文章来源:https://www.toymoban.com/news/detail-769982.html
文章来源:https://www.toymoban.com/news/detail-769982.html
import random
import string
from datetime import datetime
def generate_random_string(length=3):
characters = string.ascii_uppercase
return ''.join(random.choice(characters) for _ in range(length))
def generate_timestamped_string(separator='_'):
timestamp = datetime.now().strftime('%y%m%d') # %H%M%S
random_part = generate_random_string(length=3)
return random_part+separator+timestamp
timestamped_string = generate_timestamped_string()
print('【{0}】'.format(timestamped_string))【Talk is cheap】文章来源地址https://www.toymoban.com/news/detail-769982.html
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
warnings.filterwarnings("ignore")
%matplotlib inline
...
Index(['买家会员名', '买家实际支付积分', '买家实际支付金额', '买家应付货款', '买家应付邮费', '买家支付宝账号',
'买家支付积分', '买家服务费', '买家留言', '修改后的sku', '修改后的收货地址', '分阶段订单信息', '卖家服务费',
'发票抬头', '含应开票给个人的个人红包', '天猫卡券抵扣', '定金排名', '宝贝总数量', '宝贝标题 ', '宝贝种类 ',
'店铺Id', '店铺名称', '异常信息', '总金额', '打款商家金额', '支付单号', '支付详情', '收货人姓名',
'收货地址', '新零售交易类型', '新零售发货门店id', '新零售发货门店名称', '新零售导购门店id', '新零售导购门店名称',
'是否上传合同照片', '是否上传小票', '是否代付', '是否手机订单', '是否是O2O交易', '物流公司', '物流单号 ',
'特权订金订单id', '确认收货时间', '联系手机', '联系电话 ', '订单付款时间', '订单关闭原因', '订单创建时间',
'订单备注', '订单状态', '运送方式', '返点积分', '退款金额', '数据采集时间'],
...
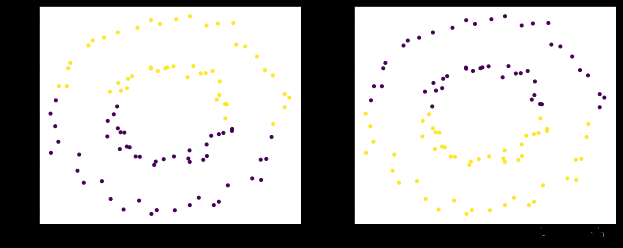
from sklearn.cluster import KMeans
# 将聚类结果添加到原始数据中
data['Cluster'] = labels
0 13015181676 55.86 1 0
1 13019108165 0.00 2 0
2 13020140119 95.76 2 0
3 13022508850 48.86 1 0
4 13026161372 268.00 1 0
# 计算RFM得分
rfm_table['R'] = rfm_table['Recency'].apply(rfm_score, args=('Recency', quantiles))
rfm_table['F'] = rfm_table['Frequency'].apply(rfm_score, args=('Frequency', quantiles))
rfm_table['M'] = rfm_table['Monetary'].apply(rfm_score, args=('Monetary', quantiles))
# 输出RFM分析结果
print(rfm_table)
top_customers[rfm_table['RFM']>10]
403109394@qq.com 2463 3 1206.0 4 4 4 12
1003673371@qq.com 2406 4 1474.0 4 4 4 12
13524685268 2306 5 804.0 4 4 4 12
794378248@qq.com 2425 3 763.5 4 4 4 12
13467712448 2453 3 670.0 4 4 4 12
... ... ... ... ... ... ... ...
313137525@qq.com 2249 7 2546.0 3 4 4 11
15976850599 2204 3 867.0 3 4 4 11
18580706707 2217 15 4020.0 3 4 4 11
18771060321 2445 2 368.0 4 3 4 11
15997278777 2478 2 1034.4 4 3 4 11到了这里,关于【BXZ_231228】使用Sklearn Kmeans及RFM对淘宝客户进行分类关怀的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!