简介
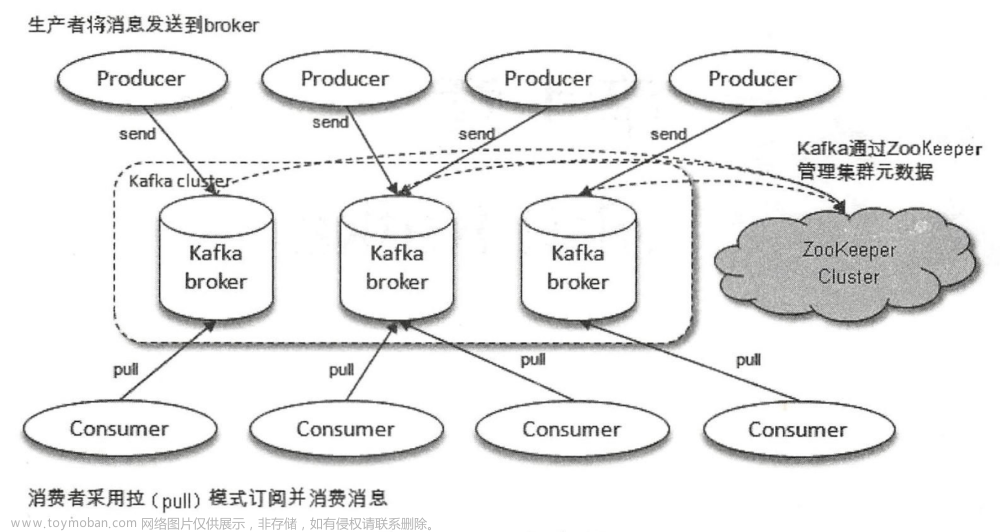
分布式,分区,多副本,zk协调的分布式消息系统
使用场景
日志收集 消息系统 用户活动跟踪 运营指标
对数据安全要求不高的场景
核心组成部分
broker topic producer consumer consumergroup partition
原理
通信基于tcp协议
很多集群信息记录在zk里保证自己的无状态,方便水平扩容
leader处理partition的读写请求,followers被动复制leader,不提供读写保证多副本与消费一致性
一个partition同一个时刻在一个consumer group中只能有一个consumer instance在消费
Controller
本身是broker
分区leader副本故障选新leader
分区isr集合变化通知broker更新元数据
topic增加分区数量,让新分区被其他节点感知
监听broker的变化
监听topic的变化
从zk获取topic, partition, broker信息,监听topic分区分配变化
更新集群元数据并同步到普通的broker中
启动broker再zk上创建/controller临时节点,成功的为Controller,挂掉重新选
Partition副本选leader机制
从isr列表选第一个broker作为leader
unclean.leader.election.enable 配置是否可以在isr以外的列表选
replica.lag.time.max.ms 配置与leader同步滞后的副本
消费者消费记录offset
consumer定期提交offset: _consumer_offset, key是consumerGroupId+topic+分区号,value是offset值,默认分配50个分区用于支持高并发
hash(consumerGroupId) % _consumer_offsets(主题的分区数)
消费者rebalance机制
触发时机:消费组里消费者数量变化,消费分区数变化,消费组订阅了更多的topic
rebalance过程中,消费者无法从kafka消费消息
range、round-robin、sticky
Rebalance过程
选择分组协调器 提交offset的分区leader所在的broker
加入消费组 协调器选第一个加入group的consumer为leader(消费协调器,负责制定分区方案)
sync group 分区方案发给分组协调器,分组协调器下发给各个consumer
producer发布消息机制
写入方式 push append patition 顺序写
路由
指定patition
未指定patition但指定key, 通过key的value hash选出
patition和key都未指定,轮询
写入流程
zk的"/brokers/.../state" 节点找到该 partition 的 leader
发送消息
leader写入本地log
followers从leader pull消息,写入本地log返回ack
leader收到所有isr的replica的ack,增加HW并向producer发送ack
LEO & HW
每个partition的log最后一条Message的位置
一个partition对应的ISR中最小的LEO(log-end-offset)作为HW
日志分段存储
一个分区的消息数据在一个文件夹下,topic+分区号命名,消息分段存储
segment file最大1G
.index .log .timeindex
每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件
每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件
数字表示日志段包含的起始offset
问题
消息丢失
min.insync.replicas配置备份个数
发送端 消费端
重复消费
发送端 消费端
乱序
发送端 消费端
消费者端接收到消息后将需要保证顺序消费的几条消费发到内存队列(可以搞多个),一个内存队列开启一个线程顺序处理
消息积压
修改消费端程序,让其将收到的消息转发到其他topic(可以设置很多分区),再启动多个消费者同时消费新主题的不同分区。
bug导致一直消费不成功,转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题
延时队列
消息回溯
一般情况分区数跟集群机器数量相当就差不多了,实际靠压测
吞吐量的数值和走势还会和磁盘、文件系统、 I/O调度策略等因素相关
消息传递保障
at most once ,acks=0
at least once ,acks=-1
exactly once ,at least once+消费幂等
kafka生产者的幂等
生产者加上参数 props.put(“enable.idempotence”, true)
PID和Sequence Number和消息绑定,相同不再接收
每个新的 Producer 在初始化的时候会被分配一个唯一的 PID
Producer 发送到每个 Partition 的数据都有对应的序列号,从0递增
文章来源地址https://www.toymoban.com/news/detail-770194.html文章来源:https://www.toymoban.com/news/detail-770194.html
到了这里,关于KafKa基本原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!