作者:Priscilla Parodi

抄袭可以是直接的,涉及复制部分或全部内容,也可以是释义的,即通过更改一些单词或短语来重新表述作者的作品。

灵感和释义之间是有区别的。 即使你得出类似的结论,也可以阅读内容,获得灵感,然后用自己的话探索这个想法。
虽然抄袭长期以来一直是讨论的话题,但内容的加速制作和发布使其保持了相关性并构成了持续的挑战。

这一挑战不仅限于经常进行抄袭检查的书籍、学术研究或司法文件。 它还可以扩展到报纸甚至社交媒体。
随着信息的丰富和发布的便捷性,如何在可扩展的水平上有效地检查抄袭行为?
大学、政府实体和公司使用不同的工具,虽然简单的词汇搜索可以有效地检测直接抄袭,但主要的挑战在于识别释义内容。
如果你想一步一步地在你自己的电脑里实现如下的文章中所描述的练习,请详细阅读文章 “使用 Elasticsearch 检测抄袭 (二)”。
使用生成人工智能检测抄袭
生成人工智能出现了新的挑战。 人工智能生成的内容在复制时是否被视为抄袭?

例如,OpenAI 使用条款规定 OpenAI 不会对 API 为用户生成的内容主张版权。 在这种情况下,使用生成式人工智能的个人可以根据自己的喜好使用生成的内容,而无需引用。

然而,是否接受使用生成式人工智能来提高效率仍然是一个讨论的话题。
为了为抄袭检测做出贡献,OpenAI 开发了一个检测模型,但后来承认其准确性不够高。
“我们认为这对于独立检测来说不够高,需要与基于元数据的方法、人类判断和公共教育相结合才能更有效。”
挑战依然存在; 然而,随着更多工具的出现,现在检测抄袭的选项也增加了,即使是在释义和人工智能内容的情况下也是如此。
使用 Elasticsearch 检测抄袭
认识到这一点,在这篇博客中,我们正在探索自然语言处理 (NLP) 模型和向量搜索的另一个用例,即除元数据搜索之外的抄袭检测。
这通过 Python 示例进行了演示,其中我们利用包含 NLP 相关文章的 SentenceTransformers 的数据集。 我们通过执行 “语义文本相似性” 来检查摘要是否抄袭,考虑到使用之前导入 Elasticsearch 的文本嵌入模型生成的 “abstract” 嵌入。 此外,为了识别人工智能生成的内容 —— 人工智能抄袭,OpenAI 开发的 NLP 模型也被导入到 Elasticsearch 中。
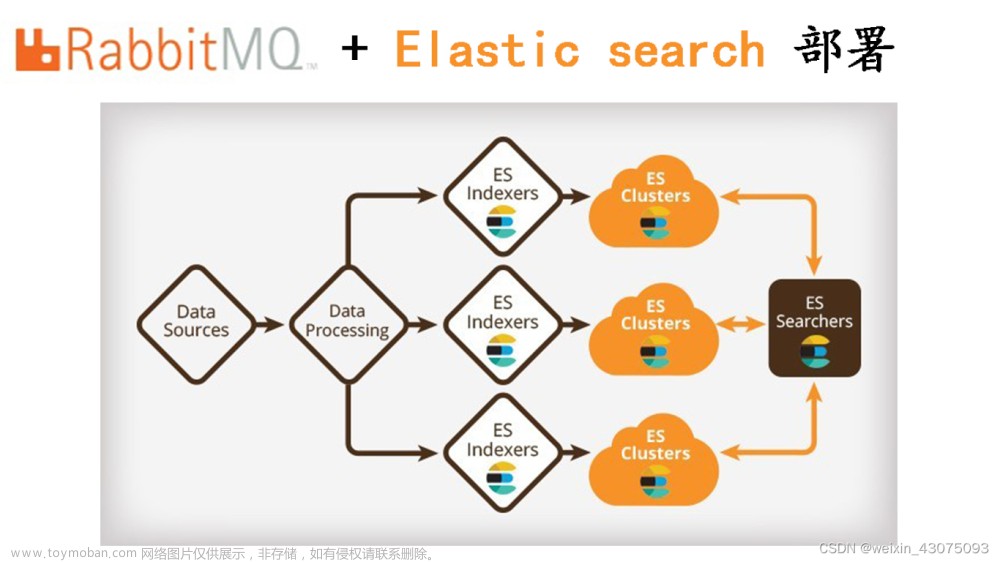
下图说明了数据流:

在使用推理处理器的摄取管道期间,“abstract” 段落被映射到 768 维向量,即 “abstract_vector.predicted_value”。
映射:
"abstract_vector.predicted_value": { # Inference results field
"type": "dense_vector",
"dims": 768, # model embedding_size
"index": "true",
"similarity": "dot_product" # When indexing vectors for approximate kNN search, you need to specify the similarity function for comparing the vectors.向量表示之间的相似性是使用向量相似性度量来测量的,该度量是使用 “similarity” 参数定义的。
余弦是默认的相似度度量,计算公式为 “(1 + cosine(query, vector)) / 2”。 除非需要保留原始向量并且无法提前对它们进行归一化,否则执行余弦相似度的最有效方法是将所有向量归一化为单位长度。 这有助于避免在搜索过程中执行额外的向量长度计算,而是使用 “dot_product”。
在同一管道中,另一个包含文本分类模型的推理处理器会检测内容是可能由人类编写的 “真实” 内容,还是可能由人工智能编写的 “假” 内容,并将 “openai- detector.predicted_value” 添加到每个文档中。
摄取管道:
client.ingest.put_pipeline(
id="plagiarism-checker-pipeline",
processors = [
{
"inference": { #for ml models - to infer against the data that is being ingested in the pipeline
"model_id": "roberta-base-openai-detector", #text classification model id
"target_field": "openai-detector", # Target field for the inference results
