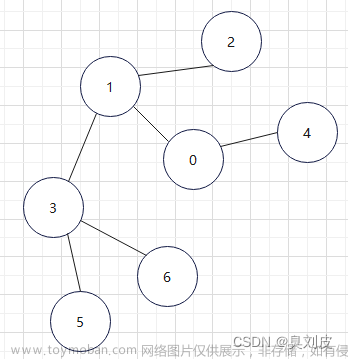
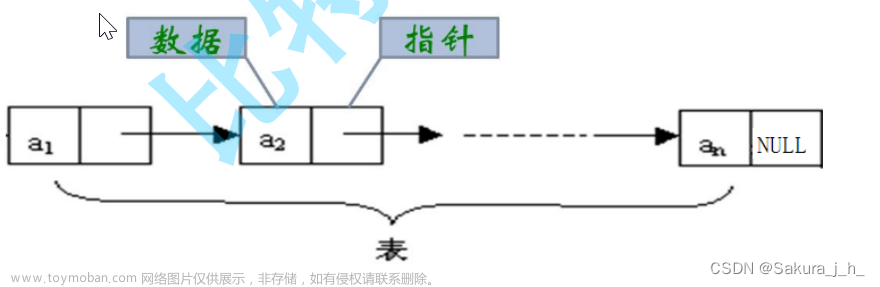
图的概念
图是由节点(也称为顶点)和边(也称为边缘)组成的非线性数据结构。节点是图的基本单元,边则用于连接节点之间的关系。图可以用于许多不同的应用程序,包括社交网络、网络拓扑、地图和生物学。
在图中,节点和边可以具有不同的属性。例如,一个社交网络图可能具有节点属性表示用户的姓名和年龄,边属性可能表示用户之间的关系,如朋友或家庭关系。图可以是有向或无向的,也可以是加权或未加权的。有向图具有指向边的方向,而无向图则没有。加权图则对边进行加权,这些权重可以表示距离、成本或其他数据。
图的定义:图G由顶点集V和边集E组成,G = (V,E);
有向图与无向图
如果给图的每条边规定一个方向,那么该图称为有向图。在有向图中,从一个顶点出发的边数称为该点的出度,而指向一个顶点的边数称为该点的入度。相反,边没有方向的图称为无向图。
在有向图中,边指向的结点是唯一的,而无向图的边所连接的结点相互连通;
有权图与无权图
如果图中的边都有各自的权重,则称该图为有权图。反之,如果图中的边无权重(各边的权重相同),则该图为无权图;
图的存储
常用的存储方式有两种:邻接矩阵和邻接表。得分
邻接矩阵:
图的邻接矩阵是一个二维矩阵,矩阵的行和列分别对应图中的顶点。如果两个顶点之间有边,则矩阵中对应的元素为1;否则为0。对于无向图来说,邻接矩阵是对称的。而对于有向图来说,邻接矩阵则不一定对称。因此邻接矩阵的表示相当的直观,而且对于查找某一条边是否存在、权重多少非常快。但其比较浪费空间,对稠密图来说,会比较适合。
代码实现步骤:
1、构建图的基本元素与图的初始化
#define Maxcount 100
struct Node{ //图
int Nv; //顶点数
int Ne; //边数
int data[Maxcount]; //顶点数据
int wight[Maxcount][Maxcount]; //边的权重
};
struct Nodes //边
{
int V1, V2; //边所连接的顶点
int wight; //边的权重
};
void initialize(struct Node *graph ,int Vexcount) //初始化图
{
graph->Nv = Vexcount; //顶点数
graph->Ne = 0; //边数置零
for (int i = 0; i <= Vexcount; i++)
{
for (int j = 0; j <= Vexcount; j++)
{
graph->wight[i][j] = 0; //初始化每条边的比重
}
}
}2、插入边的权重
void insertedge(struct Node* graph, struct Nodes* edge) //插入边的权重(无向图)
{
graph->wight[edge->V1][edge->V2] = edge->wight;
graph->wight[edge->V2][edge->V1] = edge->wight;
}3、主函数
int main()
{
printf("邻接矩阵实现图!\n");
int count;
printf("图的顶点数:");
scanf_s("%d/n", &count);
struct Node* graph = (struct Node*)malloc(sizeof(struct Node));
initialize(graph, count);
int edgecount;
printf("图的边数:");
scanf_s("%d", &edgecount);
if (edgecount != 0)
{
printf("请依次输入顶点与权重:\n");
for (int i = 0; i < edgecount; i++)
{
struct Nodes* edge = (struct Nodes*)malloc(sizeof(struct Nodes));
scanf_s("%d %d %d", &edge->V1, &edge->V2, &edge->wight);
insertedge(graph, edge);
}
printf("请输入顶点的数据:\n");
for (int j = 1; j <= count; j++)
scanf_s("%d", &graph->data[j]);
}
printf("打印邻接矩阵图!\n");
for (int i = 1; i <= count; i++) //从1开始遍历
{
for (int j = 1; j <= count; j++)
{
printf("%5d ", graph->wight[i][j]);
}
printf("\n");
}
printf("打印图中各点数据!\n");
for (int i = 1; i <= count; i++)
printf("%3d ", graph->data[i]);
printf("\n");
return 0;
}注意:以上代码创建的是无向图;
代码执行后,结果如下图:
邻接表
图的邻接表是一种表示图的数据结构,它使用一个一维数组来存储顶点,使用链表的形式来存储该顶点与其他顶点的链接,链表内存储着顶点的数组下标,因此,邻接表比较适合稀疏图;
代码实现步骤:
1、基本元素的构建与图的初始化
#define Maxcount 100
struct edgeNode { //边结点
int wight; //权重
struct edgeNode* next; //指向下一结点的指针
int local; //边结点本身数值
};
struct VNode { //顶点
int data; //顶点数据
struct edgeNode* firstnext; //指向边结点的指针
};
struct Adjgarph { //图
