什么是 OOMKilled Kubernetes 错误(Exit Code 137)
当 Kubernetes 集群中的容器超过其内存限制时,Kubernetes 系统可能会终止该容器并显示“OOMKilled”错误,这表明该进程由于内存不足而被终止。此错误的退出代码是 137。
如果遇到错误,Pod 的状态将显示“OOMKilled”,您可以使用以下命令查看该错误:
kubectl get podsOOMKiller 机制如何工作?
Out-Of-Memory Killer (OOMKiller) 是 Linux 内核(不是本机 Kubernetes)中的一种机制,负责通过杀死消耗过多内存的进程来防止系统内存不足。当系统内存不足时,内核会调用 OOMKiller 选择一个进程来杀死,以释放内存并保持系统运行。
OOMKiller 的工作方式是选择消耗最多内存且也被认为对系统操作最不重要的进程。此选择过程基于多个因素,包括进程的内存使用情况、优先级以及已运行的时间量。
一旦 OOMKiller 选择要终止的进程,它就会向该进程发送信号,要求其正常终止。如果进程没有响应该信号,内核将强制终止该进程并释放其内存。请注意,如果节点上的重启策略设置为“始终”,则由于内存问题而被杀死的 Pod 不一定会从节点中逐出,而是会尝试重新启动 Pod。
OOMKiller 是最后手段,仅当系统面临内存不足的危险时才会调用。虽然它可以帮助防止系统因内存耗尽而崩溃,但值得注意的是,终止进程可能会导致数据丢失和系统不稳定。因此,建议配置您的系统以避免 OOM 情况,例如,通过监视内存使用情况、设置资源限制以及优化应用程序中的内存使用情况。
在底层,Linux 内核为主机上运行的每个进程维护一个 oom_score。该分数越高,进程被杀死的机会就越大。另一个值称为 oom_score_adj,允许用户自定义 OOM 进程并定义何时应终止进程。
Kubernetes 在为 Pod 定义服务质量 (QoS) 类时使用 oom_score_adj 值。可以将三个 QoS 类别分配给 pod,每个类别都有一个匹配的 oom_score_adj 值:
-
Guaranteed: -997
-
BestEffort: 1000
-
Burstable: min(max(2, 1000 — (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999)
由于 Qos 值为Guaranteed 的 Pod 的值较低,为 -997,因此它们是内存不足的节点上最后被杀死的。BestEffort pod 是最先被杀死的,因为它们的值最高为 1000。
要查看 Pod 的 QoS 类别,请运行以下命令:
kubectl describe pod <POD_NAME> | grep "QoS Class"
kubectl describe pod busybox-busybox-854bfd7f4d-cwr8s -n dep-xxx-uat | grep "QoS Class"
QoS Class: Burstable查看Pod的oom_score:
kubectl exec -it <POD_NAME> /bin/bash
kubectl exec -it dep-redis-deployment-587bdcbc99-4bhsz -n dep-xxx-uat /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl kubectl exec [POD] -- [COMMAND] instead.
bash-5.0# cat /proc/1/oom_score
1312OOMKilled诊断
检查 pod 日志:诊断 OOMKilled 错误的第一步是检查 pod 日志,看看是否有任何指示内存问题的错误消息。描述命令的事件部分将给出进一步的确认以及错误发生的时间/日期。
kubectl describe pod <podname>State: Running
Started: Fri, 12 May 2023 11:14:13 +0200
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
...您还可以通过进入该pod运行的主机后台方式查询 pod 日志:
cat /var/log/pods/<podname>
cd /var/log/pods/dep-xxx-uat_dep-redis-deployment-587bdcbc99-b5pfc_e97776e7-7e4c-4632-b1e6-fc15dd88ed15
ls
dep-redis-deployment
cd dep-redis-deployment/
ls
0.log
ls -l
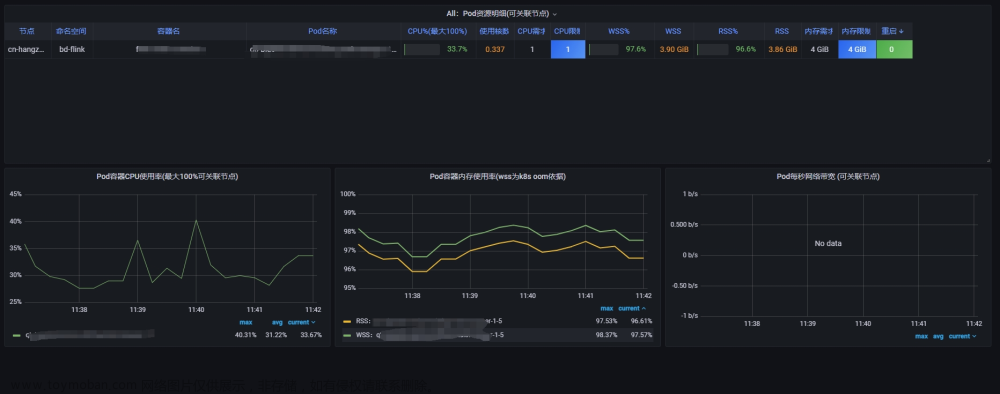
lrwxrwxrwx 1 root root 176 Oct 9 23:41 0.log -> /var/lib/containers/docker/containers/aa87d2a7abcf92acbe4a9a47119d0d806236c78de65519969f64e1b93f90bf50/aa87d2a7abcf92acbe4a9a47119d0d806236c78de65519969f64e1b93f90bf50-json.log监控内存使用情况:使用 Prometheus 或 Grafana 等 Kubernetes 监控工具来监控 Pod 和容器中的内存使用情况。这可以帮助您识别哪些容器消耗过多内存并触发 OOMKilled 错误。
使用内存分析器:使用内存分析器(例如 pprof)来识别内存泄漏或可能导致内存使用过多的低效代码。
Kubernetes OOMKilled 错误的常见原因及解决方法
1、已达到容器内存限制。这可能是由于在容器清单中指定的内存限制值上设置了不适当的值,这是允许容器使用的最大内存量。这也可能是由于应用程序的负载高于正常负载。解决方案是增加内存限制的值或调查负载增加的根本原因并进行修复。造成这种情况的常见原因包括大文件上传,因为上传大文件会消耗大量内存资源,尤其是当一个 Pod 中运行多个容器时,以及流量突然增加导致的高流量。
2、由于应用程序遇到内存泄漏,因此已达到容器内存限制。需要调试应用程序以解决内存泄漏的原因。
3、节点过度使用——这意味着 Pod 使用的总内存大于可用的节点总内存。通过扩展来增加节点可用的内存,或者将 Pod 移动到具有更多可用内存的节点。您还可以调整在过度使用的节点上运行的 Pod 的内存限制,使它们符合可用边界,请注意,您还应该注意内存请求设置,该设置指定 Pod 应使用的最小内存量。如果设置得太高,可能无法有效利用可用内存。在调整内存请求和限制时,请记住,当节点过度使用时,Kubernetes 将根据以下优先级顺序杀死 pod:
-
没有请求或限制的 Pod
-
有请求但没有限制的 Pod
-
使用超过其内存请求值(指定的最小内存)但低于其内存限制的 Pod文章来源:https://www.toymoban.com/news/detail-770120.html
-
使用超过内存限制的 Pod文章来源地址https://www.toymoban.com/news/detail-770120.html
到了这里,关于如何分析K8S中的OOMKilled问题(Exit Code 137)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!