"field_map": { #Maps the document field names to the known field names of the model.
"abstract": "text_field" # Field matching our configured trained model input.
}
}
},
{
"inference": {
"model_id": "sentence-transformers__all-mpnet-base-v2", #text embedding model id
"target_field": "abstract_vector", # Target field for the inference results
"field_map": {
"abstract": "text_field" # Field matching our configured trained model input. Typically for NLP models, the field name is text_field.
}
}
}
]
)在查询时,还采用相同的文本嵌入模型在 “query_vector_builder” 对象中生成查询 “model_text” 的向量表示。
k 最近邻 (kNN) 搜索找到与通过相似性度量测量的查询向量最接近的 k 个向量。
每个文档的 _score 是根据相似度得出的,确保较大的分数对应较高的排名。 这意味着该文档在语义上更加相似。 因此,我们打印三种可能性:如果分数> 0.9,我们正在考虑 “高度相似性”; 如果 < 0.7,“低相似度”,否则,“中等相似度”。 你可以根据你的用例灵活地设置不同的阈值,以确定什么级别的 _score 判定为抄袭。
此外,执行文本分类还可以检查文本查询中人工智能生成的元素。
询问:
from elasticsearch import Elasticsearch
from elasticsearch.client import MlClient
#duplicated text - direct plagiarism test
model_text = 'Understanding and reasoning about cooking recipes is a fruitful research direction towards enabling machines to interpret procedural text. In this work, we introduce RecipeQA, a dataset for multimodal comprehension of cooking recipes. It comprises of approximately 20K instructional recipes with multiple modalities such as titles, descriptions and aligned set of images. With over 36K automatically generated question-answer pairs, we design a set of comprehension and reasoning tasks that require joint understanding of images and text, capturing the temporal flow of events and making sense of procedural knowledge. Our preliminary results indicate that RecipeQA will serve as a challenging test bed and an ideal benchmark for evaluating machine comprehension systems. The data and leaderboard are available at http://hucvl.github.io/recipeqa.'
response = client.search(index='plagiarism-checker', size=1,
knn={
"field": "abstract_vector.predicted_value",
"k": 9,
"num_candidates": 974,
"query_vector_builder": { #The 'all-mpnet-base-v2' model is also employed to generate the vector representation of the query in a 'query_vector_builder' object.