int Nv; //顶点个数
int Ne; //边数
struct VNode List[Maxcount]; //顶点数组
};
void initialize(struct Adjgarph* G) //图的初始化
{
printf("请输入顶点数:");
scanf_s("%d", &G->Nv);
printf("请输入边数:");
scanf_s("%d", &G->Ne);
printf("请依次输入顶点数据:\n");
for (int i = 1; i <= G->Nv; i++) //写入顶点数据
{
scanf_s("%d/n", &G->List[i].data);
G->List[i].firstnext = NULL; //指针指向空
}
}2、插入边的权重
void creatgraph(struct Adjgarph *G) //权重插入
{
printf("请输入顶点与权重:\n");
for (int i = 1; i <= G->Ne; i++) //每次插入边的数据
{
struct edgeNode* p = (struct edgeNode*)malloc(sizeof(struct edgeNode)); //边的创建
int W; //边结点的父节点
scanf_s("%d %d %d", &W, &p->local, &p->wight);
p->next = G->List[W].firstnext; //p结点的指针指向顶点的指向
G->List[W].firstnext = p; //顶点指针指向p
//该图为无向图,因此要p指向q,q也指向p,要插入两次;
struct edgeNode* q = (struct edgeNode*)malloc(sizeof(struct edgeNode));
q->local = W;
q->wight = p->wight;
q->next = G->List[p->local].firstnext;
G->List[p->local].firstnext = q;
}
}
3、主函数
int main()
{
printf("邻接表实现图!\n");
struct Adjgarph* graph = (struct Adjgraph*)malloc(sizeof( struct Adjgarph)); //给图创建空间
initialize(graph); //初始化图
creatgraph(graph); //权重插入
printf("打印邻接表的示意图!\n");
for (int i = 1; i <= graph->Nv; i++)
{
printf("%d->", i); //打印顶点数据
struct VNode* p = graph->List[i].firstnext; //保存最初结点位置
while (graph->List[i].firstnext != NULL)
{
printf("%d -- wight:%d ->", graph->List[i].firstnext->local, graph->List[i].firstnext->wight); //打印i顶点的边结点与权重
graph->List[i].firstnext = graph->List[i].firstnext->next; // i顶点指针指向下一个边结点
}
if (graph->List[i].firstnext == NULL)
printf("NULL");
printf("\n");
graph->List[i].firstnext = p; //赋回原来位置
}
return 0;
}代码执行后,结果如下图:
图的遍历
图的遍历最常用的有两种:深度优先搜索(Depth-first Search, DFS)和广度优先搜索(Breadth-First Search, BFS)。
深度优先遍历
深度优先遍历(DFS):类似于树的先序遍历,尽可能深的搜索图,从某个顶点出发,沿着一条边走到底,直到不能走为止,然后返回上一层,再走其他的路径,直到遍历完整个图。DFS通常使用递归来实现。
代码实现:
1、邻接矩阵实现的图:
//深度遍历(邻接矩阵实现图)
void depthsearch(struct Node* graph, int V, int visit[]) //V为起始点,visit数组为标记数组
{
int i;
visit[V] = 1; //标记被遍历过的元素
printf("%d ", graph->data[V]); //打印
for (i = 1; i <= graph->Nv; i++) //遍历V行的每一列
{
if (graph->wight[V][i] != 0 && visit[i] != 1) //权重不为0 且 i元素未被遍历过
depthsearch(graph, i, visit); //将i元素传入并递归
}
}主函数变化:
//深度遍历
int vin; //初始点
int *visit = (int*)malloc(sizeof(int) * (graph->Nv)); // 建立标记数组
printf("请输入深度遍历的初始点:");
scanf_s("%d/n", &vin);
depthsearch(graph, vin, visit); //传入数据2、 邻接表实现的图:
//深度遍历(邻接表实现图)
void depthsearch(struct Adjgarph* graph, int V, int* visit)
{
visit[V] = 1; //标记
printf("%d ", graph->List[V].data);
struct edgeNode* p = graph->List[V].firstnext; //代替指针移动
while (p != NULL) //指针指向不为NULL
{
if (visit[p->local] == 0) //未被遍历过
