考大家一个问题,如果想要把数据库的数据同步到别的地方,比如es,mongodb,大家会采用哪些方案呢? :::

-
定时扫描同步?
-
实时日志同步?
定时同步是一个很好的方案,比较简单,但是如果对实时要求比较高的话,定时同步就有点不合适了。今天给大家介绍一种实时同步方案,就是是使用flinkcdc 来读取数据库日志,并且写入到elasticsearch中。
1.什么是flinkcdc?
Flink CDC(Change Data Capture)是指通过 Apache Flink 实现的一种数据变化捕获技术。CDC 可以实时捕获数据库中的数据变化,如插入、更新、删除操作,并将这些变化数据流式地传输到其他系统或存储中。通过 Flink CDC,用户可以实时监控数据库中的数据变化,并将这些变化数据用于实时分析、ETL(Extract, Transform, Load)等应用场景。Flink CDC 通常用于构建实时数据管道,帮助用户实现实时数据同步和分析。


2.flinkcdc发展趋势?

目前在github 上大概有5k 的star,也有越来越多的人使用。

3.flinkcdc有什么优势?
说到实时同步,canal 是比较常用的方案
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。 这句介绍有几个关键字:增量日志,增量数据订阅和消费。

canal的把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
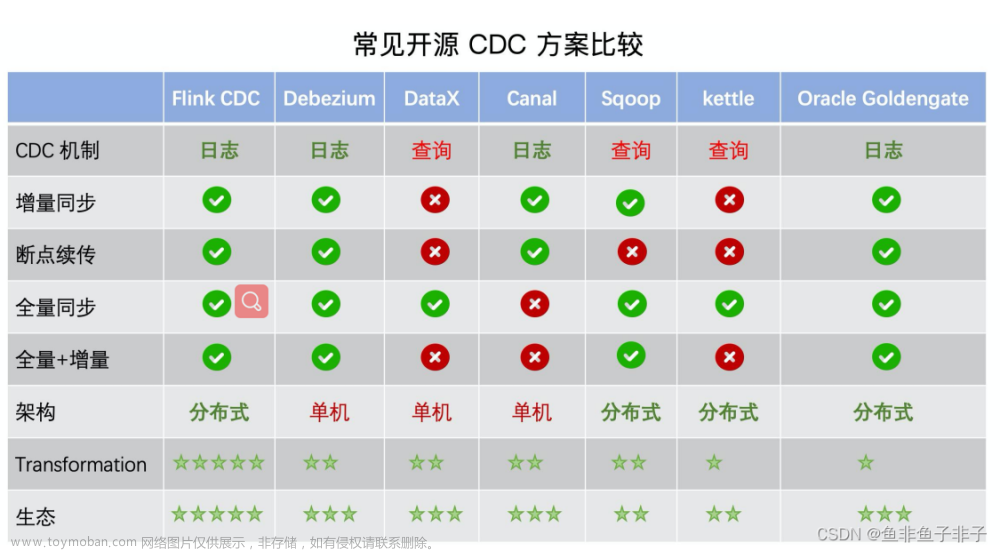
那么 flinkcdc 和canal 对比,有什么不同呢?

这是网上的一个对比。可以看到 flinkcdc 和canal 一样,也是通过读取数据库日志的方式做到实时同步的,这个和很多实时同步的工具原理相同,比如 ogg debezium 都是这样做的,flinkcdc 的优势是基于flink 这个强大的实时计算引擎,可以做到集群部署,高可用等等,并且社区活跃,支持的平台多,像 mysql oracle mongodb 主流数据库都是支持的。而canal只支持mysql。
还有一个优势,flinkcdc 是基于java实现的,背靠大数据这个大平台,解决方案也是比较多的。源码阅读修改起来也是比较方便的。
4.一个例子
光说不练假把式,简单的写一个把mysql 数据实时同步到es的例子,使用flinksql的方式,只需要简单的几行sql

依赖
flink-1.15.0
flink-sql-connector-elasticsearch7-1.15.0.jar
flink-sql-connector-mysql-cdc-2.2.1.jar
mysql 5.7
es 7.9.3
安装好flink 之后,把 flink-sql-connector-elasticsearch7-1.15.0.jar flink-sql-connector-mysql-cdc-2.2.1.jar 上传到 flink lib 目录 启动flink
./start-cluster.sh
打开flink sql 窗口
./start-cluster.sh
创建和mysql 关联的表
CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'products'
);
CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
创建和es 同步的表
CREATE TABLE enriched_orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
product_name STRING,
product_description STRING,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.91.134:9200',
'index' = 'enriched_orders'
);
创建读取mysql写入es任务
INSERT INTO enriched_orders
SELECT o.*, p.name, p.description
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id;
执行这个任务后,mysql 的数据就能实时同步至es了
当然数据源也是支持很多种,比如 oracle mongodb sqlserver 写入端也支持 es kafka hive 等等,看大家需要。想我们的业务场景,是先将mysql 数据同步到kafka,然后再消费kafka 消息,把数据写入到es, hive,starrocks 等等。并且使用了checkpoint 做为断点恢复的保障。
5.最后
附上一些涉及的到网址,方便大家查阅
flinkcdc 官网
flinkcdc github
flink 官网文章来源:https://www.toymoban.com/news/detail-769804.html
flink 文档文章来源地址https://www.toymoban.com/news/detail-769804.html
到了这里,关于FlinkCDC数据实时同步Mysql到ES的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!