介绍
顶顶通语音识别软件(asrproxy)是一个对接了多种语音识别接口的语音识别系统。可私有化部署(支持中文英文和方言等,支持一句话识别、实时流识别、多声道录音文件识别。
原理
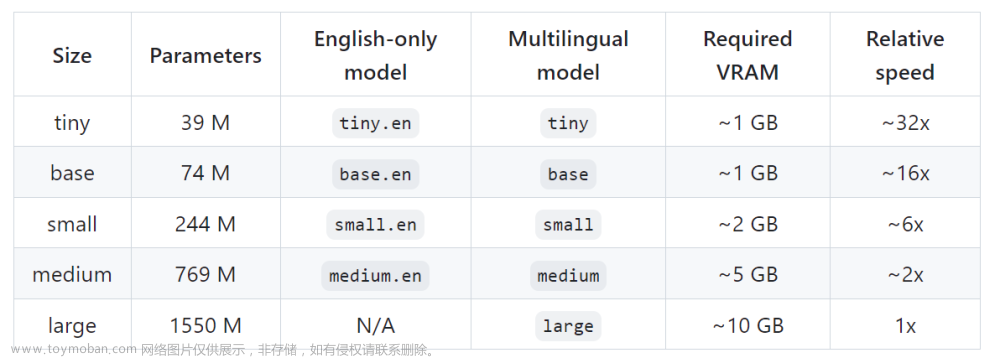
asrproxy内嵌了阿里达摩院的开源语音识别工具包FunASR,后续我们也会使用自有的预料来增强模型,以后也会添加openai的开源模型whisper 。asrproxy也对接了主流的ASR云服务商,比如阿里云,科大讯飞,腾讯云,mrcp等。使用同一套接口就可以无缝切换各种ASR。
一句话识别接口和录音文件识别接口
识别参数放在http请求头里面,声音文件内容通过post发送,不需要编码发送原始文件就可以。
POST /asr HTTP/1.1
Host: 116.62.146.93:9990
User-Agent: Mozilla/5.0
Accept: */*
Cache-Control: max-age=0
Connection: close
id:test
samplerate: 8000
signature:605bef92414621abfca073ebc6ad7d3b
timestamp:1697505856
engine:shortsentence
Content-Length: 30240
声音数据
识别结果通过JSON返回。
HTTP/1.1 200 OK
Date: Tue, 17 Oct 2023 01:25:36 GMT
Server: www.ddrj.com
Content-Length: 35
Connection: Keep-Alive
Content-Type: text/plain
Pragma: no-cache
Cache-Control: private, max-age=0, no-cache
{"code":"0","desc":"识别结果"}
请求参数说明
-
timestamp 时间戳和服务器误差只允许5分钟内
-
id asrproxy.json配置的用户id(asrproxy.json->short_sentence_asr->users)
-
signature 签名 md5(key+timestamp) 本例中key是test,md5(test1697505856)=605bef92414621abfca073ebc6ad7d3b。
key配置位置:asrproxy.json->short_sentence_asr->users->id->key -
engine 引擎类型 asrproxy.json->groups配置ASR引擎,默认配置是 shortsentence
-
hostwords 热词,多个热词用空格分开
-
datatype 数据类型,不设置默认是pcm类型
- pcm 原始的PCM数据,
- wav wav格式的数据
- mp3 mp3格式的数据
- url 通过URL获取文件
-
samplerate datatype是pcm时有效,声音采样频率,不设置默认是8000
-
sentence_time 是否需要输出句子时间,设置为true输出。
-
post内容
-
datatype是pcm、wav、mp3时是原始的声音数据
-
datatype是url的时候是josn格式的要识别的文件信息
{ "uuid":"唯一的ID,回调通知用", "callback_url":"识别结果回掉URL。", "file_url":"要识别文件的URL,支持本地文件的绝对路径和http文件", "ext":"wav|mp3|pcm"//http返回的数据类型,如果file_url是本地文件会根据文件后缀来识别文件类型 }
-
响应参数说明
- code 0 没错误 其他错误代码,如果有错误desc内容是错误信息
- desc
-
识别单声道文件时desc是字符串类型的识别结果。
-
识别多声道文件时并且sentence_time设置为fasle,desc字符串数组类型[“第一声道的识别结果”,“第二声道的识别结果”]
-
sentence_time 设置为true,desc是二维数组
- silence_duration 句子前面的静音时间,单位秒
- begin_time 句子开始时间,单位秒
- end_time 句子结束时间,单位秒
- speech_rate 语速,单位为每分钟字数
{ "uuid": "", "code": "0", "desc": [ [{ "silence_duration": 1.36, "begin_time": 1.36, "end_time": 3.19, "speech_rate": 131.148, "text": "喂你好。" }, { "silence_duration": 0.74, "begin_time": 3.93, "end_time": 17.76, "speech_rate": 303.688, "text": "这边是百万医疗项目的客服哈。" }], [{ "silence_duration": 1.36, "begin_time": 1.36, "end_time": 3.19, "speech_rate": 131.148, "text": "喂你好。" }, { "silence_duration": 0.74, "begin_time": 3.93, "end_time": 17.76, "speech_rate": 303.688, "text": "这边是百万医疗项目的客服哈。" }] ] }
-
测试方法
接口测试地址 http://demo.ddrj.com:9990/asr
浏览器直接上传文件测试地址 http://demo.ddrj.com:9990/test
可用curl命令测试,为了调过验证签名步骤,需要把asrproxy.json->short_sentence_asr->users->id(test)里面添加"not_validate_signature":true这个配置。
一句话识别测试
1.wav改成要识别的文件,如果识别的文件是mp3的,datatype:wav也要改成datatype:mp3
curl -H "id:test" -H "engine:shortsentence" -H "datatype:wav" -X POST --data-binary @1.wav http://demo.ddrj.com:9990/asr