"text_embedding": {
"model_id": "sentence-transformers__all-mpnet-base-v2",
"model_text": model_text
}
}
}
)
for hit in response['hits']['hits']:
score = hit['_score']
title = hit['_source']['title']
abstract = hit['_source']['abstract']
openai = hit['_source']['openai-detector']['predicted_value']
url = hit['_source']['url']
if score > 0.9:
print(f"\nHigh similarity detected! This might be plagiarism.")
print(f"\nMost similar document: '{title}'\n\nAbstract: {abstract}\n\nurl: {url}\n\nScore:{score}\n\n")
if openai == 'Fake':
print("This document may have been created by AI.\n")
elif score < 0.7:
print(f"\nLow similarity detected. This might not be plagiarism.")
if openai == 'Fake':
print("This document may have been created by AI.\n")
else:
print(f"\nModerate similarity detected.")
print(f"\nMost similar document: '{title}'\n\nAbstract: {abstract}\n\nurl: {url}\n\nScore:{score}\n\n")
if openai == 'Fake':
print("This document may have been created by AI.\n")
ml_client = MlClient(client)
model_id = 'roberta-base-openai-detector' #open ai text classification model
document = [
{
"text_field": model_text
}
]
ml_response = ml_client.infer_trained_model(model_id=model_id, docs=document)
predicted_value = ml_response['inference_results'][0]['predicted_value']
if predicted_value == 'Fake':
print("\nNote: The text query you entered may have been generated by AI.\n")输出:
检测到高相似度! 这可能是抄袭。
High similarity detected! This might be plagiarism.
Most similar document: 'RecipeQA: A Challenge Dataset for Multimodal Comprehension of Cooking Recipes'
Abstract: Understanding and reasoning about cooking recipes is a fruitful research direction towards enabling machines to interpret procedural text. In this work, we introduce RecipeQA, a dataset for multimodal comprehension of cooking recipes. It comprises of approximately 20K instructional recipes with multiple modalities such as titles, descriptions and aligned set of images. With over 36K automatically generated question-answer pairs, we design a set of comprehension and reasoning tasks that require joint understanding of images and text, capturing the temporal flow of events and making sense of procedural knowledge. Our preliminary results indicate that RecipeQA will serve as a challenging test bed and an ideal benchmark for evaluating machine comprehension systems. The data and leaderboard are available at[ http://hucvl.github.io/recipeqa](http://hucvl.github.io/recipeqa).
url:[http://aclweb.org/anthology/D18-1166](http://aclweb.org/anthology/D18-1166)
Score:1.0在此示例中,在利用数据集中的 “abstract” 值之一作为文本查询 “model_text” 后,识别出了抄袭。 相似度得分为1.0,表明相似度很高 —— 直接抄袭。 向量化查询和文档未被识别为人工智能生成的内容,这是预期的。
查询:
#similar text - paraphrase plagiarism test
model_text = 'Comprehending and deducing information from culinary instructions represents a promising avenue for research aimed at empowering artificial intelligence to decipher step-by-step text. In this study, we present CuisineInquiry, a database for the multifaceted understanding of cooking guidelines. It encompasses a substantial number of informative recipes featuring various elements such as headings, explanations, and a matched assortment of visuals. Utilizing an extensive set of automatically crafted question-answer pairings, we formulate a series of tasks focusing on understanding and logic that necessitate a combined interpretation of visuals and written content. This involves capturing the sequential progression of events and extracting meaning from procedural expertise. Our initial findings suggest that CuisineInquiry is poised to function as a demanding experimental platform.'输出:
High similarity detected! This might be plagiarism.
