、转化最终也会像Storm一样回到底层的抽象。Strom API是面向操作的,偏向底层。Flink面向数据,相对高层次一些。
流处理的简单流程
其他分布式处理引擎一样,Flink应用程序也遵循着一定的编程模式。不管是使用DataStream API还是DataSet API基本具有相同的程序结构,如下代码清单所示。通过流式计算的方式实现对文本文件中的单词数量进行统计,然后将结果输出在给定路径中。
public class FlinkWordCount {
public static void main(String[] args) throws Exception {
// 1、获取运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、通过socket获取源数据
DataStreamSource<String> sourceData = env.socketTextStream("192.168.52.12", 9000);
/**
* 3、数据源进行处理
* flatMap方法与spark一样,对数据进行扁平化处理
* 将每行的单词处理为<word,1>
*/
DataStream<Tuple2<String, Integer>> dataStream = sourceData.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2<String, Integer>(word, 1));
}
}
})
// 相同的单词进行分组
.keyBy(0)
// 聚合数据
.sum(1);
// 4、将数据流打印到控制台
dataStream.print();
/**
* 5、Flink与Spark相似,通过action进行出发任务执行,其他的步骤均为lazy模式
* 这里env.execute就是一个action操作,触发任务执行
*/
env.execute("streaming word count");
}
}
整个Flink程序一共分为5步,分别为设定Flink执行环境、创建和加载数据集、对数据集指定转换操作逻辑、指定计算结果输出位置、调用execute方法触发程序执行。对于所有的Flink应用程序基本都含有这5个步骤,下面将详细介绍每个步骤。
操作概览
如果给你一串数据你会怎么去处理它?
【1】基于单条记录进行Filter、Map
【2】基于窗口window进行计算,例如小时数,看到的就不一定是单数。
【3】有时会可能会合并多条流union(多个数据流合并成一个大的流)、Join(多条流按照一定的条件进行合并)、connect(针对多种不同类型的流进行合并)。
【4】有时候需要将一条流拆分成多个流,例如split,然后针对特殊的流进行特殊操作。
DataStream 基本转换

【1】对DataStream进行一对一转换,输入是SataStream输出也是DataStream。比较有代表性的,例如map;
【2】将一条DataStream拆分成多条,例如使用split,并给划分后的每一个结果都打上一个标签;
【3】通过调用SplitStream对象的select方法,根据标签抽取一个感兴趣的流,它也是一个DataStream对象。
【4】把两条流通过connect合并成一个ConnectedSteam,对ConnectedSteam流的操作可能与DataStream流的操作有不太一样的地方。ConnectedSteam中不同类型的流在处理的时候对应不同的 process 方法,他们都位于同一个 function中,会存在一些共享的数据信息。我们在后期做一些底层的join操作的时候都会用到这个ConnectedSteam。
【5】对ConnectedSteam也可以做类似于Map的一些操作,它的操作名叫coMap,但是在API中写法是Map。
【6】我们可以对流按照时间或者个数进行一些切分,可以理解为将无线的流分成一个一个的单位流,怎么切分根据用户自定的逻辑决定的。例如调用windowAll生成一个AllWindowedStream。
【7】我们对AllWindowedStream去应用自己的一些业务逻辑apply,最终形成原始的DataStream。
【8】对DataStream进行keyBy进行分组操作形成KeyedStream。
【9】我们不能对普通的DataStream做reduce操作,只能对KeyedStream进行reduce。主要出于计算量的考虑。
【10】我们也可以对KeyedStream进行window 操作形成WindowedStream。
【11】我们对WindowedStream进行apply操作,形成原始的DataStream操作。
Environment 执行环境
【1】getExecutionEnvironment:创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,与就是说,执行环境决定了程序执行在什么环境 getExecutionEnvironment会根据查询运行的方式返回不同的运行环境,是最常用的一种创建执行环境的方式。批量处理作业和流式处理作业分别使用的是不同的ExecutionEnvironment。例如StreamExecutionEnvironment是用来做流式数据处理环境,ExecutionEnvironment是批量数据处理环境。
//流处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//块梳理
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
如果没有设置并行度,会以flink-conf.yaml中的配置为准,默认为1:parallelism.default:1
//可以设置并行度(优先级最高)
env.setParallelism(1);
如果是本地执行环境底层调用的是createLocalEnvironment:需要在调用时指定默认的并行度
val env = StreamExecutionEnvironment.createLocalEnvironment(1)
如果是集群执行环境createRemoteEnvironment:将Jar提交到远程服务器,需要在调用时指定JobManager的IP和端口号,并指定要在集群中运行的Jar包。flink将这两种都进行了包装,方便我们使用。
var env = ExecutionEnvironment.createRemoteEnvironment("jobmanager-hostname",6123,"YOURPATH//wordcount.jar")
