k近邻算法主要思想
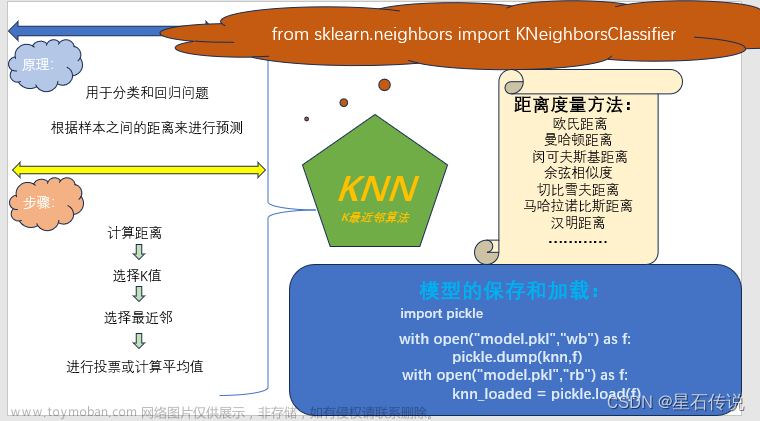
k近邻算法是一种基本的分类与回归方法,其主要思想是基于样本之间的距离进行分类或回归预测。即对未标记样本的类别,由距离其最近的k个邻居投票来决定属于哪个类别。具体而言,k近邻算法将新的样本点与训练数据集中的样本进行距离度量,并选择与该样本距离最近的k个训练样本作为参考。对于分类问题,k近邻算法通过统计这k个样本中各类别的数量来决定新样本所属的类别;对于回归问题,k近邻算法通过计算这k个样本的平均值或加权平均值来预测新样本的输出值。k近邻算法没有显式的训练过程,而是在预测时根据训练数据来进行实时计算。
kNN的原理
kNN的原理是:通过计算待标记样本和数据集中每个样本的距离,取距离最近的k个样本。待标记的样本所属类别就由这k个距离最近的样本投票产生。
k近邻算法(k-nearest neighbors,简称kNN)是一种基本的分类与回归方法。其原理可以概括为以下几个步骤:
-
训练阶段:将带有标签的训练样本集合作为输入。kNN算法不进行显式的训练过程,而是将这些样本保存起来以供后续的预测使用。
-
预测阶段:对于一个新的待预测样本,计算它与训练数据集中每个样本之间的距离。常用的距离度量方法包括欧氏距离、曼哈顿距离等。
-
选择最近邻:根据距离度量的结果,选择与待预测样本距离最近的k个训练样本作为参考。
-
分类或回归:对于分类问题,统计这k个样本中各类别的数量,并根据多数表决原则确定待预测样本所属的类别。对于回归问题,计算这k个样本的平均值或加权平均值,并作为待预测样本的输出值。
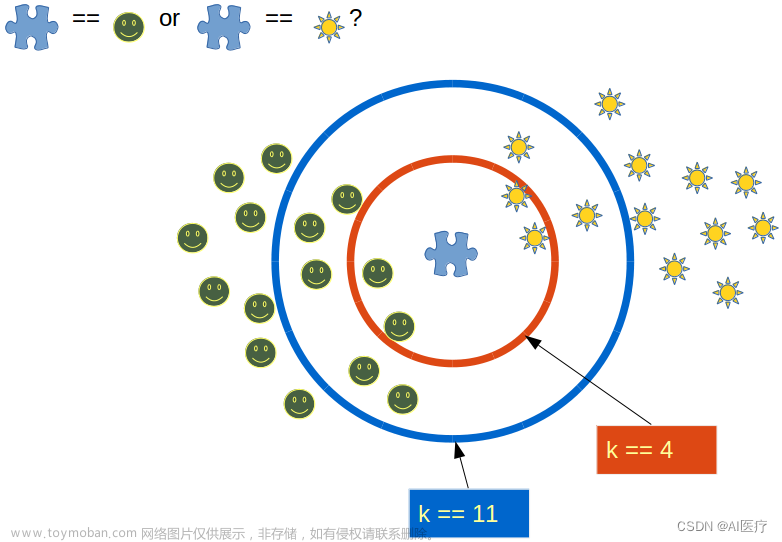
在kNN算法中,k的选择是一个重要的参数。较小的k值会使模型更加敏感和复杂,可能导致过拟合;而较大的k值会使模型更加平滑,可能导致欠拟合。因此,选择合适的k值是kNN算法中需要注意的问题。文章来源:https://www.toymoban.com/news/detail-770151.html
需要注意的是,k近邻算法属于一种懒惰学习(lazy learning)方法,因为它在预测阶段才进行计算,没有显式的训练过程。这也使得kNN算法对训练数据集中的噪声和冗余数据比较敏感,同时在处理大规模数据时可能会面临计算复杂度高的问题。文章来源地址https://www.toymoban.com/news/detail-770151.html
到了这里,关于k近邻算法原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!