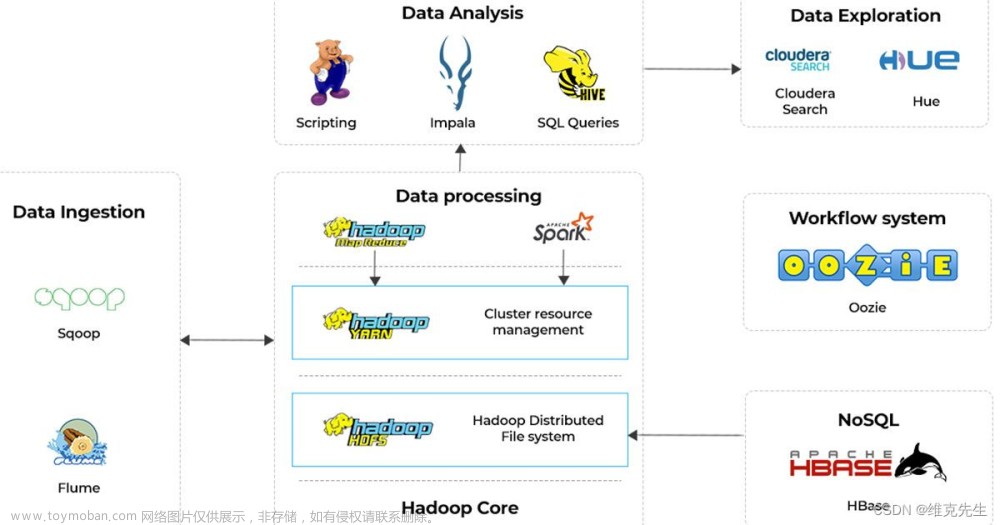
大数据处理架构Hadoop简介
- Hadoop是Apache软件基金会旗下一个开源分布式计算平台,为用户提供底层细节透明的基础框架。
- 经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包含了多个子项目,除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括ZooKeeper,HBase,Hive,Pig,Mahout,Sqoop,Flume,Ambari等。

Hadoop功能
它实现了MapReduce计算模型和分布式文件系统HDFS等功能,在业内得到广泛应用。 借助于Hadoop,程序员可以轻松编写分布式并行程序,将其运行于计算机集群上,完成海量数据的存储与处理分析。
Hadoop特性
- 高可靠性:Hadoop采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
- 高效性:作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效的处理PB级数据。
- 高可扩展性:Hadoop的设计目标是可以高效稳定的运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上。
- 高容错性:Hadoop采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
- 成本低:Hadoop采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的PC搭建Hadoop运行环境。
- 运行在Linux操作系统上:Hadoop是基于Java开发的,可以较好地运行在Linux系统上。
- 支持多种编程语言:Hadoop上的应用程序也可以使用其他语言编写,如C++。
Hadoop生态系统各组成部分
HDFS(分布式文件系统)
简介:HDFS是Hadoop项目两大核心组件之一,是针对谷歌文件系统(GFS)的开源实现。采用主从(Master/Slave)结构模型。HDFS集群包含一个名称节点(作为中心服务器,管理文件系统的命名空间及客户端对文件的访问)和若干个数据节点(一般是一个结点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作)。
优点:支持流数据读取和处理超大规模文件,并能够运行在由廉价的普通机器组成的集群上。HDFS在设计上采取了多种机制保证在硬件出错的环境中实现数据的完整性。
设计目标:
-
兼容廉价的硬件设备
HDFS设计了快速检测硬件故障和进行自动恢复的机制,可以实现持续监听、错误检查、容错处理和自动恢复,从而在硬件出错的情况下也能实现数据的完整性。 -
实现流数据读写
HDFS放松了一些POSIX的要求,从而能够以流失方式来访问文件系统数据。 -
大数据集
HDFS中的文件系统通常可以到达GB甚至TB级别,一个数百台服务器组成的集群都可以支持千万级别这样的文件。 -
简单的文件模型
HDFS采用了“一次写入,多次读取”的简单文件模型,文件一旦完成写入,关闭后就无法再次写入。只能被读取。 -
强大的跨平台兼容性
HDFS是采用Java实现的,具有很好的跨平台兼容性,支持JVM的机器都可以运行HDFS。
局限性:
- 不适合访问低延迟数据(Hbase是一个更好的选择)
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
MapReduce(分布式计算框架)
简介:MapReduce是谷歌的核心计算模型。MapReduce将复杂的、运行于大规模集群上的并行计算过程高度抽象为两个函数:Map和Reduce。适合用MapReduce来处理的数据集需要满足一个前提条件:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
核心思想:“分而治之”
不足
-
表达能力有限
计算都必须转化成Map和Reduce两种操作,但这并不适合所有情况,难以描述复杂的数据处理过程 -
磁盘IO开销大
每次执行都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入磁盘中,IO开销较大 -
延迟高
一次计算可嫩需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及IO开销,会产生较高延迟。并且,在前一个任务执行完成之前,其他任务无法开始,因此难以胜任复杂、多阶段的任务。