Source 初始化数据
创建完成ExecutionEnvironment后,需要将数据引入到Flink系统中。ExecutionEnvironment提供不同的数据接入接口完成数据的初始化,将外部数据转换成DataStream或DataSet数据集。如以下代码所示,通过调用readTextFile()方法读取file:///pathfile路径中的数据并转换成DataStream数据集。我们可以吧streamSource看做一个集合进行处理。
//readTextFile读取文本文件的连接器 streamSource 可以想象成一个集合
DataStreamSource<String> streamSource = env.readTextFile("file:///path/file");
//从集合中读取数据 scala
val stream1: DataStream[类] = env.fromCollection(list(类,类))
//socket文本流 使用的比较少
val stream3 = env.socketTextStream("localhost",777);
//直接传数据,测试用,可以传入任何数据类型,最终会转化为 TypeInformation
val stream5 = env.fromElements(1,4,"333");
/**重要,常见的是从 kafka 中读取,需要引入插件。
*<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.11 -->
*<dependency>
* <groupId>org.apache.flink</groupId>
* <artifactId>flink-connector-kafka-0.11_2.12</artifactId>
* <version>1.10.0</version>
*</dependency>
*/
// kafkaConsumer 需要的配置参数
val props = new Properties()
// 定义kakfa 服务的地址,不需要将所有broker指定上
props.put("bootstrap.servers", "hadoop1:9092")
// 制定consumer group
props.put("group.id", "test")
// 是否自动确认offset
props.put("enable.auto.commit", "true")
// 自动确认offset的时间间隔
props.put("auto.commit.interval.ms", "1000")
// key的序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
// value的序列化类
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
//从kafka读取数据,需要实现 SourceFunction 他给我们提供了一个
env.addSource(new FlinkKafkaConsumer011[String]("sensor",new SimpleStringSchema(),props));
Flink输出至Reids、Flink输出至ES、Flink输入输出至Kafka;
通过读取文件并转换为DataStream[String]数据集,这样就完成了从本地文件到分布式数据集的转换,同时在Flink中提供了多种从外部读取数据的连接器,包括批量和实时的数据连接器,能够将Flink系统和其他第三方系统连接,直接获取外部数据。批处理读取文件的时候,是读取完之后进行输出的。流处理是读一个处理一个。Topic测试:启动zk、kafka并创建Topic="sensor"
[root@hadoop3 kafka_2.11-2.2.2]# ./bin/kafka-console-producer.sh --broker-list hadoop2:9092 --topic sensor
>333
Idea项目启动后,就会接收到传送过来的信息:
用户自定义一个数据来源类针对特殊的数据源,或者制造测试数据。这里重要针对测试数据。
package com.zzx.flink
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import scala.util.Random
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 创建一个流处理执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 添加用户定义的数据源
val stream5 = env.addSource(new MySensorSource())
stream5.print();
//上面的只是定义了处理流程,同时定义一个名称。不会让任务结束
env.execute("stream word count word")
}
//实现一个自定义的 SourceFunction,自动生成测试数据
class MySensorSource() extends SourceFunction[SensorReading]{
//定义一个 flag,表示数据源是否正常运行
var running: Boolean = true;
//运行,不停的通过 ctx 发出需要流式处理的数据,现在我们直接在内部生成
override def run(sourceContext: SourceFunction.SourceContext[SensorReading]): Unit = {
//定义一个随机数发生器
val rand = new Random()
//随机生成10个传感器的问题值,并且不断在之前温度基础上更新(随机上下波动)
//首先生成10个传感器的初始温度
var curTemps = 1.to(10).map(
i => ("sensor_"+i,60 + rand.nextGaussian()*10)
)
//无线循环,生成随机数据流
while(running){
//在当前文段基础上,随机生成微小波动
curTemps = curTemps.map(
data => (data._1,data._2+rand.nextGaussian())
)
//获取当前系统时间