Most similar document: 'RecipeQA: A Challenge Dataset for Multimodal Comprehension of Cooking Recipes'
Abstract: Understanding and reasoning about cooking recipes is a fruitful research direction towards enabling machines to interpret procedural text. In this work, we introduce RecipeQA, a dataset for multimodal comprehension of cooking recipes. It comprises of approximately 20K instructional recipes with multiple modalities such as titles, descriptions and aligned set of images. With over 36K automatically generated question-answer pairs, we design a set of comprehension and reasoning tasks that require joint understanding of images and text, capturing the temporal flow of events and making sense of procedural knowledge. Our preliminary results indicate that RecipeQA will serve as a challenging test bed and an ideal benchmark for evaluating machine comprehension systems. The data and leaderboard are available at[ http://hucvl.github.io/recipeqa](http://hucvl.github.io/recipeqa).
url:[http://aclweb.org/anthology/D18-1166](http://aclweb.org/anthology/D18-1166)
Score:0.9302529
Note: The text query you entered may have been generated by AI.通过使用 AI 生成的文本更新文本查询 “model_text”,该文本传达相同的信息,同时最大限度地减少相似单词的重复,检测到的相似度仍然很高,但得分为 0.9302529,而不是 1.0 —— 释义抄袭 (paraphrase plagiarism) 。 人们还预计该由人工智能生成的查询会被检测到。
最后,考虑到文本查询 “model_text” 是关于 Elasticsearch 的文本,它不是这些文档之一的摘要,检测到的相似度为 0.68991005,根据考虑的阈值表明相似度较低。
查询:
#different text - not a plagiarism
model_text = 'Elasticsearch provides near real-time search and analytics for all types of data.'输出:
Low similarity detected. This might not be plagiarism.尽管在人工智能生成的文本查询中以及在释义和直接复制内容的情况下可以准确地识别出抄袭行为,但在抄袭检测领域的导航涉及到承认各个方面。
在人工智能生成的内容检测的背景下,我们探索了一种做出有价值贡献的模型。 然而,认识到独立检测的固有局限性至关重要,因此需要结合其他方法来提高准确性。
文本嵌入模型的选择带来的可变性是另一个考虑因素。 使用不同数据集训练的不同模型会产生不同程度的相似性,凸显了生成的文本嵌入的重要性。
最后,在这些示例中,我们使用了文档的摘要。 然而,抄袭检测通常涉及大型文档,因此必须解决文本长度的挑战。 文本超出模型的标记限制是很常见的,需要在构建嵌入之前将其分割成块。 处理这个问题的一种实用方法是利用带有 dense_vector 的嵌套结构。
结论:
在这篇博客中,我们讨论了检测剽窃的挑战,特别是在释义和人工智能生成的内容中,以及如何将语义文本相似性和文本分类用于此目的。
通过结合这些方法,我们提供了抄袭检测的示例,其中我们成功识别了人工智能生成的内容、直接抄袭和转述抄袭。
主要目标是建立一个简化检测的过滤系统,但人工评估对于验证仍然至关重要。
如果你有兴趣了解有关语义文本相似性和 NLP 的更多信息,我们鼓励你也查看以下链接:文章来源:https://www.toymoban.com/news/detail-769417.html
- 什么是语义搜索?
- 什么是自然语言处理(NLP)?
- 使用 Elasticsearch 进行词汇和语义搜索
- 通过摄取管道加上嵌套向量对大型文档进行分块等于轻松的段落搜索
原文:Elasticsearch:通过摄取管道加上嵌套向量对大型文档进行分块轻松地实现段落搜索-CSDN博客文章来源地址https://www.toymoban.com/news/detail-769417.html
到了这里,关于使用 Elasticsearch 检测抄袭 (一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!