HBase(分布式数据库)
简介:
HBase是Google Bigtable(分布式存储系统)的开源实现,主要用来存储非结构化和半结构化的数据,是一个高可靠、高性能、面向列、可伸缩的分布式数据库。
目标:处理非常庞大的表
与其他部分的关系
- Hadoop MapReduce
利用Hadoop MapReduce处理HBase中的海量数据,实现高性能计算 - Zookeeper
利用Zookeeper作为协同服务,实现稳定服务和失败恢复 - HDFS
使用HDFS作为高可靠的底层数据存储系统,利用廉价集群提供海量数据存储能力 - Sqoop
Sqoop为HBase提供了高效、便捷的关系数据库管理系数据导入功能 - Pig和Hive
为HBase提供了高层语言支持
HBase数据模型
- 表:每个HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
- 行键:每个HBase表都由若干行组成,每个行由行键来标识
- 列族:一个HBase表被分组成为许多“列族”的集合,它是基本的访问控制单元
- 列限定符:列族里的数据通过列限定符(或列)来定位
- 单元格:在HBase表中,通过行键、列族和列限定符确定一个“单元格”(Cell)
- 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
HBase服务器集群
一个Master服务器:负责表和Region的管理工作
多个Region服务器:负责维护分配给自己的Region并响应用户的读写请求
Hive(数据仓库)
简介:
Hive是一个基于Hadoop的数据仓库工具,可对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。HIve定义了简单的类似SQL的查询语言——HiveQL,它与大部分SQL语法兼容。
Hive系统架构
Pig(一种流数据语言和运行环境)
Pig是一种流数据语言和运行环境,适合于使用Hadoop和MapReduce平台来查询大型半结构化数据集。Pig的出现大大简化了Hadoop常见的工作任务,它在MapReduce的基础上创建了更简单的过程语言抽象,为Hadoop应用程序提供了一种更加接近SQL的接口。采用Pig编写只需要一个简单的脚本在集群中自动并行处理与分发。
Mahout(Apache软件基金会旗下的一个开源项目)
功能:提供一些可扩展的机器学习领域经典算法的实现,包含许多实现,如聚类、分类、推荐过滤、频繁子项挖掘等。此外,通过使用Apache Hadoop库,Mahout可以有效地扩展到云中
目的:旨在帮助开发者更加方便快捷地创建智能应用程序
ZooKeeper(针对谷歌Chubby的一个开源实现)
功能:是高效和可靠的协同工作系统,提供分布式锁之类的基本服务(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等)用于构建分布式应用,减轻分布式应用程序承担的协调任务。
简介:使用Java编写,容易编程接入,使用了一个和文件树结构相似的数据模型,可以使用Java或者C来进行编程接入。
Flume
简介:Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统。
功能:Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理并写到各种数据接收方的能力。
Sqoop(SQL-to-Hadoop)
功能:主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。Sqoop是专门为大数据集设计的,支持增量更新,可以将新纪录添加到最近一次导出的数据源上,或者指定上次修改的时间戳。
Ambari(Apache Ambari)
是一种基于web的工具,支持Apache Hadoop集群的安装、部署、配置和管理。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoop等。文章来源:https://www.toymoban.com/news/detail-770298.html
YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。文章来源地址https://www.toymoban.com/news/detail-770298.html
到了这里,关于大数据导论——Hadoop生态系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!