depthsearch(graph, p->local, visit);
p = p->next;
}
}
int locatvex(struct VNode* arr, int vex) //查找顶点在数组中的下标
{
for (int i = 0; i < Maxcount; i++)
{
if (arr[i].data == vex)
return i;
}
return -1;
}主函数变化:
//深度遍历
int vin;
int* visit = (int*)malloc(sizeof(int) * ((graph->Nv)+1)); //创建下标数组
for (int t = 0; t <= graph->Nv; t++) //置零
visit[t] = 0;
printf("请输入初始点:");
scanf_s("%d/n", &vin);
depthsearch(graph, locatvex(graph->List,vin), visit);广度优先遍历
广度优先遍历(BFS):类似于树的层序遍历,一层一层的遍历,依次访问它的所有邻接点,再依次访问邻接点的所有未访问过的邻接点,直到遍历完整个图。为实现逐层遍历,BFS通常借用队列来实现。
代码实现:
1、邻接矩阵实现图:
//广度遍历
void breadsearch(struct Node* graph, int V, int visit[])
{
int que[Maxcount]; //数组实现队
int front = 1;
int rear = 1;
que[rear++] = V;
while (front < rear) //终止条件
{
printf("%d ", que[front++]);
visit[V] = 1;
for (int j = 1; j <= graph->Nv; j++)
{
if (visit[j] == 0 && graph->wight[front][j] != 0) //结点未被遍历 且 权重不为零
{
printf("%d ", graph->data[j]);
visit[j] = 1;
que[rear++] = j; //rear向后移
}
}
}
}主函数变化:
//广度遍历
int vin;
int* visit = (int*)malloc(sizeof(int) * (graph->Nv));
for (int i = 0; i <= graph->Nv; i++)
visit[i] = 0;
printf("请输入广度遍历的初始点:");
scanf_s("%d/n", &vin);
breadsearch(graph, vin, visit);2、邻接表实现图:
//链表建立队列
struct Node {
int data;
struct Node* next;
};
struct Node* front = NULL;
struct Node* rear = NULL;
int target = 0;
void push(int vin) //入队
{
struct Node* temp = (struct Node*)malloc(sizeof(struct Node));
temp->data = vin;
temp->next = NULL;
if (front == NULL && rear == NULL)
{
front = temp;
rear = temp;
target = 1; //用来避免指针同指首元素
}
else
{
rear->next = temp;
rear = temp;
}
}
void pop() //出队
{
if (front == NULL && rear == NULL)
{
printf("error!");
return;
}
struct Node* temp = front;
front = front->next;
free(temp);
}
//广度遍历(邻接表实现图)
void breadthsearch(struct Adjgarph* graph, int V, int* visit)
{
visit[V] = 1;
push(V); //将顶点数据传入队
while (front != NULL || target == 1) //队列不为空 (front和rear都指向首元素)
{
printf("%d ", graph->List[front->data].data); //打印顶点数据
target = 0; //赋零
struct edgeNode* p = graph->List[front->data].firstnext;
while (p) //边结点不为空
{
if (!visit[p->local]) //该结点未被遍历过
push(p->local); //结点入队
visit[p->local] = 1;
p = p->next; //向下移动
}
pop(); //首元素出队
}
}主函数变化:文章来源:https://www.toymoban.com/news/detail-769356.html
//广度遍历
int vin;
int* visit = (int*)malloc(sizeof(int) * ((graph->Nv) + 1));
for (int t = 0; t <= graph->Nv; t++)
visit[t] = 0;
printf("请输入初始点:");
scanf_s("%d/n", &vin);
breadthsearch(graph, vin, visit);
文章来源地址https://www.toymoban.com/news/detail-769356.html
到了这里,关于数据结构之图(C语言)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!