val curTs = System.currentTimeMillis()
//包装成样例,用 ctx发出数据
curTemps.foreach(
data => sourceContext.collect(SensorReading(data._1,curTs,data._2))
)
//定义间隔时间
Thread.sleep(1000);
}
}
//停止
override def cancel(): Unit = running = false
}
case class SensorReading(id: String, timestamp: Long, temperature: Double)
}
输出结果展示:
Transform 执行转换操作
Transform可以理解为从source开始到sink输出之间的所有操作都是Transform。数据从外部系统读取并转换成DataStream或者DataSet数据集后,下一步就将对数据集进行各种转换操作。Flink中的Transformation操作都是通过不同的Operator来实现,每个Operator内部通过实现 Function接口完成数据处理逻辑的定义。在DataStream API和DataSet API提供了大量的转换算子,例如map(一个输入一个输出转换)、flatMap(将数据打散,一个输入多个输出)、filter(添加过滤条件)、keyBy等,用户只需要定义每种算子执行的函数逻辑,然后应用在数据转换操作Dperator接口中即可。如下代码实现了对输入的文本数据集通过FlatMap算子转换成数组,然后过滤非空字段,将每个单词进行统计,得到最后的词频统计结果。
DataStream<Tuple2<String, Integer>> dataStream = sourceData.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2<String, Integer>(word, 1));
}
}
// keyBy 相同的单词进行分组,sum聚合数据
}).keyBy(0).sum(1);
在上述代码中,通过 Java接口处理数据,极大地简化数据处理逻辑的定义,只需要通过传入相应Lambada计算表达式,就能完成Function定义。特殊情况下用户也可以通过实现Function接口来完成定义数据处理逻辑。然后将定义好的Function应用在对应的算子中即可。Flink中定义Funciton的计算逻辑可以通过如下几种方式完成定义。
【1】通过创建Class实现Funciton接口Flink中提供了大量的函数供用户使用,例如以下代码通过定义MyMapFunction Class实现MapFunction接口,然后调用DataStream的map()方法将MyMapFunction实现类传入,完成对实现将数据集中字符串记录转换成大写的数据处理。
public class FlinkWordCount {
public static void main(String[] args) throws Exception {
DataStreamSource<String> sourceData = env.socketTextStream("192.168.52.12", 9000);
//......
//数据源进行处理
sourceData.map(new MyMapFunciton());
//......
}
}
class MyMapFunciton implements MapFunction<String, String> {
@Override
public String map(String s) throws Exception {
return s.toUpperCase();
}
}
【2】通过创建匿名类实现Funciton接口
除了以上单独定义Class来实现Function接口之处,也可以直接在map()方法中创建匿名实现类的方式定义函数计算逻辑。
DataStreamSource<String> sourceData = env.socketTextStream("192.168.52.12", 9000);
//通过创建 MapFunction 匿名函数来定义 Map 函数计算逻辑
sourceData.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
//实现字符串大写转换
return s.toUpperCase();
}
});
【3】通过实现RichFunciton接口
前面提到的转换操作都实现了Function接口,例如MapFunction和FlatMapFunction接口,在Flink中同时提供了RichFunction接口,主要用于比较高级的数据处理场景,RichFunction接口中有open、close、getRuntimeContext和setRuntimeContext等方法来获取状态,缓存等系统内部数据。和MapFunction相似,RichFunction子类中也有RichMapFunction,如下代码通过实现RichMapFunction定义数据处理逻辑。
sourceData.map(new RichFunction() {
@Override
public void open(Configuration configuration) throws Exception {
}
@Override
public void close() throws Exception {
}
@Override
public RuntimeContext getRuntimeContext() {
return null;
}
@Override
public IterationRuntimeContext getIterationRuntimeContext() {
return null;
}
@Override
public void setRuntimeContext(RuntimeContext runtimeContext) {
}
});
分区Key指定:在 DataStream数据经过不同的算子转换过程中,某些算子需要根据指定的key进行转换,常见的有join、coGroup、groupBy类算子,需要先将DataStream或DataSet数据集转换成对应的KeyedStream和GroupedDataSet,主要目的是将相同key值的数据路由到相同的Pipeline中,然后进行下一步的计算操作。需要注意的是,在Flink中这种操作并不是真正意义上将数据集转换成Key-Value结构,而是一种虚拟的key,目的仅仅是帮助后面的基于Key的算子使用,分区人Key可以通过两种方式指定:
【1】根据字段位置指定
在DataStream API中通过 keyBy()方法将DataStream数据集根据指定的key转换成重新分区的KeyedStream,如以下代码所示,对数据集按照相同key进行sum()聚合操作。
// 根据第一个字段进行重分区,相同的单词进行分组。第二个字段进行求和运算
dataStream.keyBy(0).sum(1);
在DataSet API中,如果对数据根据某一条件聚合数据,对数据进行聚合时候,也需要对数据进行重新分区。如以下代码所示,使用DataSet API对数据集根据第一个字段作为GroupBy的key,然后对第二个字段进行求和运算。
// 根据第一个字段进行重分区,相同的单词进行分组。max 求相同key下的最大值
dataStream.groupBy(0).max(1);
【2】根据字段名称指定KeyBy和GroupBy的Key除了能够通过字段位置来指定之外,也可以根据字段的名称来指定。使用字段名称需要DataStream中的数据结构类型必须是Tuple类或者POJOs类的。如以下代码所示,通过指定name字段名称来确定groupby的key字段。
DataStreamSource<Persion> sourceData = env.fromElements(new Persion("zzx", 18));
//使用 name 属性来确定 keyBy
sourceData.keyBy("name").sum("age");
如果程序中使用Tuple数据类型,通常情况下字段名称从1开始计算,字段位置索引从0开始计算,以下代码中两种方式是等价的。
//通过位置指定第一个字段
dataStream.keyBy(0).sum(1);
//通过名称指定第一个字段名称
dataStream.keyBy("_1").sum("_2");
【3】通过Key选择器指定
另外一种方式是通过定义Key Selector来选择数据集中的Key,如下代码所示,定义KeySelector,然后复写getKey方法,从Person对象中获取name为指定的Key。
DataStreamSource<Persion> persionData = env.fromElements(new Persion("zzx", 18));
persionData.keyBy("name").sum("age");
persionData.keyBy(new KeySelector<Persion, Object>() {
@Override
public Object getKey(Persion persion) throws Exception {
return persion.getName();
}
});
理解 KeyedStream
基于key的HashCode重分区,同一个key只能在同一个分区内处理,一个分区内可以有不同的key。DataStream -> KeyedStream:逻辑地将一个key
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 创建一个流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据并转换为 类
val inputStreamFromFile: DataStream[String] = env.readTextFile("E:\\Project\\flink\\src\\main\\resources\\wordcount.txt")
//转换
val dataStream: DataStream[SensorReading] = inputStreamFromFile
.map( data => {
var dataArray = data.split(",")
SensorReading(dataArray(0),dataArray(1).toLong,dataArray(2).toDouble)
})
.keyBy(new MyIdSeletector())
// .sum("temperature")
//reduce:传入一个函数,函数类型都一样,每一次都是在之前的基础上结合当前新输入的数据得到一个进一步聚合的结果
//需求:输出最大的timestamp 最小的温度值 类型不能变
.reduce(new MyReduce)
/* .reduce((curRes,newData) =>
SensorReading(curRes.id,curRes.timestamp.max(newData.timestamp),curRes.temperature.min(newData.temperature)))*/
//aggregate:都是private类型,所有的滚动算子都会调到 aggregate。
//上面的只是定义了处理流程,同时定义一个名称。不会让任务结束
env.execute("stream word count word")
}
}
case class SensorReading(id: String, timestamp: Long, temperature: Double)
//自定义函数类,key选择器 输入类型SensorReading 返回 String
class MyIdSeletector() extends KeySelector[SensorReading,String] {
override def getKey(in: SensorReading): String = in.id
}
//自定义 Reduce
class MyReduce extends ReduceFunction[SensorReading] {
override def reduce(t: SensorReading, t1: SensorReading): SensorReading = {
SensorReading(t.id,t.timestamp.max(t1.timestamp),t.temperature.min(t1.temperature))
}
}
结果展示:分布式处理,可能得到的最后一条时间戳不是最大的。
假设有一条数据流,可以利用窗口的操作,进行一些竖向的切分,得到就是一个个大的AllWindowedStream,再根据keyBy()进行横向切分,把数据流中不同类别任务输入到不同的算子中进行处理,不同的算子之间是并行的操作。同时不同的节点只需要维护自己的状态。前提是 key数 >> 并发度