录音文件识别测试
curl -H "id:test" -H "engine:shortsentence" -H "datatype:url" -X POST -d "{\"ext\":\"mp3\",\"uuid\":\"name\",\"file_url\":\"http://demo.ddrj.com/t1.mp3\",\"callback_url\":\"http://demo.ddrj.com/ttsresult\"}" http://demo.ddrj.com:9990/asr
实时流识别接口
通过websocket连接上 ws://127.0.0.1:9988 ,发送一个请求头,然后发送二进制的声音流,结束识别发送字符串END结束识别。
引导头格式为 时间戳json的参数\0,注意\0是一个二禁制的0。
1699344741507{"callid":"07ca13d3-55cc-47ef-a591-ffaee83d0e0b","asr_mode":1,"hot_word":"","asr_params":{"group":"default"},"vad_min_active_time_ms":100,"vad_max_end_silence_time_ms":1000,"wait_speech_timeout_ms":5000,"max_speech_time_ms":60000,"samples_per_second":8000}\0
- asr_mode: asr模式 0只第一句话 1 持续识别
- hot_word: 热词 ,需要asr引擎支持
- asr_params: asr参数,可用来选择asr引擎 {“group”:“default”}
- vad_min_active_time_ms: 最小说话时间,需要ASR引擎支持
- vad_max_end_silence_time_ms: 最大静音时间,需要ASR引擎支持
- wait_speech_timeout_ms: 等待说话时间,需要ASR引擎支持
- max_speech_time_ms: 最大识别时间,需要ASR引擎支持
- samples_per_second: 声音频率 8000或者 16000
返回识别结果
【标记1个字节-识别结果】
标记字符含义
0:中间结果
1:句子结束,对于支持长时间识别的ASR才支持,用于断句。
F:识别结束,客户端已经发送了END
f:识别结束,客户端没有发送END,ASR检测到静音太长认为停止说话了。
E:ASR错误
标志是f/F/E的时候客户端要主动断开连接文章来源:https://www.toymoban.com/news/detail-769327.html
测试页面
http://demo.ddrj.com/wsasr.html文章来源地址https://www.toymoban.com/news/detail-769327.html
配置
{
"key":"asrproxy.license", //授权文件路径
"log":{
"console_level":0, //输出控制台日志等级0-5(0:DEBUG, 1:INFO, 2:NOTICE, 3:WARNING, 4:CRIT, 5:CONSOLE)
"file_level":0, //输出到文件日志等级0-5(0:DEBUG, 1:INFO, 2:NOTICE, 3:WARNING, 4:CRIT, 5:CONSOLE)
"file_maxsize":100, //文件大于多少M就自动创建新的日志文件。
"file_number":10 //最大保留日志文件个数
},
"short_sentence_asr":{
"listen_ip":"0.0.0.0",
"listen_port":9990,
"bgasr_thread_count":null, //录音文件识别的ASR线程个数,如果不设置就是根据CPU个数自动设置。
"users":{
//用户ID,可以配置多个用户
"test":{
"not_validate_signature":false,//是否禁用验证签名,改成true,就是不验证签名
"key":"test",//用户KEY
"ip":"*" //*任意IP都可以访问,也可以限制可以访问的ip
}
}
},
"asr":{
"listen_ip": "127.0.0.1",
"listen_port": 9988,
"storage": "record", //asr录音目录,调用asr时,设置了asr_params.recordfilename才会录音。
"acl":"*", //哪些IP可以访问,配置*任意IP都可以访问,多个IP用逗号隔开,如果不配置acl,通过127.0.0.1不需要配置在ACL里面也可以访问。
"interface": {
"funasr": {
"type": "funasr",
"engine": "sentence", //一句话
"enable_itn":true, //数字转换成阿拉伯数字
"model-dir": "model/paraformer-large"//模型目录
},
"funasr_realtime": {
"type": "funasr",
"engine": "2pass",//offline:关闭实时识别 online:开启实时识别 2pass:混合2种模式,需要更多CPU。
"enable_itn":true, //数字转换成阿拉伯数字
"model-dir": "model/paraformer-large",
"online-model-dir": "model/paraformer-large-online",
"punc-dir": "model/punc-realtime",
"chunk-size":4800
}
},
"groups":{
//实时识别使用的ASR
"default":{
"mode":0, //0:顺序使用,当使用数量等于count的时候切换下一个 1:循环使用
"enable": //启用的那些ASR配置
[
"funasr_realtime"
]
},
//一句话识别和文件识别使用的ASR
"shortsentence":{
"mode":0,
"enable":[
"funasr"
]
}
}
}
}
到了这里,关于顶顶通语音识别使用说明的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!