Split 分流操作
DataStream->SplitStream根据某些特征把一个DataStream拆分成两个或者多个DataStream。但它并不是一个完整的分流操作,只是从逻辑上按照某种特征进行分词了。
Select
SplitStream->DataStream:从一个SplitStream中获取一个或者多个DataStream。

案例:按照温度大于30和小于30进行分类
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 创建一个流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据并转换为 类
val inputStreamFromFile: DataStream[String] = env.readTextFile("E:\\Project\\flink\\src\\main\\resources\\wordcount.txt")
//转换
val dataStream: DataStream[SensorReading] = inputStreamFromFile
.map( data => {
var dataArray = data.split(",")
SensorReading(dataArray(0),dataArray(1).toLong,dataArray(2).toDouble)
})
.keyBy(new MyIdSeletector())
.sum("temperature")
//分流
val splitStream = dataStream.split(
data => {
if (data.temperature > 30)
Seq("high")
else
Seq("low")
})
val highTempStream: DataStream[SensorReading] = splitStream.select("high")
val lowTempStream: DataStream[SensorReading] = splitStream.select("low")
val allTempStream: DataStream[SensorReading] = splitStream.select("low","high")
highTempStream.print("highTempStream")
lowTempStream.print("lowTempStream")
allTempStream.print("allTempStream")
//上面的只是定义了处理流程,同时定义一个名称。不会让任务结束
env.execute("stream word count word")
}
输出结果展示:
Connect 合流操作
DataStream->ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
CoMap CoFlatMap
ConnectedStreams->DataStream:作用于ConnectedStream上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行 map和flatMap处理。
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 创建一个流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据并转换为 类
val inputStreamFromFile: DataStream[String] = env.readTextFile("E:\\Project\\flink\\src\\main\\resources\\wordcount.txt")
//转换
val dataStream: DataStream[SensorReading] = inputStreamFromFile
.map( data => {
var dataArray = data.split(",")
SensorReading(dataArray(0),dataArray(1).toLong,dataArray(2).toDouble)
})
.keyBy(new MyIdSeletector())
// .sum("temperature")
//reduce:传入一个函数,函数类型都一样,每一次都是在之前的基础上结合当前新输入的数据得到一个进一步聚合的结果
//需求:输出最大的timestamp 最小的温度值 类型不能变
.reduce(new MyReduce)
//分流
val splitStream = dataStream.split(
data => {
if (data.temperature > 60)
Seq("high")
else
Seq("low")
})
val lowTempStream: DataStream[SensorReading] = splitStream.select("low")
//合流
val warningStream: DataStream[(String,Double)] = highTempStream.map(
data => (data.id,data.temperature)
)
val connectedStreams: ConnectedStreams[(String,Double),SensorReading]
= warningStream.connect(lowTempStream)
val reslutStream: DataStream[Object] = connectedStreams.map(
warningData => (warningData._1,warningData._2,"high temp waring"),
lowTempSata => (lowTempSata.id,"normal")
)
reslutStream.print("result");
//上面的只是定义了处理流程,同时定义一个名称。不会让任务结束
env.execute("stream word count word")
}
}
输出结果:
Union
DataStream->DataStream:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新 DataStream。不能把类型不匹配的流合并在一起,可以Union两个或两个之上的流。
val highTempStream: DataStream[SensorReading] = splitStream.select("high")
val lowTempStream: DataStream[SensorReading] = splitStream.select("low")
val allTempStream: DataStream[SensorReading] = splitStream.select("low","high")
//union
val unionStream: DataStream[SensorReading] = highTempStream.union(lowTempStream).union(allTempStream)
sink 输出结果
数据集经过转换操作之后,形成最终的结果数据集,一般需要将数据集输出在外部系统中或者输出在控制台之上。在Flink DataStream和 DataSet接口中定义了基本的数据输出方法,例如基于文件输出writeAsText(),基于控制台输出print()等。同时Flink在系统中定义了大量的 Connector,方便用户和外部系统交互,用户可以直接通过调用addSink()添加输出系统定义的DataSink类算子,这样就能将数据输出到外部系统。以下实例调用DataStream API中的writeAsText()和print()方法将数据集输出在文件和客户端中。
//将数据流打印到控制台
dataStream.print();
//将数据输出到文件中
dataStream.writeAsText("file://path/to/savenfile");
//将数据输出到socket
reslutStream.writeToSocket(hostname : _root_.scala.Predef.String, port : java.lang.Integer, schema : org.apache.flink.api.common.serialization.SerializationSchema[T]) : org.apache.flink.streaming.api.datastream.DataStreamSink[T] = { /* compiled code */ })
//批处理才能使用,即将被弃用
reslutStream.writeAsCsv(path : _root_.scala.Predef.String, writeMode : org.apache.flink.core.fs.FileSystem.WriteMode)
//需要传入自定义的 Sink 写入文件
inputStreamFromFile.addSink(
StreamingFileSink.forRowFormat(
new Path("D:\\de"),
new SimpleStringEncoder[String]("UTF-8"))
.build())
//写出 kafka
dataStream.addSink(new FlinkKafkaProducer011[String]("localhost:9092","sinkTest",new SimpleStringSchema()))
execute 程序触发
所有的计算逻辑全部操作定义好之后,需要调用ExecutionEnvironment的execute()方法来触发应用程序的执行,因为flink在执行前会先构建执行图,再执行。其中execute()方法返回的结果类型为JobExecutionResult,里面包含了程序执行的时间和累加器等指标。需要注意的是,execute方法调用会因为应用的类型有所不同,DataStream流式应用需要显性地指定execute()方法运行程序,如果不调用则Flink流式程序不会执行,但对于DataSet API输出算子中已经包含对execute()方法的调用,则不需要显性调用execute()方法,否则会出现程序异常。
//调用 StreamExecutionEnvironment 的 execute 方法执行流式应用程序
env.execute("App Name");
物理分组

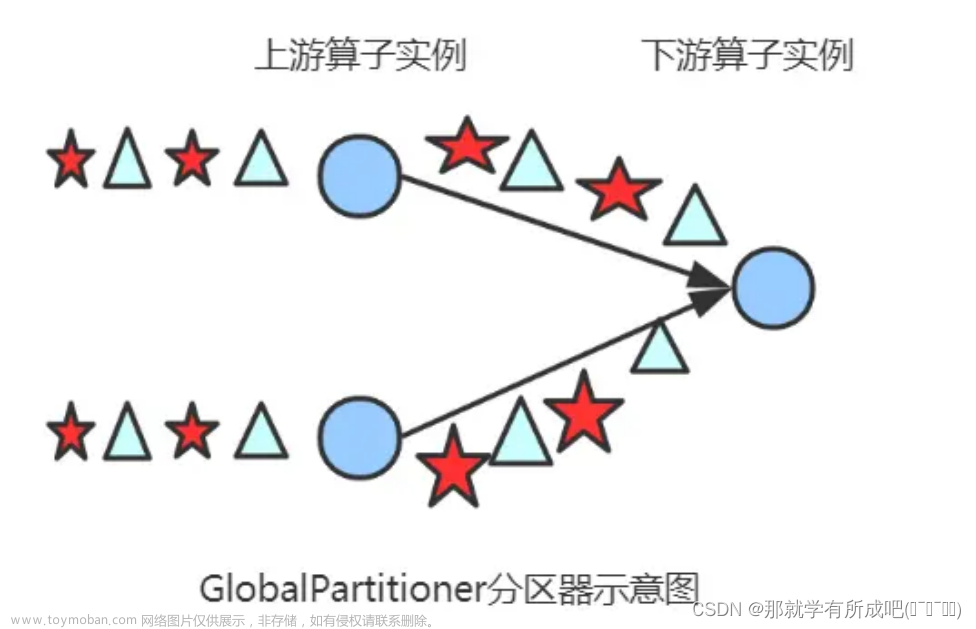
如上,有两个DataSource实例A1,A2。不同颜色代表不同的实例,Flink为我们提供了比较完整的物理分组方案:global()作用就是无论你下游有多少个实例(B),上游的数据(A)都会发往下游的第一个实例(B1);broadcast() 广播,对上游的数据(A)复制很多份发往下游的所有实例(B),数据指数级的增长,数据量大时要注意;forward()当上下游并发度一致的时候一对一发送,否则会报错;shuffle()随机均匀分配;rebalance()轮询;recale()本地轮流分配,例如上图A1只能看到两个实例B1和B2;partitionCustom()自定义单播;
类型系统
Flink它里面的抽象都是强类型的,与它自身的序列化和反序列化机制有关。这个引擎对类型信息知道的越多,就可以对数据进行更充足的优化,序列化与反序列化就会越快。每一个DataStream里面都需要有一个明确的类型和TypeInformation,Flink内置了如下类型,都提供了对应的TypeInfomation。 文章来源:https://www.toymoban.com/news/detail-769295.html
文章来源:https://www.toymoban.com/news/detail-769295.html
API 原理

一个DataStream是如何转化成另一个DataStream的,其实我们调用map方法的时候,Flink会给我们创建一个OneInputTransformation,需要一个StreamOperator参数Flink内部会有预先定义好的StreamMap转换的算子。Operator内部我们需要自定义一个MapFunction,一般Function才是我们写代码需要关注的点。如果需要更深一点就会写一些Operator。文章来源地址https://www.toymoban.com/news/detail-769295.html
到了这里,关于Flink 流处理流程 API详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!